Segment-Level Road Obstacle Detection Using Visual Foundation Model Priors and Likelihood Ratios
作者: Youssef Shoeb, Nazir Nayal, Azarm Nowzad, Fatma Güney, Hanno Gottschalk
分类: cs.CV
发布日期: 2024-12-07 (更新: 2025-03-02)
备注: 10 pages, 4 figures, and 1 table, to be published in VISAPP 2025
💡 一句话要点
提出基于视觉基础模型先验和似然比的分割级道路障碍物检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 道路障碍物检测 视觉基础模型 分割级特征 似然比 自动驾驶 语义分割 目标检测
📋 核心要点
- 现有道路障碍物检测方法依赖逐像素分类,易受阈值选择影响,导致预测碎片化和误报。
- 该论文提出一种基于视觉基础模型和似然比的分割级方法,直接预测道路障碍物,无需阈值。
- 实验表明,该方法在RoadObstacle和LostAndFound数据集上取得了state-of-the-art的性能,减少了误报。
📝 摘要(中文)
道路障碍物检测对于自动驾驶车辆在动态和复杂的交通环境中安全导航至关重要。现有的道路障碍物检测方法通常为每个像素分配一个分数,并应用阈值来生成最终预测。然而,选择合适的阈值具有挑战性,并且逐像素分类方法经常导致碎片化的预测,产生大量误报。本文提出了一种新颖的方法,该方法利用视觉基础模型的分割级特征和似然比来直接预测道路障碍物。通过关注分割而不是单个像素,我们的方法提高了检测精度,减少了误报,并提供了对场景变化的更强鲁棒性。我们在RoadObstacle和LostAndFound数据集上将我们的方法与现有方法进行了基准测试,在不需要预定义阈值的情况下实现了最先进的性能。
🔬 方法详解
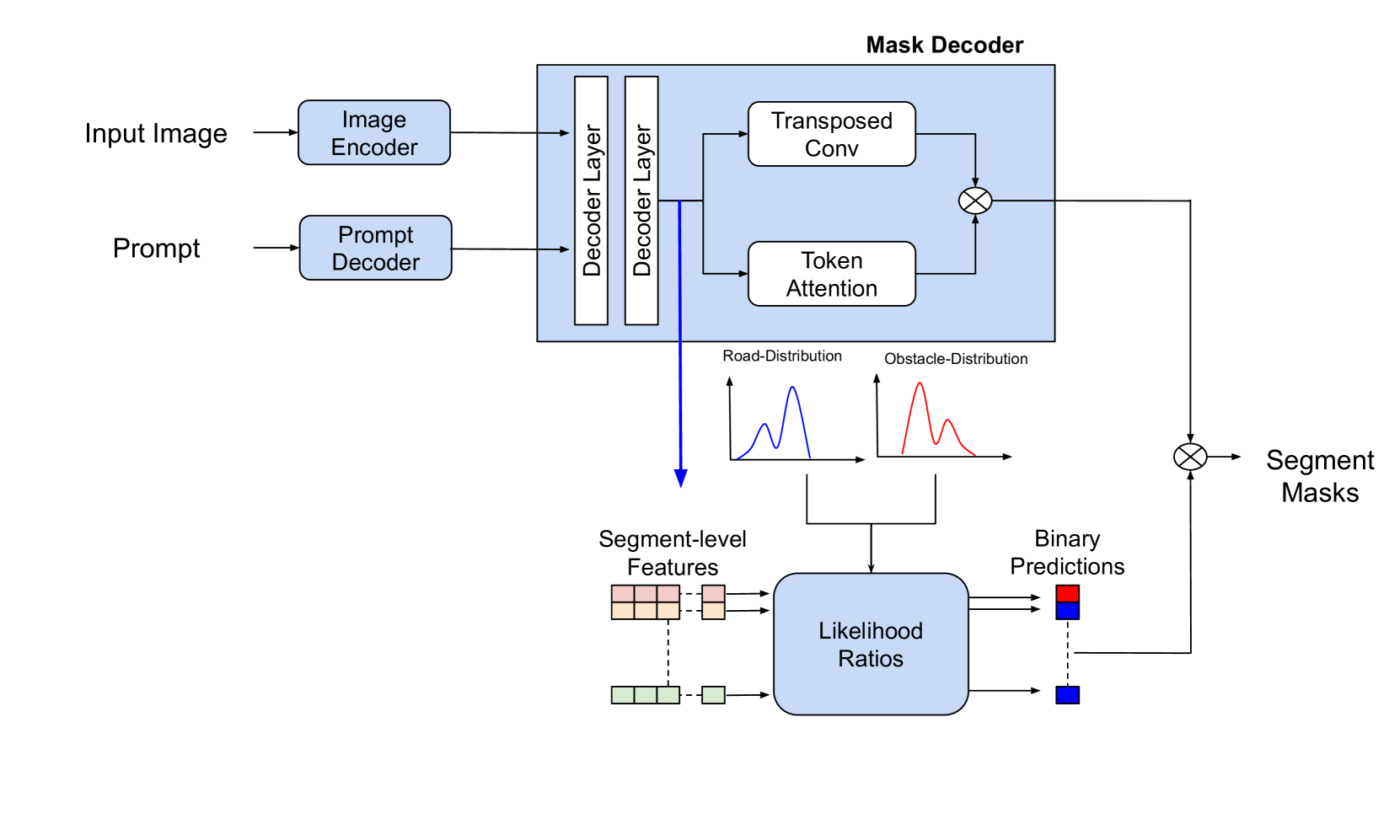
问题定义:现有道路障碍物检测方法主要基于逐像素分类,这种方法有两个主要痛点:一是需要手动设定阈值来区分障碍物和非障碍物,而阈值的选择对最终结果影响很大;二是逐像素分类容易产生碎片化的预测结果,导致大量的误报,降低了检测的准确性和鲁棒性。
核心思路:该论文的核心思路是将检测粒度从像素级别提升到分割级别。通过利用视觉基础模型提取图像的分割信息,并结合似然比来判断每个分割区域是否包含道路障碍物。这种方法避免了逐像素分类的阈值选择问题,并且能够利用分割区域的上下文信息,减少碎片化预测和误报。
技术框架:该方法的整体框架可以分为以下几个阶段:1. 图像分割:使用视觉基础模型(具体模型未知)对输入图像进行分割,得到一系列分割区域。2. 特征提取:提取每个分割区域的特征,这些特征可能包括颜色、纹理、形状等视觉特征,以及来自视觉基础模型的语义特征。3. 似然比计算:计算每个分割区域包含道路障碍物的似然比,似然比反映了该区域属于障碍物的概率与不属于障碍物的概率之比。4. 障碍物预测:根据似然比的大小,判断每个分割区域是否包含道路障碍物。
关键创新:该方法最重要的创新点在于将分割级别的特征引入到道路障碍物检测中,并结合似然比进行判断。与传统的逐像素分类方法相比,该方法能够更好地利用图像的上下文信息,减少误报,提高检测的准确性和鲁棒性。此外,该方法避免了手动选择阈值的需求,降低了人工干预。
关键设计:论文中关于视觉基础模型的选择、特征提取的具体方法、似然比的计算方式以及如何将似然比转化为最终的障碍物预测结果等关键设计细节未知。损失函数和网络结构等信息也未知。
🖼️ 关键图片


📊 实验亮点
该方法在RoadObstacle和LostAndFound数据集上取得了state-of-the-art的性能,无需预定义阈值。具体性能提升幅度未知,但摘要强调了检测精度提升和误报减少。实验结果表明,该方法在处理场景变化时具有更强的鲁棒性。
🎯 应用场景
该研究成果可应用于自动驾驶、高级驾驶辅助系统(ADAS)、机器人导航等领域。通过提高道路障碍物检测的准确性和鲁棒性,可以增强自动驾驶车辆在复杂交通环境中的安全性,减少交通事故的发生。此外,该方法还可以应用于智能交通管理系统,用于实时监测道路状况,提高交通效率。
📄 摘要(原文)
Detecting road obstacles is essential for autonomous vehicles to navigate dynamic and complex traffic environments safely. Current road obstacle detection methods typically assign a score to each pixel and apply a threshold to generate final predictions. However, selecting an appropriate threshold is challenging, and the per-pixel classification approach often leads to fragmented predictions with numerous false positives. In this work, we propose a novel method that leverages segment-level features from visual foundation models and likelihood ratios to predict road obstacles directly. By focusing on segments rather than individual pixels, our approach enhances detection accuracy, reduces false positives, and offers increased robustness to scene variability. We benchmark our approach against existing methods on the RoadObstacle and LostAndFound datasets, achieving state-of-the-art performance without needing a predefined threshold.