Maya: An Instruction Finetuned Multilingual Multimodal Model
作者: Nahid Alam, Karthik Reddy Kanjula, Surya Guthikonda, Timothy Chung, Bala Krishna S Vegesna, Abhipsha Das, Anthony Susevski, Ryan Sze-Yin Chan, S M Iftekhar Uddin, Shayekh Bin Islam, Roshan Santhosh, Snegha A, Drishti Sharma, Chen Liu, Isha Chaturvedi, Genta Indra Winata, Ashvanth. S, Snehanshu Mukherjee, Alham Fikri Aji
分类: cs.CV, cs.CL
发布日期: 2024-12-10
🔗 代码/项目: GITHUB
💡 一句话要点
Maya:一种指令微调的多语言多模态模型,提升低资源语言和文化理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 多模态学习 视觉-语言模型 指令微调 低资源语言 文化理解 毒性过滤 开源模型
📋 核心要点
- 现有视觉-语言模型在低资源语言和文化理解方面存在不足,主要原因是缺乏高质量、多样化的训练数据。
- Maya通过构建多语言图像-文本数据集,并进行毒性分析和过滤,从而提升模型在多语言环境下的性能。
- 该研究发布了一个开源的多模态多语言模型,旨在增强视觉-语言任务中的文化和语言理解能力。
📝 摘要(中文)
大型视觉-语言模型(VLMs)在学术基准测试中取得了显著成果,但主要集中在广泛使用的语言上。当前VLMs在处理低资源语言和不同文化背景方面仍存在显著差距,这主要是由于缺乏高质量、多样化和安全审查的数据。因此,这些模型通常难以理解低资源语言和文化细微差别,并且可能存在有害内容。为了解决这些局限性,我们推出了Maya,一个开源的多模态多语言模型。我们的贡献有三方面:1) 基于LLaVA预训练数据集,构建了一个包含八种语言的多语言图像-文本预训练数据集;2) 对LLaVA数据集中的毒性进行了全面分析,并创建了一个跨八种语言的新型无毒版本;3) 构建了一个支持这些语言的多语言图像-文本模型,增强了视觉-语言任务中的文化和语言理解能力。
🔬 方法详解
问题定义:现有的大型视觉-语言模型(VLMs)在处理低资源语言和不同文化背景时表现不佳。主要痛点在于缺乏高质量、多样化且经过安全审查的多语言图像-文本数据,导致模型难以理解不同语言和文化背景下的细微差别,甚至可能产生有害内容。
核心思路:Maya的核心思路是通过构建一个多语言、无毒的图像-文本数据集,并在此基础上进行指令微调,从而提升模型在多语言环境下的视觉-语言理解能力。这种方法旨在弥合现有模型在低资源语言和文化理解方面的差距。
技术框架:Maya的整体框架包括三个主要阶段:1) 多语言图像-文本预训练数据集构建:基于LLaVA数据集,扩展到八种语言;2) 毒性分析与过滤:对LLaVA数据集进行毒性分析,并创建无毒版本;3) 多语言图像-文本模型训练:使用构建的数据集对模型进行指令微调,使其能够理解和生成多种语言的图像描述。
关键创新:Maya的关键创新在于其多语言、无毒的数据集构建方法。通过对现有数据集进行毒性分析和过滤,并扩展到多种低资源语言,Maya能够训练出更加安全和文化敏感的视觉-语言模型。此外,开源发布也促进了该领域的研究和发展。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但可以推断,Maya使用了标准的指令微调方法,并可能针对多语言环境进行了一些优化。数据集的构建和毒性过滤是其关键设计。
🖼️ 关键图片

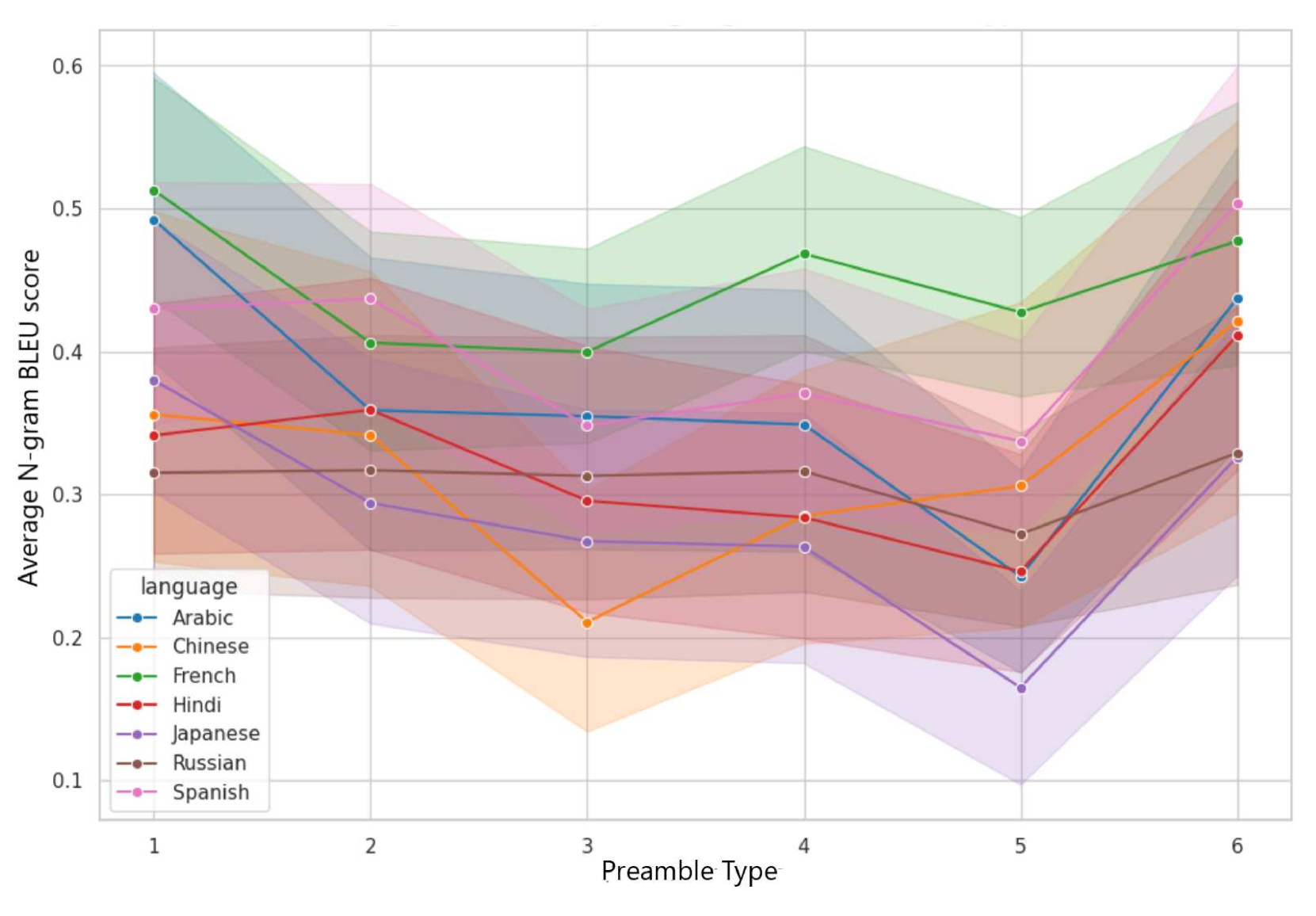
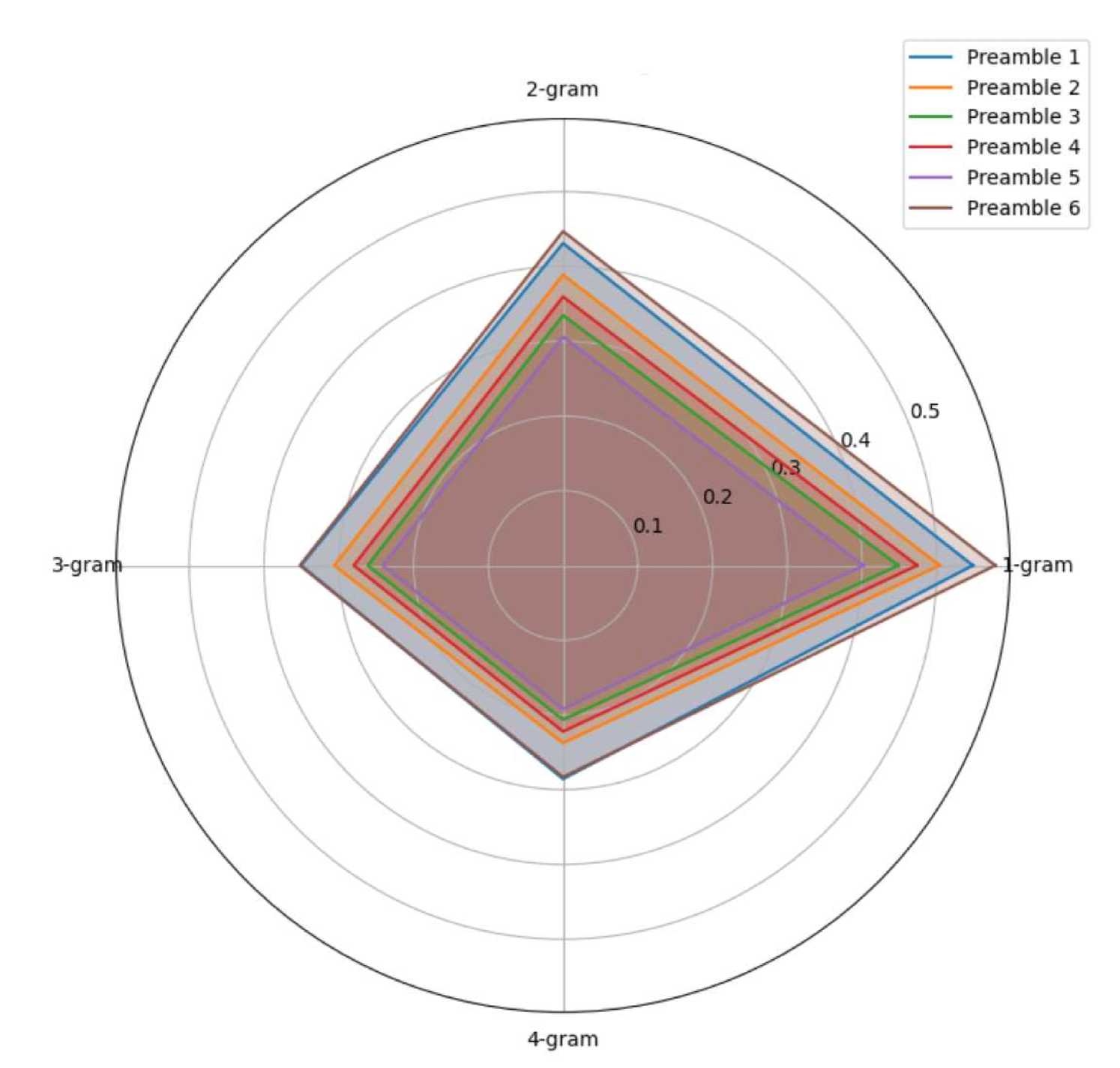
📊 实验亮点
该研究的主要亮点在于构建了一个多语言、无毒的图像-文本数据集,并基于此训练了一个开源的多模态多语言模型Maya。虽然论文摘要中没有提供具体的性能数据,但强调了Maya在增强文化和语言理解能力方面的潜力,并开源了代码,为后续研究提供了便利。
🎯 应用场景
Maya的应用场景广泛,包括多语言图像搜索、跨文化内容理解、多语言辅助教育、以及面向全球用户的智能助手等。该研究有助于弥合语言和文化差异,促进全球范围内的信息交流和知识共享,并为构建更加公平和包容的人工智能系统奠定基础。
📄 摘要(原文)
The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.