Physics Context Builders: A Modular Framework for Physical Reasoning in Vision-Language Models
作者: Vahid Balazadeh, Mohammadmehdi Ataei, Hyunmin Cheong, Amir Hosein Khasahmadi, Rahul G. Krishnan
分类: cs.CV, cs.AI
发布日期: 2024-12-11 (更新: 2025-10-28)
💡 一句话要点
提出物理上下文构建器(PCBs),提升视觉-语言模型在物理推理任务上的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 物理推理 视觉-语言模型 上下文学习 模块化框架 Sim2Real迁移
📋 核心要点
- 现有视觉-语言模型在物理推理方面存在不足,无法有效利用学习到的知识进行物理行为预测。
- 论文提出物理上下文构建器(PCBs),通过生成详细的物理场景描述来增强大型VLMs的推理能力。
- 实验表明,PCBs在CLEVRER和Falling Tower数据集上显著提升了性能,并具有良好的Sim2Real迁移能力。
📝 摘要(中文)
视觉-语言模型(VLMs)在物理推理方面面临巨大挑战,主要原因是它们无法将学习到的知识转化为对物理行为的预测。虽然持续微调可以缓解这个问题,但对于大型模型来说成本高昂,且不适用于每个任务都重复执行。因此,需要创建模块化和可扩展的方法来教导VLMs进行物理推理。为此,我们引入了物理上下文构建器(PCBs),这是一个模块化框架,其中专门的小型VLMs经过微调以生成详细的物理场景描述。这些描述可以用作物理上下文,以增强大型VLMs的推理能力。PCBs实现了视觉感知与推理的分离,使我们能够分析它们对物理理解的相对贡献。我们在CLEVRER和Falling Tower(一个包含模拟和真实世界场景的稳定性检测数据集)上进行了实验,结果表明PCBs提供了显著的性能改进,在复杂的物理推理任务中平均准确率提高了高达13.8%。值得注意的是,PCBs还表现出强大的Sim2Real迁移能力,成功地从模拟训练数据泛化到真实世界场景。
🔬 方法详解
问题定义:视觉-语言模型在理解和预测物理世界的行为方面存在困难。现有的持续微调方法虽然有效,但计算成本高昂,且缺乏通用性,难以适应不同的物理推理任务。因此,需要一种更模块化、可扩展的方法来提升VLMs的物理推理能力。
核心思路:论文的核心思路是将视觉感知和物理推理解耦。通过训练专门的、较小的VLMs(即物理上下文构建器PCBs)来生成详细的物理场景描述,然后将这些描述作为上下文信息提供给大型VLMs,从而增强其推理能力。这种模块化的方法允许独立优化视觉感知和推理模块,并提高模型的泛化能力。
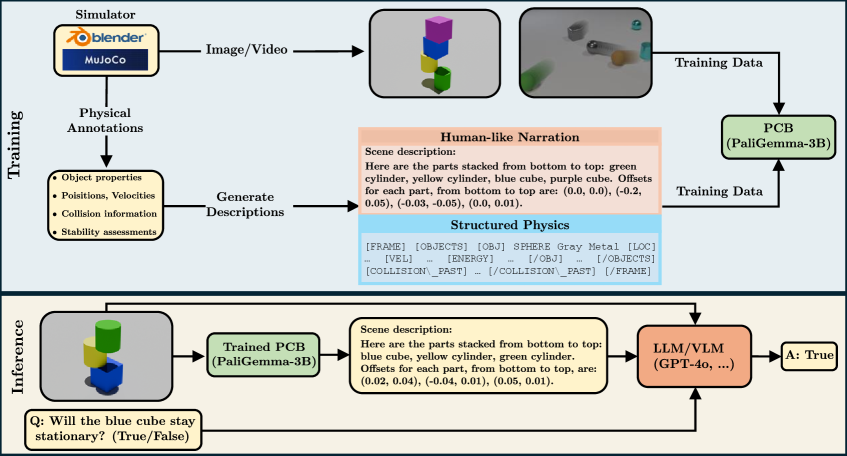
技术框架:整体框架包含两个主要阶段:1) 训练物理上下文构建器(PCBs):使用视觉信息作为输入,生成对场景中物体属性、关系和物理状态的详细描述。2) 利用PCBs生成的上下文增强大型VLMs的推理能力:将PCBs生成的描述与原始视觉输入一起输入到大型VLMs中,用于完成特定的物理推理任务。
关键创新:最重要的创新点在于提出了物理上下文构建器(PCBs)的概念,并将其作为一个独立的模块来学习物理场景的描述。这种模块化的设计使得模型可以更容易地学习和利用物理知识,并且可以灵活地应用于不同的物理推理任务。与直接微调大型VLMs相比,PCBs方法更高效、更具可扩展性。
关键设计:PCBs的具体实现可以采用不同的VLM架构,例如T5或GPT系列模型。关键在于训练PCBs生成高质量的物理场景描述,这可以通过设计合适的损失函数来实现,例如,可以使用交叉熵损失来衡量生成描述的准确性。此外,还可以使用数据增强技术来提高PCBs的鲁棒性和泛化能力。在Falling Tower数据集上,使用了真实世界的数据进行训练,以提高模型在真实场景中的性能。
🖼️ 关键图片

📊 实验亮点
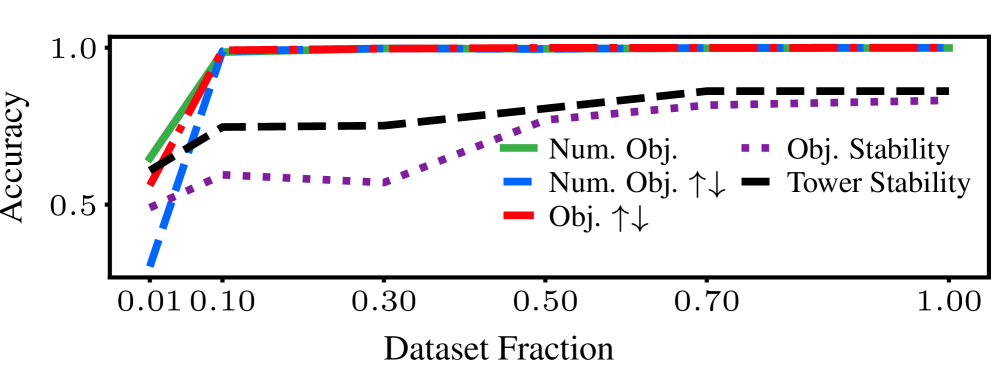
实验结果表明,PCBs在CLEVRER和Falling Tower数据集上均取得了显著的性能提升。在Falling Tower数据集上,PCBs将平均准确率提高了高达13.8%。更重要的是,PCBs表现出了强大的Sim2Real迁移能力,成功地从模拟训练数据泛化到真实世界场景,这表明该方法具有很强的实用价值。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能监控等领域。通过提升视觉-语言模型对物理世界的理解能力,可以使机器人在复杂环境中更好地进行决策和行动。例如,机器人可以利用该技术来判断物体的稳定性,从而避免碰撞或跌落,提高工作效率和安全性。未来,该技术还有望应用于虚拟现实和增强现实等领域,提供更逼真的物理交互体验。
📄 摘要(原文)
Physical reasoning remains a significant challenge for Vision-Language Models (VLMs). This limitation arises from an inability to translate learned knowledge into predictions about physical behavior. Although continual fine-tuning can mitigate this issue, it is expensive for large models and impractical to perform repeatedly for every task. This necessitates the creation of modular and scalable ways to teach VLMs about physical reasoning. To that end, we introduce Physics Context Builders (PCBs), a modular framework where specialized smaller VLMs are fine-tuned to generate detailed physical scene descriptions. These can be used as physical contexts to enhance the reasoning capabilities of larger VLMs. PCBs enable the separation of visual perception from reasoning, allowing us to analyze their relative contributions to physical understanding. We perform experiments on CLEVRER and on Falling Tower, a stability detection dataset with both simulated and real-world scenes, to demonstrate that PCBs provide substantial performance improvements, increasing average accuracy by up to 13.8% on complex physical reasoning tasks. Notably, PCBs also show strong Sim2Real transfer, successfully generalizing from simulated training data to real-world scenes.