Reflective Teacher: Semi-Supervised Multimodal 3D Object Detection in Bird's-Eye-View via Uncertainty Measure
作者: Saheli Hazra, Sudip Das, Rohit Choudhary, Arindam Das, Ganesh Sistu, Ciaran Eising, Ujjwal Bhattacharya
分类: cs.CV
发布日期: 2024-12-05
💡 一句话要点
提出Reflective Teacher和GA-BEVFusion,提升半监督BEV视角3D目标检测性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 3D目标检测 鸟瞰图 多模态融合 知识蒸馏 自动驾驶 伪标签
📋 核心要点
- 现有半监督3D目标检测方法中,EMA更新教师网络权重易导致灾难性遗忘,影响模型性能。
- 提出Reflective Teacher,通过正则化学生网络知识传递,确保教师网络保留先前知识,缓解遗忘问题。
- 引入GA-BEVFusion,有效对齐多模态BEV特征,提升相机和激光雷达数据的融合效果,实验结果显著。
📝 摘要(中文)
本文提出了一种新的半监督3D目标检测方法,用于自动驾驶场景下的鸟瞰图(BEV)视角。该方法利用伪标签技术,在标注数据有限的情况下提升性能。针对传统指数移动平均(EMA)导致的教师网络灾难性遗忘问题,本文引入了Reflective Teacher的概念,通过正则化项将学生网络的知识传递给教师网络,确保其保留先前的知识。此外,本文还提出了几何感知BEV融合(GA-BEVFusion),用于高效对齐多模态BEV特征,减少相机和激光雷达模态之间的差异。实验表明,该方法在nuScenes和Waymo数据集上均优于现有技术,并且仅使用25%和22%的标注数据即可达到全监督方法的性能。
🔬 方法详解
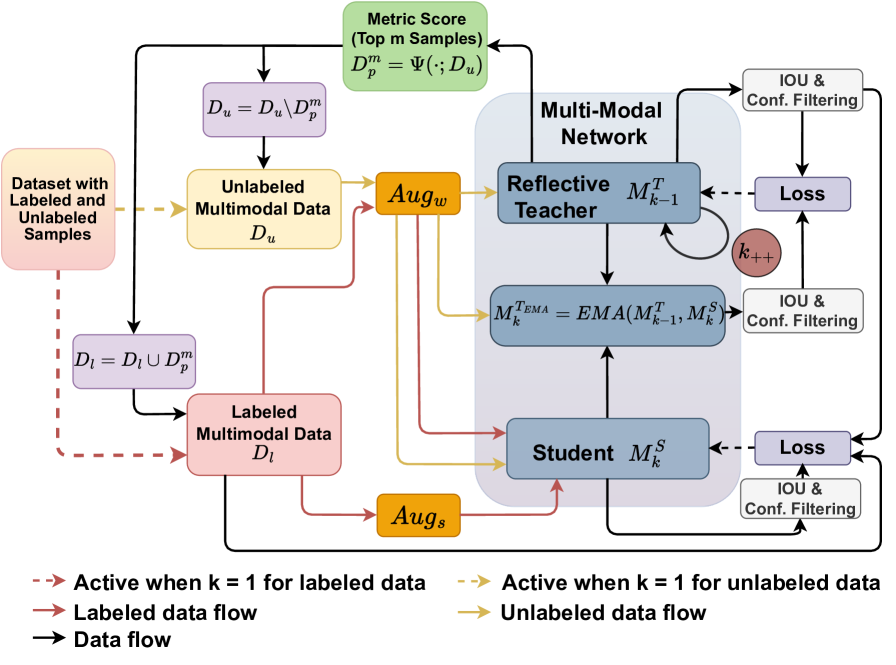
问题定义:论文旨在解决半监督3D目标检测中,尤其是在BEV视角下,标注数据不足的问题。现有方法,如使用指数移动平均(EMA)更新教师网络,容易导致教师网络发生灾难性遗忘,从而影响整体性能。此外,多模态数据(如相机和激光雷达)的有效融合也是一个挑战,模态间的差异会降低检测精度。
核心思路:论文的核心思路是设计一个“反思型教师”(Reflective Teacher),让学生网络在学习新知识的同时,也能将知识“反思”给教师网络,从而避免教师网络遗忘旧知识。同时,通过几何感知BEV融合(GA-BEVFusion)来更好地对齐多模态特征,提升融合效果。
技术框架:整体框架包含一个学生网络和一个教师网络。学生网络使用标注数据和伪标签数据进行训练。Reflective Teacher机制通过一个正则化项,将学生网络的知识传递给教师网络。GA-BEVFusion模块负责融合来自相机和激光雷达的BEV特征。训练完成后,使用教师网络进行推理。
关键创新:Reflective Teacher是该论文最关键的创新点。它不同于传统的EMA方法,通过正则化项显式地将学生网络的知识传递给教师网络,从而避免了教师网络的灾难性遗忘。GA-BEVFusion也是一个创新点,它通过几何感知的方式来对齐多模态特征,提升了融合效果。
关键设计:Reflective Teacher的关键在于正则化项的设计,该正则化项旨在最小化学生网络和教师网络之间的差异,从而将学生网络的知识传递给教师网络。GA-BEVFusion的关键在于如何有效地利用几何信息来对齐多模态特征,具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Reflective Teacher在nuScenes和Waymo数据集上均取得了优于现有方法的性能。更重要的是,该方法仅使用25%(nuScenes)和22%(Waymo)的标注数据,即可达到甚至超过全监督方法的性能,显著降低了对标注数据的依赖。
🎯 应用场景
该研究成果可应用于自动驾驶、智能交通等领域,尤其是在标注数据稀缺的情况下,能够有效提升3D目标检测的性能。通过更精确的目标检测,可以提高自动驾驶系统的安全性和可靠性,减少交通事故的发生。该方法也有潜力应用于机器人导航、场景理解等其他领域。
📄 摘要(原文)
Applying pseudo labeling techniques has been found to be advantageous in semi-supervised 3D object detection (SSOD) in Bird's-Eye-View (BEV) for autonomous driving, particularly where labeled data is limited. In the literature, Exponential Moving Average (EMA) has been used for adjustments of the weights of teacher network by the student network. However, the same induces catastrophic forgetting in the teacher network. In this work, we address this issue by introducing a novel concept of Reflective Teacher where the student is trained by both labeled and pseudo labeled data while its knowledge is progressively passed to the teacher through a regularizer to ensure retention of previous knowledge. Additionally, we propose Geometry Aware BEV Fusion (GA-BEVFusion) for efficient alignment of multi-modal BEV features, thus reducing the disparity between the modalities - camera and LiDAR. This helps to map the precise geometric information embedded among LiDAR points reliably with the spatial priors for extraction of semantic information from camera images. Our experiments on the nuScenes and Waymo datasets demonstrate: 1) improved performance over state-of-the-art methods in both fully supervised and semi-supervised settings; 2) Reflective Teacher achieves equivalent performance with only 25% and 22% of labeled data for nuScenes and Waymo datasets respectively, in contrast to other fully supervised methods that utilize the full labeled dataset.