GVDepth: Zero-Shot Monocular Depth Estimation for Ground Vehicles based on Probabilistic Cue Fusion
作者: Karlo Koledić, Luka Petrović, Ivan Marković, Ivan Petrović
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-12-08 (更新: 2025-09-25)
备注: ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
GVDepth:面向地面车辆的零样本单目深度估计,基于概率线索融合
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 零样本学习 自动驾驶 概率融合 规范表示
📋 核心要点
- 单目深度估计泛化性差,受限于相机参数与深度信息的耦合,尤其在自动驾驶等固定相机设置场景下。
- 利用相机与地面的固定关系,通过物体垂直位置进行深度回归,并提出规范表示解耦深度与相机参数。
- 提出一种新颖架构,自适应且概率性地融合物体大小和垂直位置线索,提升零样本深度估计精度。
📝 摘要(中文)
由于单目深度估计的病态性,以及相机参数与深度之间的纠缠,使得度量单目深度估计的泛化成为一项重大挑战,这阻碍了多数据集训练和零样本精度。在自动驾驶车辆和移动机器人中,由于数据采集使用固定的相机设置,几何多样性受限,这个问题尤为突出。然而,这种背景也提供了一个机会:相机与地面之间的固定关系施加了额外的透视几何约束,从而可以通过物体在图像中的垂直位置进行深度回归。然而,这种线索非常容易过拟合,因此我们提出了一种新的规范表示,该表示保持了不同相机设置之间的一致性,有效地将深度与特定参数分离,并提高了跨数据集的泛化能力。我们还提出了一种新的架构,该架构自适应地、概率性地融合通过物体大小和垂直图像位置线索估计的深度。全面的评估表明,该方法在五个自动驾驶数据集上有效,实现了对不同分辨率、宽高比和相机设置的精确度量深度估计。值得注意的是,尽管只在一个具有单相机设置的数据集上进行训练,但我们实现了与现有零样本方法相当的精度。
🔬 方法详解
问题定义:论文旨在解决单目深度估计在零样本场景下的泛化性问题,尤其是在自动驾驶等地面车辆应用中。现有方法受限于相机参数与深度信息的强耦合,导致模型难以跨数据集泛化。此外,仅依赖单一视觉线索(如物体大小)容易过拟合特定数据集的偏差。
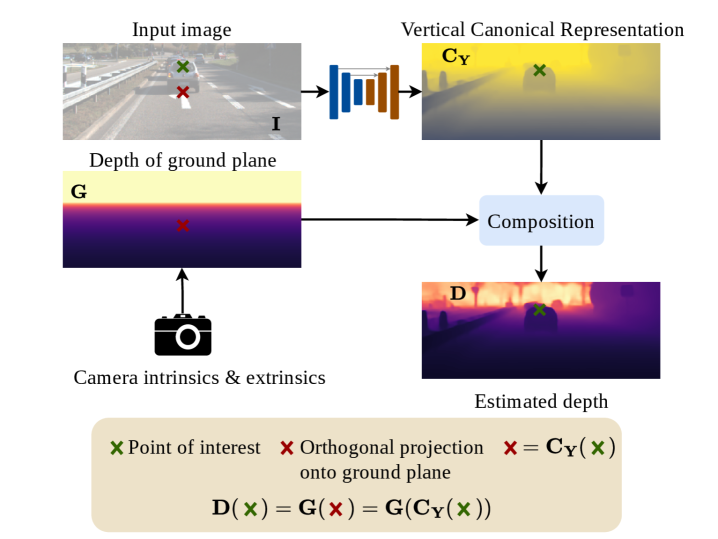
核心思路:论文的核心思路是利用地面车辆场景中相机与地面的固定几何关系,将物体在图像中的垂直位置作为一种有效的深度线索。为了解决垂直位置线索的过拟合问题,论文提出了一种规范表示,将深度信息从具体的相机参数中解耦出来,从而提高模型的泛化能力。此外,论文还设计了一种概率融合机制,将物体大小和垂直位置两种线索进行自适应融合,以提高深度估计的鲁棒性。
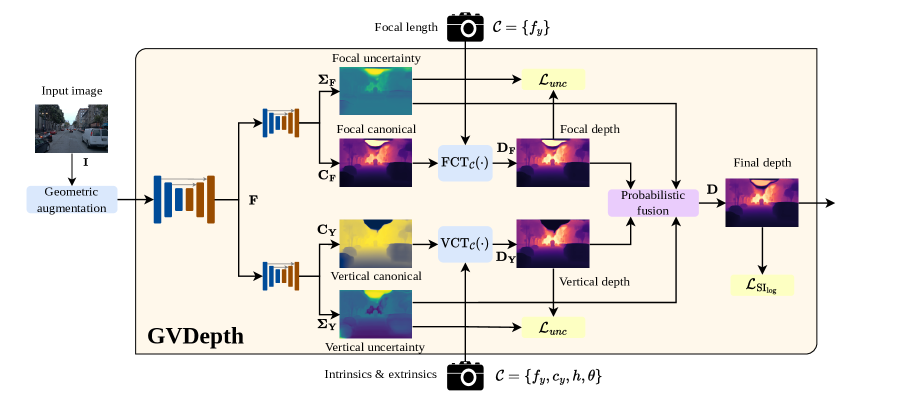
技术框架:GVDepth的整体架构包含以下几个主要模块:1) 特征提取模块:用于提取输入图像的视觉特征。2) 垂直位置深度估计模块:利用物体在图像中的垂直位置信息,通过规范表示进行深度估计。3) 物体大小深度估计模块:利用物体的大小信息进行深度估计。4) 概率融合模块:根据每个线索的置信度,自适应地融合垂直位置和物体大小两种深度估计结果。最终输出融合后的深度图。
关键创新:论文的关键创新在于:1) 提出了规范表示,有效地解耦了深度信息与相机参数,提高了模型的泛化能力。2) 设计了一种概率融合机制,能够自适应地融合不同的深度线索,提高了深度估计的鲁棒性。3) 针对地面车辆场景,充分利用了相机与地面的几何关系,将物体垂直位置作为一种有效的深度线索。
关键设计:规范表示的具体实现方式未知,但其目标是建立一个与相机参数无关的深度表示。概率融合模块可能使用了注意力机制或类似的加权方法,根据每个线索的置信度动态调整其权重。损失函数的设计可能考虑了深度估计的精度和一致性,具体形式未知。
🖼️ 关键图片

📊 实验亮点
GVDepth在五个自动驾驶数据集上进行了评估,结果表明,即使仅在一个数据集上进行训练,也能在其他数据集上实现与现有零样本方法相当的精度。该方法对不同的分辨率、宽高比和相机设置具有良好的适应性,证明了其优越的泛化能力。具体性能数据未知。
🎯 应用场景
该研究成果可应用于自动驾驶、移动机器人等领域,提升车辆在未知环境下的感知能力。精确的深度估计有助于车辆进行路径规划、障碍物检测和避障,提高行驶安全性。此外,该方法无需目标数据集的训练数据,降低了部署成本,加速了技术落地。
📄 摘要(原文)
Generalizing metric monocular depth estimation presents a significant challenge due to its ill-posed nature, while the entanglement between camera parameters and depth amplifies issues further, hindering multi-dataset training and zero-shot accuracy. This challenge is particularly evident in autonomous vehicles and mobile robotics, where data is collected with fixed camera setups, limiting the geometric diversity. Yet, this context also presents an opportunity: the fixed relationship between the camera and the ground plane imposes additional perspective geometry constraints, enabling depth regression via vertical image positions of objects. However, this cue is highly susceptible to overfitting, thus we propose a novel canonical representation that maintains consistency across varied camera setups, effectively disentangling depth from specific parameters and enhancing generalization across datasets. We also propose a novel architecture that adaptively and probabilistically fuses depths estimated via object size and vertical image position cues. A comprehensive evaluation demonstrates the effectiveness of the proposed approach on five autonomous driving datasets, achieving accurate metric depth estimation for varying resolutions, aspect ratios and camera setups. Notably, we achieve comparable accuracy to existing zero-shot methods, despite training on a single dataset with a single-camera setup. Project website: https://unizgfer-lamor.github.io/gvdepth/