RoboTron-Drive: All-in-One Large Multimodal Model for Autonomous Driving
作者: Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, Lin Ma
分类: cs.CV, cs.MM, cs.RO
发布日期: 2024-12-10 (更新: 2025-08-07)
备注: ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出RoboTron-Drive:用于自动驾驶的通用大型多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态模型 大型语言模型 课程学习 多任务学习 零样本迁移 感知 预测
📋 核心要点
- 现有自动驾驶方法侧重于单一数据集和特定任务,缺乏整体能力和泛化性。
- RoboTron-Drive通过课程预训练和多数据集微调,实现对多种视觉信号的理解和多任务处理。
- 在多个基准测试和零样本迁移实验中,RoboTron-Drive均取得了领先的性能。
📝 摘要(中文)
本文提出RoboTron-Drive,一个通用的大型多模态模型(LMM),旨在处理多样的数据输入,如图像和多视角视频,并执行广泛的自动驾驶(AD)任务,包括感知、预测和规划。该模型首先经过课程预训练,以处理不同的视觉信号并执行基本的视觉理解和感知任务。随后,通过增强和标准化各种AD数据集来微调模型,从而得到一个用于自动驾驶的all-in-one LMM。为了评估其通用能力和泛化能力,在六个公共基准上进行了评估,并在三个未见数据集上进行了零样本迁移,RoboTron-Drive在所有任务中均实现了最先进的性能。希望RoboTron-Drive能成为现实世界中自动驾驶的一个有前景的解决方案。
🔬 方法详解
问题定义:现有自动驾驶方法通常针对特定数据集和任务进行优化,导致模型泛化能力不足,难以适应真实世界中复杂多变的场景。此外,缺乏能够同时处理感知、预测和规划等多种任务的统一模型。
核心思路:RoboTron-Drive的核心思路是构建一个通用的、端到端的大型多模态模型,通过大规模数据训练,使其具备强大的视觉理解能力和多任务处理能力。通过课程学习和多数据集微调,提升模型的泛化性和鲁棒性。
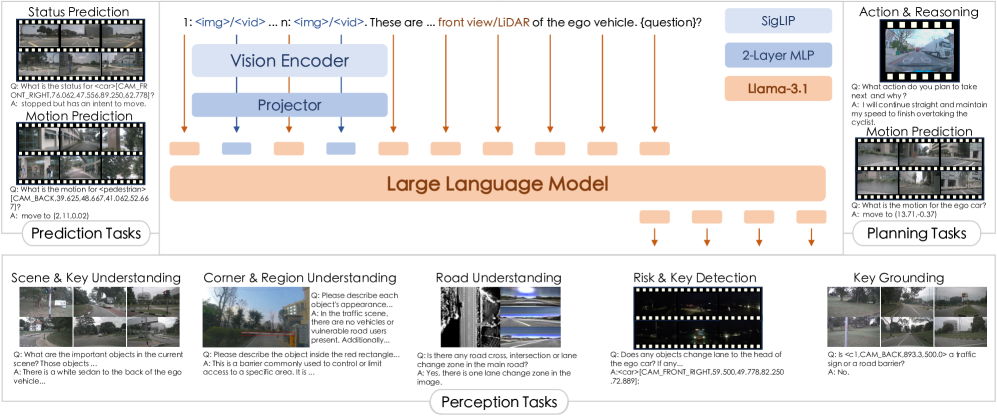
技术框架:RoboTron-Drive的整体框架包含以下几个主要阶段:1) 课程预训练:使用多样化的视觉数据进行预训练,提升模型对不同视觉信号的理解能力。2) 数据增强与标准化:对各种自动驾驶数据集进行增强和标准化处理,使其能够被统一的模型处理。3) 多任务微调:使用增强后的数据集对模型进行微调,使其能够同时执行感知、预测和规划等多种任务。
关键创新:RoboTron-Drive的关键创新在于其通用性和多任务处理能力。与以往专注于单一任务的模型不同,RoboTron-Drive能够处理多种数据输入,并执行多种自动驾驶任务,从而实现更全面的自动驾驶解决方案。此外,课程预训练和多数据集微调策略也显著提升了模型的泛化能力。
关键设计:具体的技术细节包括:1) 视觉编码器:采用Transformer结构,用于提取图像和视频中的视觉特征。2) 多模态融合模块:将视觉特征和文本信息进行融合,以便模型能够理解场景的语义信息。3) 任务特定头:针对不同的自动驾驶任务,设计不同的任务特定头,例如用于目标检测的检测头,用于轨迹预测的预测头等。4) 损失函数:采用多任务学习的损失函数,平衡不同任务之间的学习。
🖼️ 关键图片


📊 实验亮点
RoboTron-Drive在六个公共基准测试中取得了最先进的性能,并在三个未见数据集上实现了零样本迁移。具体而言,在目标检测、轨迹预测和路径规划等任务上,RoboTron-Drive的性能均优于现有方法,展现了其强大的泛化能力和多任务处理能力。
🎯 应用场景
RoboTron-Drive具有广泛的应用前景,可用于各种自动驾驶场景,包括城市道路、高速公路和越野环境。该模型能够提升自动驾驶系统的安全性、可靠性和智能化水平,加速自动驾驶技术的商业化落地。此外,该模型还可以应用于机器人、智能交通等领域。
📄 摘要(原文)
Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose RoboTron-Drive, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD datasets to finetune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on three unseen datasets, where RoboTron-Drive achieves state-of-the-art performance across all tasks. We hope RoboTron-Drive as a promising solution for AD in the real world. Project page with code: https://github.com/zhijian11/RoboTron-Drive.