Street Gaussians without 3D Object Tracker
作者: Ruida Zhang, Chengxi Li, Chenyangguang Zhang, Xingyu Liu, Haili Yuan, Yanyan Li, Xiangyang Ji, Gim Hee Lee
分类: cs.CV
发布日期: 2024-12-07 (更新: 2025-08-31)
备注: Accepted by ICCV 2025, website: https://lolrudy.github.io/No3DTrackSG/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Street Gaussians,无需3D物体追踪器即可实现驾驶场景下的真实场景重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 驾驶场景重建 动态场景重建 2D深度追踪 3D物体融合 运动学习 隐式特征空间 自动驾驶 场景理解
📋 核心要点
- 现有驾驶场景重建方法依赖人工标注或泛化性不足的3D追踪器,难以应对真实场景中快速移动物体的挑战。
- 论文提出利用2D深度追踪器的关联信息,结合3D物体融合策略,构建稳定的物体追踪模块,无需3D追踪器。
- 通过隐式特征空间的运动学习策略,自主纠正轨迹误差并恢复遗漏检测,实验结果优于现有方法。
📝 摘要(中文)
在驾驶场景中,由于快速移动的物体,真实场景重建面临着巨大的挑战。现有方法大多依赖于人工标注的物体姿态,以便在规范空间中重建动态物体,并在渲染过程中根据这些姿态移动它们。虽然有些方法尝试使用3D物体追踪器来替代手动标注,但由于缺乏大规模3D数据集,3D追踪器的泛化能力有限,导致在真实场景中的重建效果不佳。相比之下,2D基础模型表现出强大的泛化能力。为了消除对3D追踪器的依赖,并增强在不同环境中的鲁棒性,我们提出了一种稳定的物体追踪模块,该模块利用来自2D深度追踪器的关联信息,并结合3D物体融合策略。为了解决不可避免的追踪错误,我们进一步在隐式特征空间中引入了一种运动学习策略,该策略能够自主地纠正轨迹误差并恢复遗漏的检测结果。在Waymo-NOTR和KITTI上的实验结果表明,我们的方法优于现有方法。代码将在https://lolrudy.github.io/No3DTrackSG/上发布。
🔬 方法详解
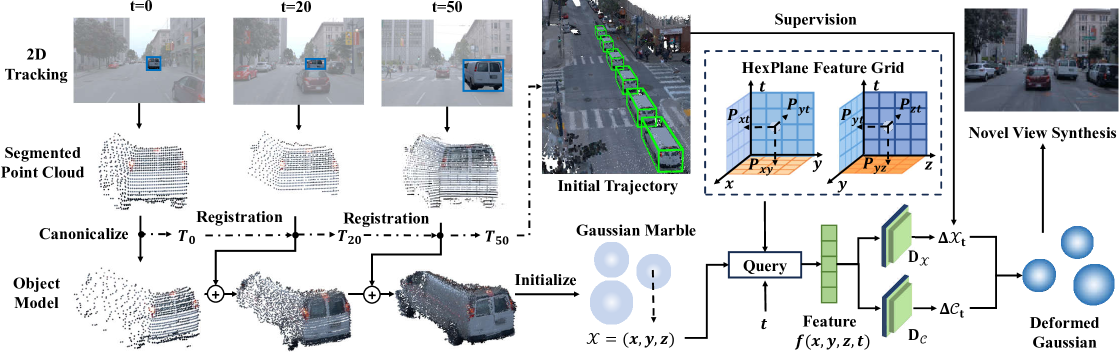
问题定义:现有方法在驾驶场景重建中,需要依赖人工标注的物体姿态或者3D物体追踪器。人工标注成本高昂,而3D物体追踪器由于缺乏大规模3D数据集的训练,泛化能力不足,导致在真实场景下的重建效果不佳。因此,如何摆脱对3D物体追踪器的依赖,提升重建的鲁棒性和泛化性,是本文要解决的核心问题。
核心思路:论文的核心思路是利用2D深度追踪器强大的泛化能力,结合3D物体融合策略,构建一个稳定的物体追踪模块,从而避免对3D物体追踪器的依赖。同时,为了解决2D追踪器可能出现的错误,论文进一步提出了一个隐式特征空间的运动学习策略,用于自主纠正轨迹误差和恢复遗漏的检测结果。
技术框架:整体框架包含以下几个主要模块:1) 2D深度追踪模块,用于提供2D物体之间的关联信息;2) 3D物体融合模块,将2D关联信息融合到3D空间中,构建稳定的物体追踪;3) 隐式特征空间运动学习模块,用于纠正轨迹误差和恢复遗漏的检测结果。整个流程首先利用2D追踪器获取物体关联,然后进行3D融合,最后通过运动学习进行优化。
关键创新:论文最重要的创新点在于提出了一个无需3D物体追踪器的驾驶场景重建方法。该方法通过利用2D深度追踪器的泛化能力和隐式特征空间的运动学习策略,有效地解决了现有方法对3D物体追踪器的依赖问题,提高了重建的鲁棒性和泛化性。
关键设计:论文的关键设计包括:1) 2D深度追踪器的选择,需要选择具有良好泛化能力的追踪器;2) 3D物体融合策略,需要设计合适的融合方式,将2D关联信息有效地融入到3D空间中;3) 隐式特征空间的构建,需要选择合适的特征表示方式,以便进行有效的运动学习;4) 运动学习策略的设计,需要设计合适的损失函数,以便自主地纠正轨迹误差和恢复遗漏的检测结果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Waymo-NOTR和KITTI数据集上均优于现有方法。具体而言,该方法在重建精度和鲁棒性方面均取得了显著提升,尤其是在处理快速移动物体和复杂场景时,表现出更强的优势。与依赖3D追踪器的方法相比,该方法在泛化能力方面也更具优势。
🎯 应用场景
该研究成果可应用于自动驾驶、增强现实、虚拟现实等领域。在自动驾驶中,可以提高环境感知的准确性和鲁棒性,从而提升驾驶安全性。在增强现实和虚拟现实中,可以实现更逼真的动态场景重建,提升用户体验。未来,该技术有望进一步推广到更广泛的动态场景重建任务中。
📄 摘要(原文)
Realistic scene reconstruction in driving scenarios poses significant challenges due to fast-moving objects. Most existing methods rely on labor-intensive manual labeling of object poses to reconstruct dynamic objects in canonical space and move them based on these poses during rendering. While some approaches attempt to use 3D object trackers to replace manual annotations, the limited generalization of 3D trackers -- caused by the scarcity of large-scale 3D datasets -- results in inferior reconstructions in real-world settings. In contrast, 2D foundation models demonstrate strong generalization capabilities. To eliminate the reliance on 3D trackers and enhance robustness across diverse environments, we propose a stable object tracking module by leveraging associations from 2D deep trackers within a 3D object fusion strategy. We address inevitable tracking errors by further introducing a motion learning strategy in an implicit feature space that autonomously corrects trajectory errors and recovers missed detections. Experimental results on Waymo-NOTR and KITTI show that our method outperforms existing approaches. Our code will be released on https://lolrudy.github.io/No3DTrackSG/.