p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay
作者: Jun Zhang, Desen Meng, Zhengming Zhang, Zhenpeng Huang, Tao Wu, Limin Wang
分类: cs.CV, cs.CL
发布日期: 2024-12-05 (更新: 2025-08-06)
备注: Accepted by ICCV 2025; Code released at https://github.com/MCG-NJU/p-MoD
💡 一句话要点
提出p-MoD,通过渐进比例衰减构建高效的混合深度多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 混合深度 token选择 渐进比例衰减 高效推理 视觉问答 计算效率
📋 核心要点
- 多模态大语言模型(MLLM)计算成本高昂,限制了其发展,需要更高效的架构。
- p-MoD利用混合深度(MoD)机制,选择性处理视觉tokens,并引入TanhNorm和STRing来提升训练稳定性。
- 实验表明,p-MoD在保持或超越基线性能的同时,显著降低了推理和训练成本。
📝 摘要(中文)
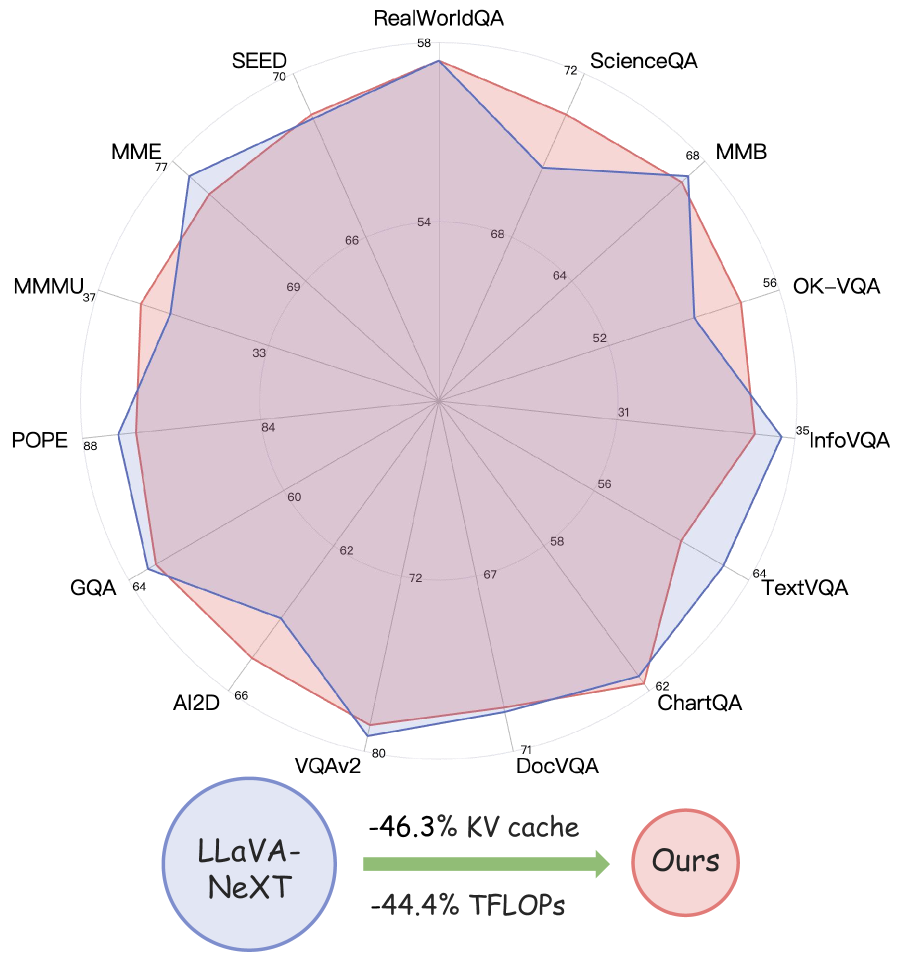
本文提出了一种高效的多模态大语言模型(MLLM)架构p-MoD,旨在显著降低训练和推理成本,同时保持模型性能。MLLM中的大部分计算来自Transformer LLM处理的大量视觉tokens。因此,我们利用混合深度(MoD)机制,其中每个LLM层选择重要的视觉tokens进行处理,而跳过冗余的tokens。然而,将MoD集成到MLLM中并非易事。为了解决训练和推理稳定性以及有限的训练数据等挑战,我们通过两个新颖的设计来改进MoD模块:tanh门控权重归一化(TanhNorm)和对称token重加权(STRing)。此外,我们观察到视觉tokens在更深层中表现出更高的冗余度,因此设计了一种渐进比例衰减(PRD)策略,该策略逐层降低token保留率,并采用移位的余弦调度。这一关键设计充分释放了MoD的潜力,显著提高了模型的效率和性能。在两个基线模型上进行的15个基准测试的广泛实验表明,我们的模型匹配甚至超过了相应基线的性能,同时在推理期间仅需要55.6%的TFLOPs和53.7%的KV缓存存储,以及训练期间77.7%的GPU小时。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)在处理视觉信息时,需要处理大量的视觉tokens,这导致了巨大的计算和存储开销,严重阻碍了模型的训练和部署。现有方法无法有效区分重要和冗余的视觉tokens,导致计算资源的浪费。
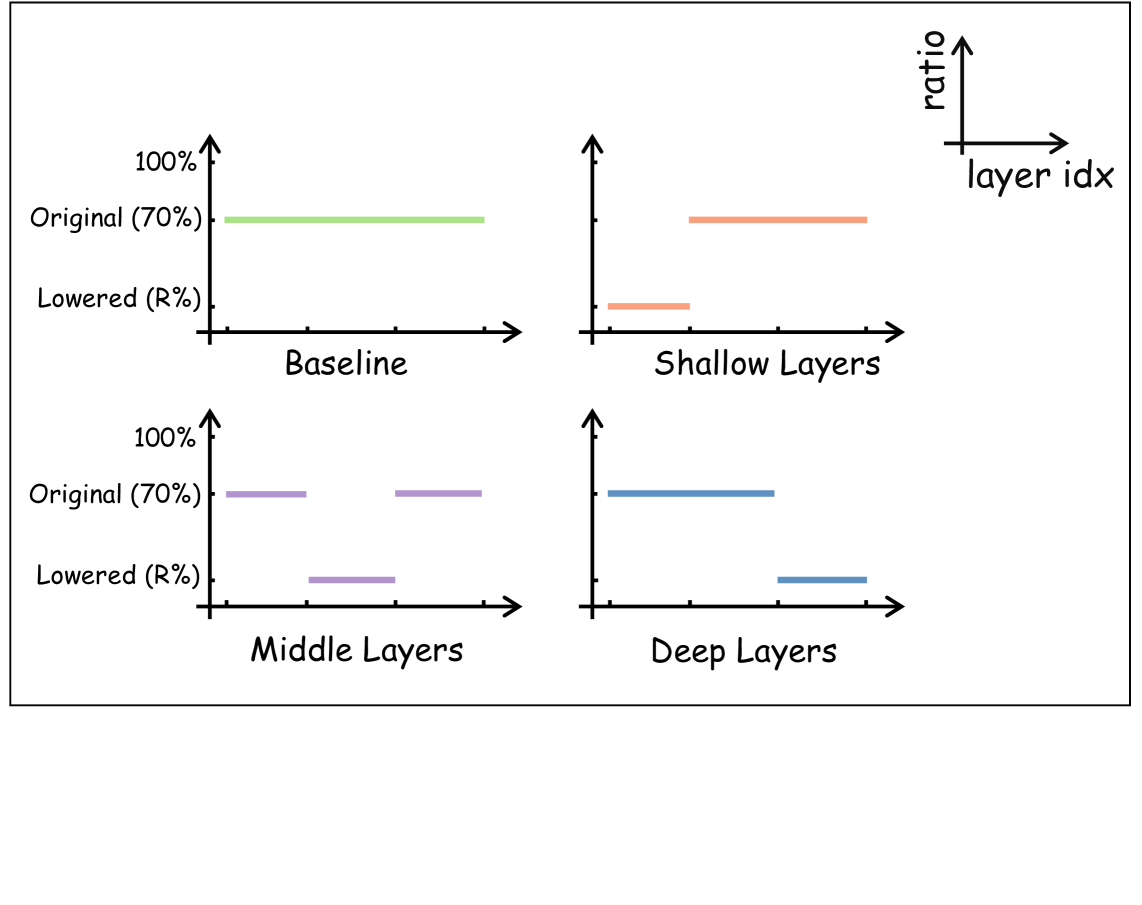
核心思路:本文的核心思路是利用混合深度(Mixture-of-Depths, MoD)机制,让模型的每一层选择性地处理重要的视觉tokens,跳过冗余的tokens,从而减少计算量。通过渐进比例衰减(Progressive Ratio Decay, PRD)策略,更深层的网络可以处理更少的tokens,因为深层特征的冗余度更高。
技术框架:p-MoD的整体架构基于Transformer的MLLM。首先,视觉信息被编码成视觉tokens。然后,这些tokens被输入到MoD模块中,MoD模块决定哪些tokens需要被当前层处理。MoD模块的输出被传递到Transformer的后续层。PRD策略控制每一层保留的tokens比例。
关键创新:本文的关键创新在于将MoD机制引入MLLM,并设计了渐进比例衰减策略。此外,为了解决MoD训练中的稳定性和数据限制问题,引入了Tanh门控权重归一化(TanhNorm)和对称token重加权(STRing)技术。PRD策略能够根据网络深度动态调整token保留率,充分利用了深层特征的冗余性。
关键设计:TanhNorm使用tanh门控来控制权重归一化的强度,提高了训练的稳定性。STRing通过对称的方式对tokens进行重加权,平衡了不同tokens的重要性。PRD策略使用移位的余弦调度来控制token保留率的衰减,确保模型在训练初期能够充分学习所有tokens的信息,并在训练后期逐渐减少冗余tokens的处理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,p-MoD在15个基准测试中达到了与基线模型相当甚至更好的性能,同时显著降低了计算和存储成本。具体来说,p-MoD在推理期间仅需要55.6%的TFLOPs和53.7%的KV缓存存储,在训练期间仅需要77.7%的GPU小时。
🎯 应用场景
p-MoD适用于各种需要处理视觉信息的多模态任务,例如图像描述、视觉问答、视频理解等。该研究可以降低MLLM的部署成本,使其更容易在资源受限的设备上运行。此外,p-MoD还可以加速MLLM的训练过程,提高模型迭代效率。
📄 摘要(原文)
Despite the remarkable performance of multimodal large language models (MLLMs) across diverse tasks, the substantial training and inference costs impede their advancement. In this paper, we propose p-MoD, an efficient MLLM architecture that significantly reduces training and inference costs while maintaining model performance. The majority of computation in MLLMs stems from the overwhelming volume of vision tokens processed by the transformer-based LLM. Accordingly, we leverage the Mixture-of-Depths (MoD) mechanism, where each LLM layer selects essential vision tokens to process while skipping redundant ones. However, integrating MoD into MLLMs is non-trivial. To address the challenges of training and inference stability as well as limited training data, we adapt the MoD module with two novel designs: tanh-gated weight normalization (TanhNorm) and symmetric token reweighting (STRing). Moreover, we observe that vision tokens exhibit higher redundancy in deeper layers and thus design a progressive ratio decay (PRD) strategy, which gradually reduces the token retention ratio layer by layer, employing a shifted cosine schedule. This crucial design fully unleashes the potential of MoD, significantly boosting the efficiency and performance of our models. Extensive experiments on two baseline models across 15 benchmarks show that our model matches or even surpasses the performance of corresponding baselines, while requiring only 55.6% TFLOPs and 53.7% KV cache storage during inference, and 77.7% GPU hours during training.