Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
作者: Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yiming Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, Jiaye Ge, Kai Chen, Kaipeng Zhang, Limin Wang, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang
分类: cs.CV
发布日期: 2024-12-06 (更新: 2025-09-26)
备注: Technical Report
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
InternVL 2.5:通过模型、数据和测试时扩展,突破开源多模态模型性能边界
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 模型缩放 数据增强 测试时扩展 思维链推理 开源模型 视觉语言模型
📋 核心要点
- 现有开源多模态模型在复杂推理、多模态幻觉等方面存在不足,难以达到商业模型的性能水平。
- InternVL 2.5通过模型、数据和测试时扩展,系统性地提升了多模态模型的性能,使其更具竞争力。
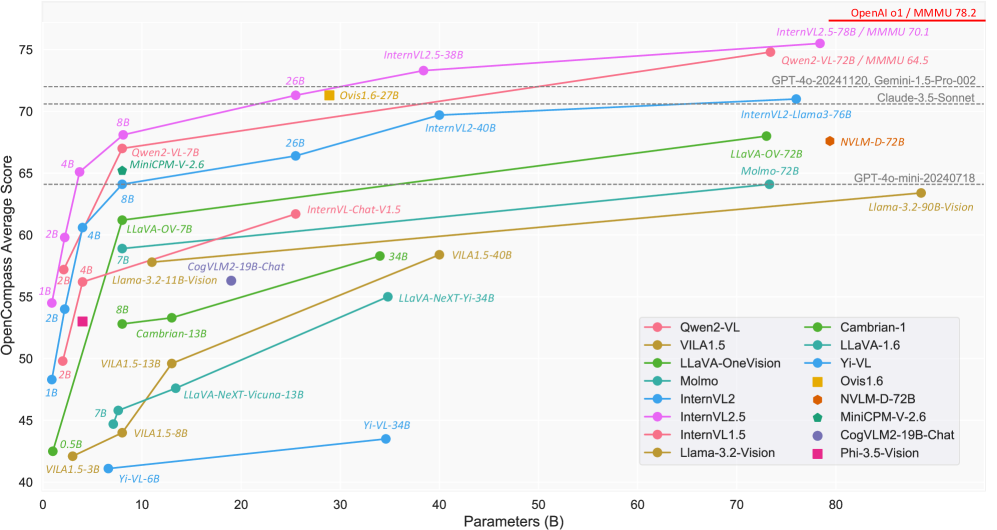
- 实验结果表明,InternVL 2.5在多个基准测试中表现出色,并在MMMU基准上首次突破70%,性能媲美GPT-4o等商业模型。
📝 摘要(中文)
本文介绍了InternVL 2.5,这是一个先进的多模态大型语言模型(MLLM)系列,它建立在InternVL 2.0的基础上,保持了其核心模型架构,同时在训练和测试策略以及数据质量方面引入了显著的增强。本文深入研究了模型缩放与性能之间的关系,系统地探索了视觉编码器、语言模型、数据集大小和测试时配置的性能趋势。通过对包括多学科推理、文档理解、多图像/视频理解、真实世界理解、多模态幻觉检测、视觉 grounding、多语言能力和纯语言处理在内的广泛基准的评估,InternVL 2.5表现出具有竞争力的性能,可与GPT-4o和Claude-3.5-Sonnet等领先的商业模型相媲美。值得注意的是,我们的模型是第一个在MMMU基准上超过70%的开源MLLM,通过思维链(CoT)推理实现了3.7个百分点的改进,并展示了测试时扩展的强大潜力。我们希望该模型通过为开发和应用多模态AI系统设定新标准,为开源社区做出贡献。
🔬 方法详解
问题定义:现有开源多模态大语言模型在多学科推理、文档理解、多图像/视频理解、真实世界理解、多模态幻觉检测、视觉 grounding、多语言能力和纯语言处理等任务上与商业模型存在差距,尤其是在复杂推理和幻觉抑制方面。现有方法在模型规模、数据质量和测试策略上存在局限性,难以充分挖掘模型的潜力。
核心思路:本文的核心思路是通过系统性的模型、数据和测试时扩展来提升开源多模态模型的性能。具体来说,通过扩大视觉编码器和语言模型的规模,提高训练数据的质量和多样性,以及优化测试时的推理策略,从而增强模型的理解、推理和生成能力。
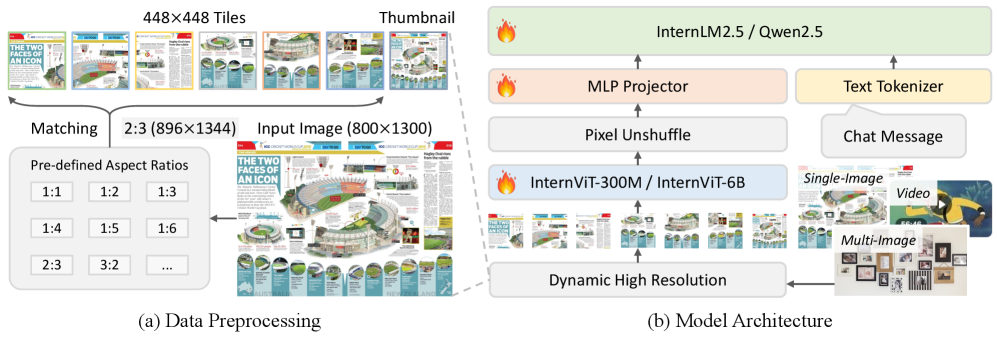
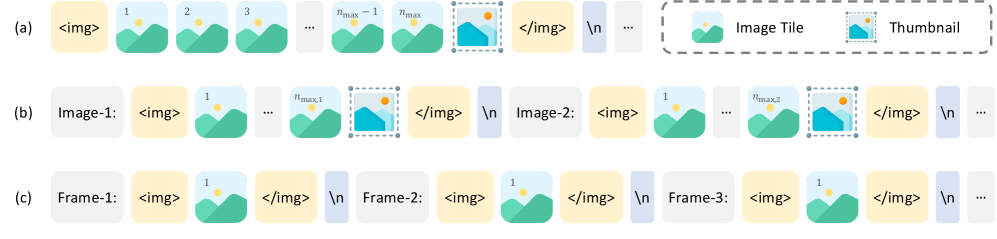
技术框架:InternVL 2.5沿用了InternVL 2.0的核心架构,主要包括视觉编码器、多模态连接器和语言模型三个模块。视觉编码器负责提取图像或视频的视觉特征,多模态连接器将视觉特征与文本信息融合,语言模型则负责生成最终的输出。训练流程包括预训练和微调两个阶段,预训练阶段使用大规模多模态数据进行训练,微调阶段则针对特定任务进行优化。
关键创新:本文最重要的技术创新在于系统性地探索了模型、数据和测试时扩展对多模态模型性能的影响。通过实验分析,确定了不同因素对性能的贡献,并提出了相应的优化策略。此外,本文还探索了思维链(CoT)推理在多模态任务中的应用,并取得了显著的性能提升。
关键设计:在模型扩展方面,本文尝试了不同规模的视觉编码器和语言模型,并分析了它们对性能的影响。在数据方面,本文注重提高训练数据的质量和多样性,包括增加多语言数据、复杂场景数据和对抗性数据。在测试时,本文采用了思维链(CoT)推理策略,通过逐步推理来提高模型的准确性和可靠性。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
InternVL 2.5在MMMU基准测试中取得了超过70%的成绩,成为首个达到该水平的开源MLLM。通过思维链(CoT)推理,性能提升了3.7个百分点。在其他基准测试中,InternVL 2.5也表现出与GPT-4o和Claude-3.5-Sonnet等商业模型相媲美的竞争力,证明了其强大的多模态理解和推理能力。
🎯 应用场景
InternVL 2.5的潜在应用领域广泛,包括智能客服、教育辅导、医疗诊断、自动驾驶、机器人等。该模型可以用于处理各种多模态任务,例如图像描述、视频问答、文档理解、视觉推理等。通过开源发布,InternVL 2.5将促进多模态AI技术的发展和应用,并为研究人员和开发者提供一个强大的工具。
📄 摘要(原文)
We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL