Assessing and Learning Alignment of Unimodal Vision and Language Models
作者: Le Zhang, Qian Yang, Aishwarya Agrawal
分类: cs.CV
发布日期: 2024-12-05 (更新: 2025-04-19)
备注: CVPR 2025 Highlight
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出SAIL框架,高效对齐单模态视觉和语言模型,提升多模态任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 迁移学习 零样本学习 模型对齐 对比学习 预训练模型
📋 核心要点
- 现有方法难以直接评估单模态视觉和语言模型在实际视觉-语言任务中的对齐程度。
- SAIL框架通过高效的迁移学习,对齐预训练的单模态模型,减少了对配对数据的需求。
- SAIL在ImageNet零样本分类上超越CLIP,并在检索、推理和分割等任务上表现优异。
📝 摘要(中文)
本文旨在评估单模态视觉和语言模型的对齐程度。现有评估方法无法直接应用于实际的视觉-语言任务,因此本文提出了一种受线性探测启发的直接评估方法。研究发现,SSL视觉模型的对齐程度取决于其SSL训练目标,并且SSL表征的聚类质量比线性可分性对对齐性能的影响更大。此外,本文还提出了图像和语言的快速对齐框架(SAIL),这是一种高效的迁移学习框架,用于对齐预训练的单模态视觉和语言模型,以用于下游视觉-语言任务。与从头开始训练的模型(如CLIP)相比,SAIL利用了预训练单模态模型的优势,因此多模态对齐所需的配对图像-文本数据显著减少(6%)。SAIL训练仅需单个A100 GPU,5小时的训练时间,并且可以容纳高达32,768的批量大小。SAIL在ImageNet上实现了73.4%的零样本准确率(CLIP为72.7%),并且在零样本检索、复杂推理和语义分割方面表现出色。此外,SAIL提高了视觉编码器的语言兼容性,从而增强了多模态大型语言模型的性能。整个代码库和模型权重都是开源的。
🔬 方法详解
问题定义:论文旨在解决如何高效地对齐预训练的单模态视觉和语言模型,以提升它们在下游多模态任务中的性能。现有方法,如从头训练CLIP,需要大量的配对图像-文本数据,计算成本高昂,且未能充分利用单模态模型已有的知识。
核心思路:论文的核心思路是利用预训练的单模态视觉和语言模型的强大表征能力,通过高效的迁移学习方法,将它们对齐到一个共享的语义空间。这样可以避免从头训练,显著减少对配对数据的需求,并加速模型训练。
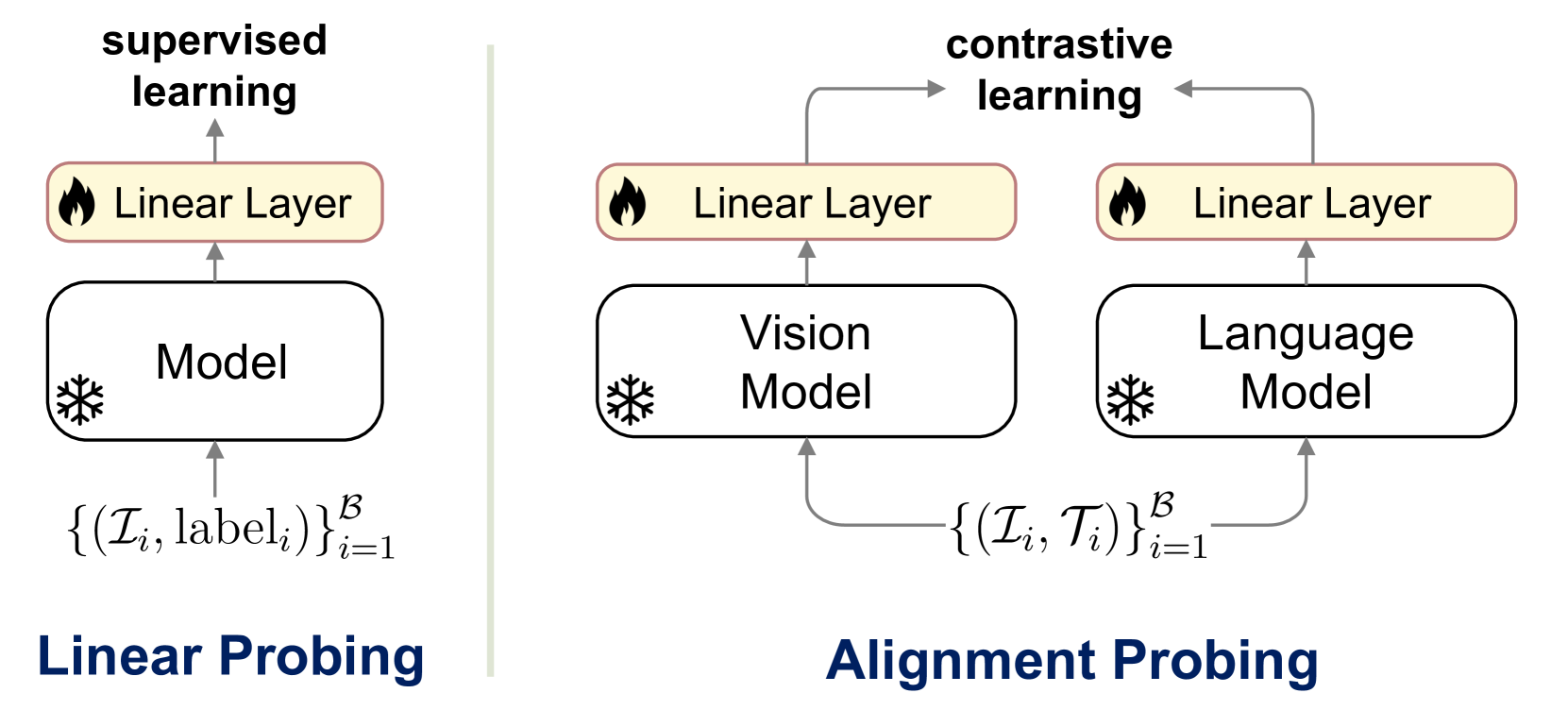
技术框架:SAIL框架主要包含以下几个阶段:1) 使用线性探测评估预训练视觉和语言模型的对齐程度,分析不同SSL训练目标对对齐的影响。2) 设计高效的迁移学习策略,将预训练的单模态模型对齐。3) 在下游视觉-语言任务上进行评估,验证SAIL框架的有效性。整体架构简洁高效,易于实现和部署。
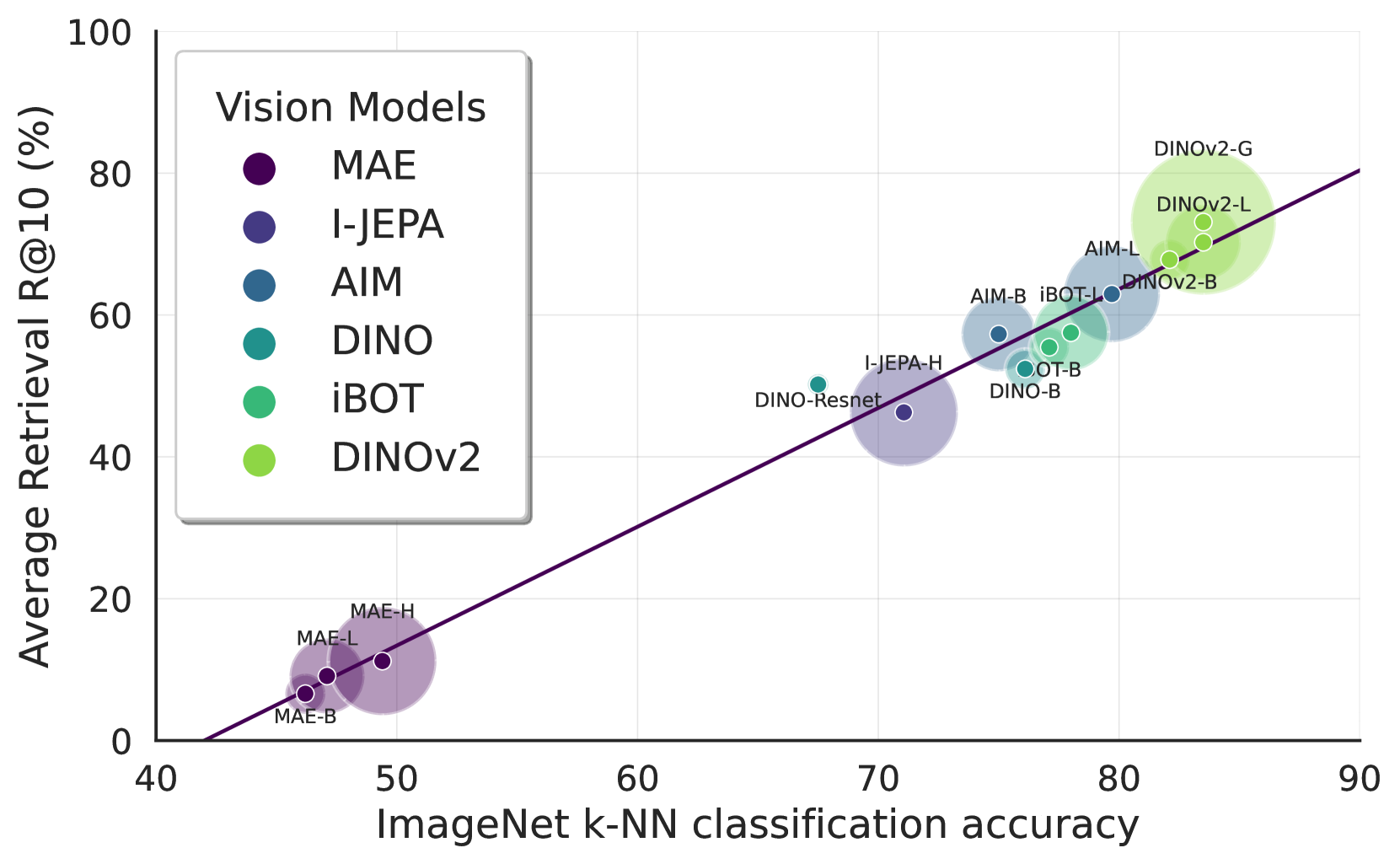
关键创新:SAIL的关键创新在于其高效的迁移学习策略,它能够充分利用预训练单模态模型的知识,仅需少量配对数据即可实现有效的多模态对齐。此外,论文还提出了一种基于线性探测的直接评估方法,用于评估单模态模型的对齐程度,为后续的对齐工作提供了指导。
关键设计:SAIL框架的关键设计包括:1) 使用预训练的视觉Transformer和文本Transformer作为骨干网络。2) 设计了特定的对齐损失函数,例如对比学习损失,以促进视觉和语言表征的对齐。3) 采用了较大的批量大小(高达32,768),以提高训练效率。4) 通过实验验证了不同SSL训练目标对对齐性能的影响,并选择了合适的预训练模型。
🖼️ 关键图片
📊 实验亮点
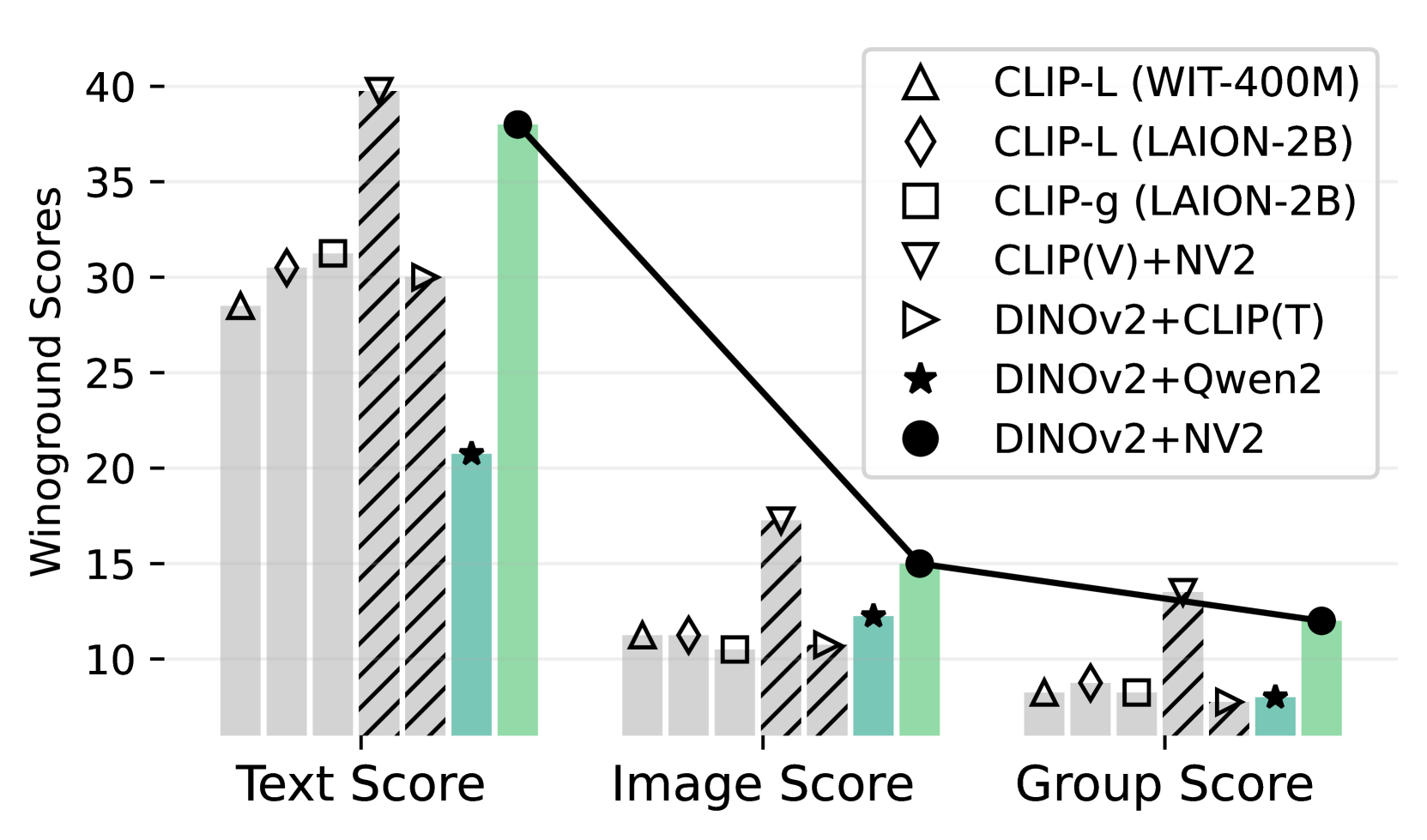
SAIL框架在ImageNet零样本分类上取得了73.4%的准确率,超越了CLIP的72.7%。在零样本检索、复杂推理和语义分割等任务上也表现出色。与从头训练的模型相比,SAIL仅需6%的配对图像-文本数据即可实现有效的多模态对齐,训练时间也大幅缩短,仅需单个A100 GPU和5小时。
🎯 应用场景
SAIL框架可广泛应用于各种视觉-语言任务,如图像检索、视觉问答、图像描述、零样本分类和语义分割等。该研究成果有助于提升多模态模型的性能和效率,降低训练成本,并促进跨模态信息融合技术的发展。未来,SAIL有望应用于智能助手、自动驾驶、医疗诊断等领域。
📄 摘要(原文)
How well are unimodal vision and language models aligned? Although prior work have approached answering this question, their assessment methods do not directly translate to how these models are used in practical vision-language tasks. In this paper, we propose a direct assessment method, inspired by linear probing, to assess vision-language alignment. We identify that the degree of alignment of the SSL vision models depends on their SSL training objective, and we find that the clustering quality of SSL representations has a stronger impact on alignment performance than their linear separability. Next, we introduce Swift Alignment of Image and Language (SAIL), a efficient transfer learning framework that aligns pretrained unimodal vision and language models for downstream vision-language tasks. Since SAIL leverages the strengths of pretrained unimodal models, it requires significantly fewer (6%) paired image-text data for the multimodal alignment compared to models like CLIP which are trained from scratch. SAIL training only requires a single A100 GPU, 5 hours of training and can accommodate a batch size up to 32,768. SAIL achieves 73.4% zero-shot accuracy on ImageNet (vs. CLIP's 72.7%) and excels in zero-shot retrieval, complex reasoning, and semantic segmentation. Additionally, SAIL improves the language-compatibility of vision encoders that in turn enhance the performance of multimodal large language models. The entire codebase and model weights are open-source: https://lezhang7.github.io/sail.github.io/