Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
作者: Jiuhai Chen, Jianwei Yang, Haiping Wu, Dianqi Li, Jianfeng Gao, Tianyi Zhou, Bin Xiao
分类: cs.CV, cs.AI
发布日期: 2024-12-05
🔗 代码/项目: GITHUB
💡 一句话要点
Florence-VL:利用生成式视觉编码器和深度-广度融合增强视觉-语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 生成式视觉编码器 深度-广度融合 多模态学习 视觉问答
📋 核心要点
- 现有视觉-语言模型依赖对比学习的视觉Transformer,难以捕捉多层次、多方面的视觉特征,限制了模型在复杂任务中的表现。
- Florence-VL利用生成式视觉基础模型Florence-2提取更丰富的视觉特征,并通过深度-广度融合(DBFusion)策略有效集成到大型语言模型中。
- 实验结果表明,Florence-VL在多个多模态和视觉中心基准测试中显著优于现有模型,尤其在视觉-语言对齐方面表现突出。
📝 摘要(中文)
本文提出了Florence-VL,这是一个新的多模态大型语言模型(MLLM)家族,它利用Florence-2(一种生成式视觉基础模型)生成更丰富的视觉表示。与广泛使用的通过对比学习训练的CLIP风格视觉Transformer不同,Florence-2能够捕获不同层次和方面的视觉特征,使其能够更灵活地适应各种下游任务。我们提出了一种新颖的特征融合架构和创新的训练方法,有效地将Florence-2的视觉特征集成到预训练的LLM中,例如Phi 3.5和LLama 3。特别地,我们提出了“深度-广度融合(DBFusion)”来融合从不同深度和多个提示中提取的视觉特征。我们的模型训练包括整个模型的端到端预训练,然后是对投影层和LLM的微调,采用精心设计的包含高质量图像字幕和指令调整对的各种开源数据集。对Florence-VL视觉特征的定量分析和可视化表明,其在视觉-语言对齐方面优于流行的视觉编码器,其中丰富的深度和广度发挥着重要作用。Florence-VL在各种多模态和以视觉为中心的基准测试中,包括通用VQA、感知、幻觉、OCR、图表、知识密集型理解等,都取得了优于现有最先进MLLM的显著改进。为了方便未来的研究,我们的模型和完整的训练方法都是开源的。
🔬 方法详解
问题定义:现有的视觉-语言模型通常使用CLIP风格的视觉Transformer作为视觉编码器,这些编码器主要通过对比学习进行训练,虽然在某些任务上表现良好,但它们难以捕捉到图像中不同层次和不同方面的视觉特征。这限制了模型在需要更细粒度视觉理解的任务中的表现,例如知识密集型视觉问答、图表理解等。因此,如何设计一个能够提取更丰富、更全面的视觉特征的视觉编码器,并将其有效地融入到大型语言模型中,是本文要解决的核心问题。
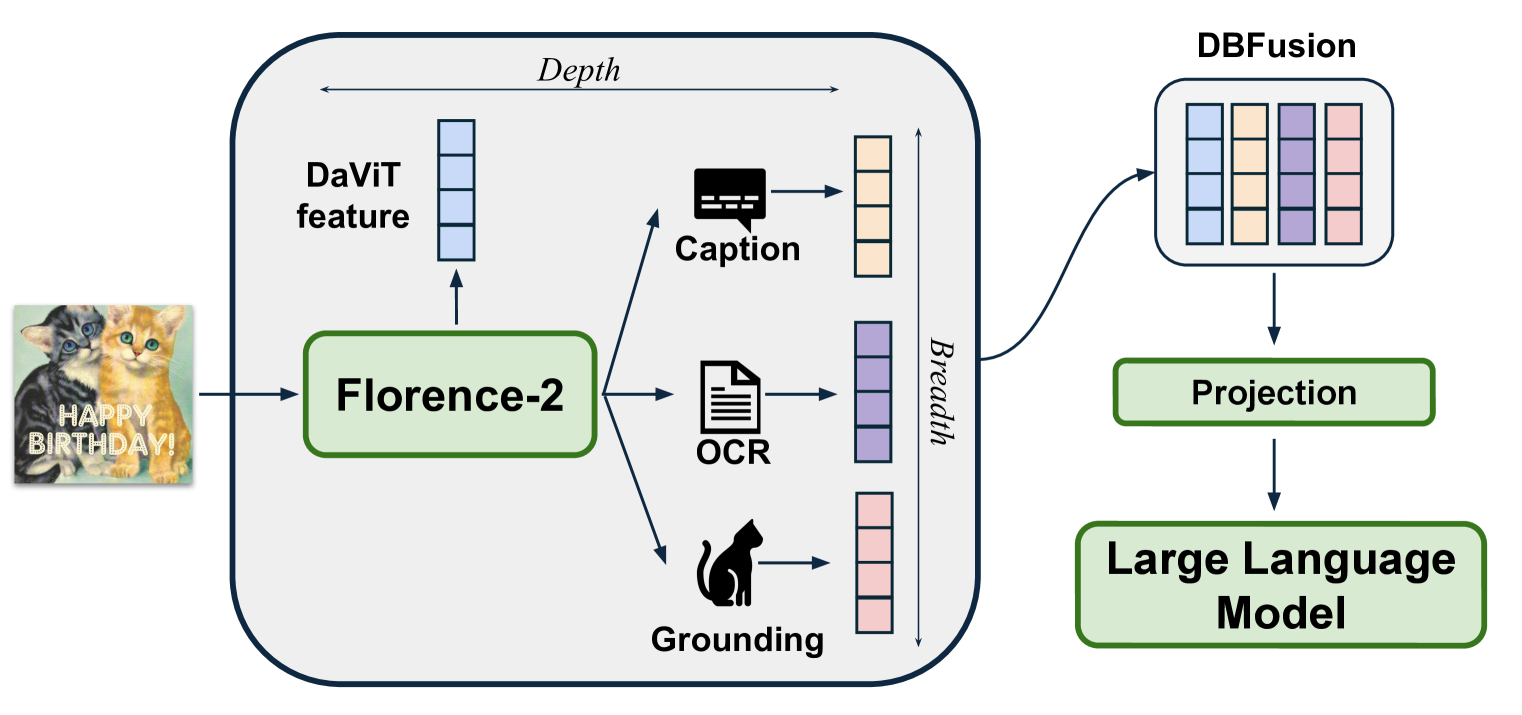
核心思路:本文的核心思路是利用生成式视觉基础模型Florence-2作为视觉编码器,替代传统的CLIP风格的视觉Transformer。Florence-2通过生成式训练,能够学习到图像更深层次的语义信息和更全面的视觉特征。此外,本文还提出了深度-广度融合(DBFusion)策略,将Florence-2在不同深度和不同提示下提取的视觉特征进行融合,从而进一步增强视觉表示的丰富性和鲁棒性。这样设计的目的是为了让模型能够更好地理解图像内容,并将其与语言信息进行对齐,从而提升模型在各种视觉-语言任务中的表现。
技术框架:Florence-VL的整体框架包含三个主要模块:Florence-2视觉编码器、深度-广度融合模块(DBFusion)和预训练的大型语言模型(LLM)。首先,输入图像通过Florence-2提取视觉特征。然后,DBFusion模块将不同深度和不同提示下的视觉特征进行融合,得到增强的视觉表示。最后,融合后的视觉特征被输入到预训练的LLM中,与语言信息进行交互,完成各种视觉-语言任务。整个模型采用端到端的方式进行训练,包括预训练和微调两个阶段。
关键创新:本文最重要的技术创新点在于以下两个方面:1) 使用生成式视觉基础模型Florence-2作为视觉编码器,替代传统的对比学习视觉Transformer。Florence-2能够提取更丰富、更全面的视觉特征,从而提升模型的视觉理解能力。2) 提出深度-广度融合(DBFusion)策略,将不同深度和不同提示下的视觉特征进行融合,进一步增强视觉表示的鲁棒性和表达能力。与现有方法相比,Florence-VL能够更好地捕捉图像中的语义信息和视觉细节,从而在各种视觉-语言任务中取得更好的表现。
关键设计:在DBFusion模块中,作者使用了多层感知机(MLP)来融合不同深度和不同提示下的视觉特征。具体来说,对于每个深度和每个提示,Florence-2都会提取一组视觉特征。DBFusion模块首先将这些特征进行拼接,然后通过MLP进行降维和融合。MLP的输出作为最终的视觉表示,被输入到LLM中。在训练过程中,作者使用了多种开源数据集,包括高质量的图像字幕和指令调整对。训练分为两个阶段:首先是整个模型的端到端预训练,然后是对投影层和LLM的微调。作者还精心设计了训练策略,以平衡不同数据集之间的影响,并防止模型过拟合。
🖼️ 关键图片


📊 实验亮点
Florence-VL在多个多模态和视觉中心基准测试中取得了显著的性能提升。例如,在VQA任务中,Florence-VL的准确率超过了现有最先进模型多个百分点。在知识密集型视觉问答任务中,Florence-VL的表现尤为突出,这表明其能够更好地理解图像中的语义信息。此外,Florence-VL在幻觉检测、OCR和图表理解等任务中也取得了显著的改进,证明了其在各种视觉-语言任务中的优越性。
🎯 应用场景
Florence-VL在多个领域具有广泛的应用前景,例如智能客服、自动驾驶、医疗影像分析、教育等。它可以用于构建更智能的视觉问答系统,帮助人们更好地理解图像内容;可以用于提升自动驾驶系统的感知能力,提高驾驶安全性;可以用于辅助医生进行疾病诊断,提高诊断效率和准确性;还可以用于开发更具吸引力的教育内容,提高学习效果。未来,Florence-VL有望成为各种视觉-语言应用的基础模型。
📄 摘要(原文)
We present Florence-VL, a new family of multimodal large language models (MLLMs) with enriched visual representations produced by Florence-2, a generative vision foundation model. Unlike the widely used CLIP-style vision transformer trained by contrastive learning, Florence-2 can capture different levels and aspects of visual features, which are more versatile to be adapted to diverse downstream tasks. We propose a novel feature-fusion architecture and an innovative training recipe that effectively integrates Florence-2's visual features into pretrained LLMs, such as Phi 3.5 and LLama 3. In particular, we propose "depth-breath fusion (DBFusion)" to fuse the visual features extracted from different depths and under multiple prompts. Our model training is composed of end-to-end pretraining of the whole model followed by finetuning of the projection layer and the LLM, on a carefully designed recipe of diverse open-source datasets that include high-quality image captions and instruction-tuning pairs. Our quantitative analysis and visualization of Florence-VL's visual features show its advantages over popular vision encoders on vision-language alignment, where the enriched depth and breath play important roles. Florence-VL achieves significant improvements over existing state-of-the-art MLLMs across various multi-modal and vision-centric benchmarks covering general VQA, perception, hallucination, OCR, Chart, knowledge-intensive understanding, etc. To facilitate future research, our models and the complete training recipe are open-sourced. https://github.com/JiuhaiChen/Florence-VL