FILA: Fine-Grained Vision Language Models
作者: Shiding Zhu, Wenhui Dong, Jun Song, Yingbo Wang, Yanan Guo, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2024-12-11 (更新: 2025-04-30)
备注: 9 pages, 4 figures, accepted to ICLR 2025 workshop
💡 一句话要点
FILA提出HyViLM,通过混合编码器和特征融合提升高分辨率图像的视觉语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 高分辨率图像 混合编码器 特征融合 多模态学习
📋 核心要点
- 现有MLLM通过裁剪高分辨率图像处理,但易造成物体截断和语义断裂。
- HyViLM设计混合编码器,融合局部子图像和全局视觉特征,保留图像上下文信息。
- 实验表明,HyViLM在多个VQA任务上显著优于现有模型,性能提升明显。
📝 摘要(中文)
本文提出了一种名为HyViLM的新型视觉语言模型,旨在提升多模态大语言模型(MLLM)处理高分辨率图像的能力。现有方法通常将高分辨率图像动态裁剪成小块,然后输入到预训练的视觉编码器中,但这种裁剪方式容易截断物体和连通区域,导致语义断裂。为了解决这个问题,HyViLM被设计成能够处理任意分辨率的图像,并在编码过程中保留整体上下文。具体来说,HyViLM包含一个混合编码器,它不仅编码单个子图像,还与详细的全局视觉特征交互,从而显著提高模型编码高分辨率图像的能力。此外,论文还提出了一种针对动态裁剪方法的最佳特征融合策略,有效利用了视觉编码器不同层的信息。实验结果表明,在相同设置下,HyViLM在十项任务中的九项上优于最先进的MLLM,尤其在TextVQA任务上性能提升了9.6%,在DocVQA任务上提升了6.9%。
🔬 方法详解
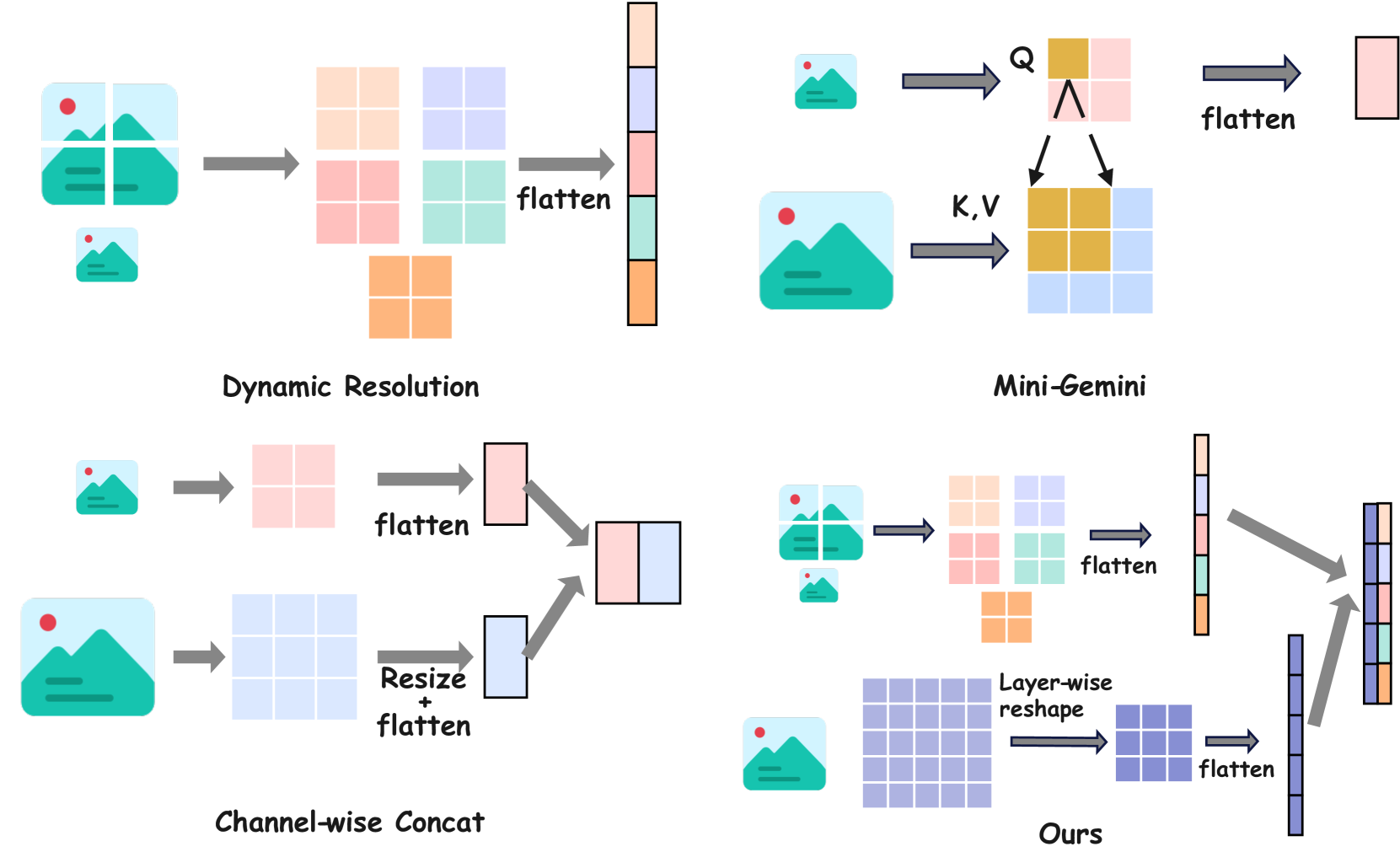
问题定义:现有视觉语言模型在处理高分辨率图像时,通常采用动态裁剪的方式,将图像分割成多个小块输入视觉编码器。这种方法的痛点在于,裁剪操作容易截断图像中的物体和连通区域,导致语义信息的丢失,影响模型对图像内容的理解。
核心思路:HyViLM的核心思路是设计一种混合编码器,既能处理局部子图像的信息,又能捕捉全局的视觉特征,从而在编码高分辨率图像时保留整体上下文。通过融合局部和全局的信息,模型可以更全面地理解图像内容,避免因裁剪造成的语义断裂。
技术框架:HyViLM的整体框架包含以下几个主要模块:1) 图像输入模块:接收任意分辨率的图像作为输入。2) 动态裁剪模块:将输入图像动态裁剪成多个子图像。3) 混合编码器:包含局部子图像编码器和全局视觉特征提取器,分别提取局部和全局特征。4) 特征融合模块:将局部和全局特征进行融合,得到最终的图像表示。5) 语言模型:接收融合后的图像表示和文本输入,进行多模态推理。
关键创新:HyViLM最重要的技术创新点在于混合编码器的设计。传统的视觉编码器通常只处理单个子图像,而HyViLM的混合编码器能够同时处理局部子图像和全局视觉特征,并通过交互机制将两者融合。这种设计使得模型能够更好地理解高分辨率图像的整体语义信息。
关键设计:在混合编码器中,局部子图像编码器可以使用预训练的视觉模型(如ViT),全局视觉特征提取器可以使用卷积神经网络(CNN)提取图像的低层特征。特征融合模块可以使用注意力机制,根据不同特征的重要性进行加权融合。此外,论文还提出了一种最佳特征融合策略,有效利用了视觉编码器不同层的信息。
🖼️ 关键图片


📊 实验亮点
HyViLM在多个视觉问答(VQA)任务上取得了显著的性能提升。在TextVQA任务上,HyViLM的性能提升了9.6%,在DocVQA任务上提升了6.9%。这些结果表明,HyViLM在处理高分辨率图像和理解复杂场景方面具有显著优势,优于现有的最先进的MLLM模型。
🎯 应用场景
HyViLM具有广泛的应用前景,包括但不限于:智能问答、文档理解、医学影像分析、遥感图像解译等领域。通过提升模型对高分辨率图像的理解能力,可以提高相关任务的准确性和效率。未来,HyViLM有望应用于更复杂的视觉语言任务,例如视频理解、机器人导航等。
📄 摘要(原文)
Recently, there has been growing interest in the capability of multimodal large language models (MLLMs) to process high-resolution images. A common approach currently involves dynamically cropping the original high-resolution image into smaller sub-images, which are then fed into a vision encoder that was pre-trained on lower-resolution images. However, this cropping approach often truncates objects and connected areas in the original image, causing semantic breaks. To address this limitation, we introduce HyViLM, designed to process images of any resolution while retaining the overall context during encoding. Specifically, we: (i) Design a new visual encoder called Hybrid Encoder that not only encodes individual sub-images but also interacts with detailed global visual features, significantly improving the model's ability to encode high-resolution images. (ii) Propose an optimal feature fusion strategy for the dynamic cropping approach, effectively leveraging information from different layers of the vision encoder. Compared with the state-of-the-art MLLMs under the same setting, our HyViLM outperforms existing MLLMs in nine out of ten tasks. Specifically, HyViLM achieves a 9.6% improvement in performance on the TextVQA task and a 6.9% enhancement on the DocVQA task.