Liquid: Language Models are Scalable and Unified Multi-modal Generators
作者: Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, Xiang Bai
分类: cs.CV
发布日期: 2024-12-05 (更新: 2025-04-10)
备注: Technical report. Project page: https://foundationvision.github.io/Liquid/
🔗 代码/项目: GITHUB
💡 一句话要点
Liquid:提出可扩展的统一多模态生成模型,提升视觉理解与生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态生成 大型语言模型 视觉理解 图像生成 统一标记空间 自回归模型 视觉语言融合
📋 核心要点
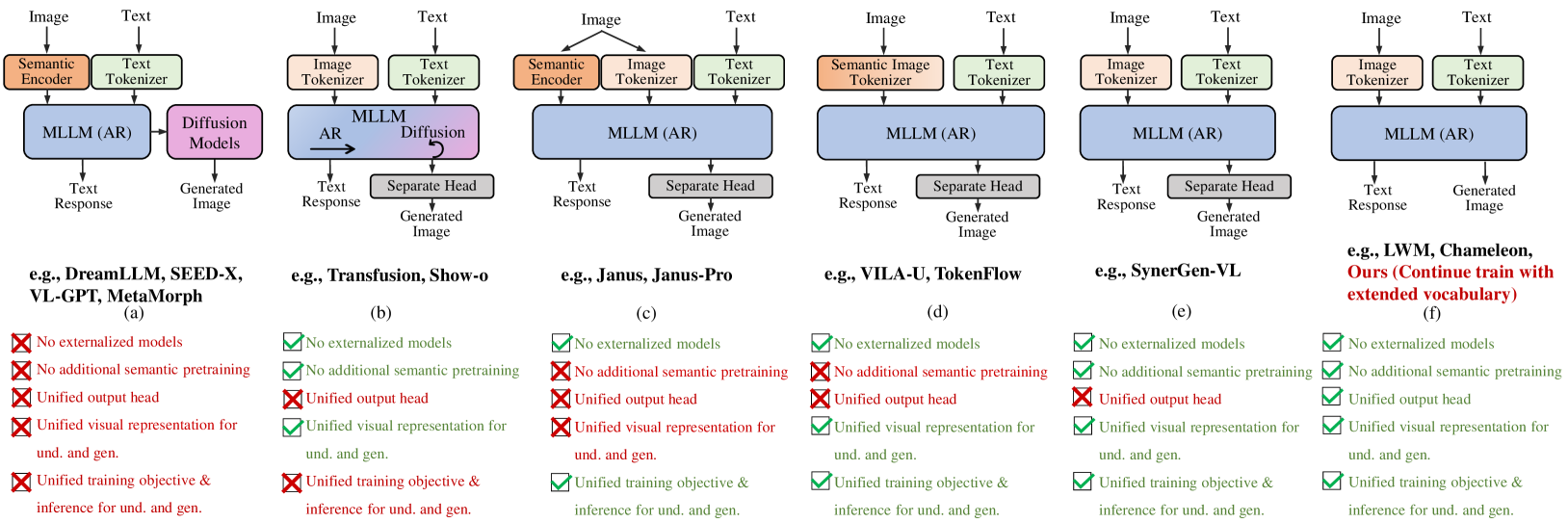
- 现有MLLM依赖外部预训练的视觉嵌入,且统一训练易导致性能下降,阻碍了视觉和语言任务的有效融合。
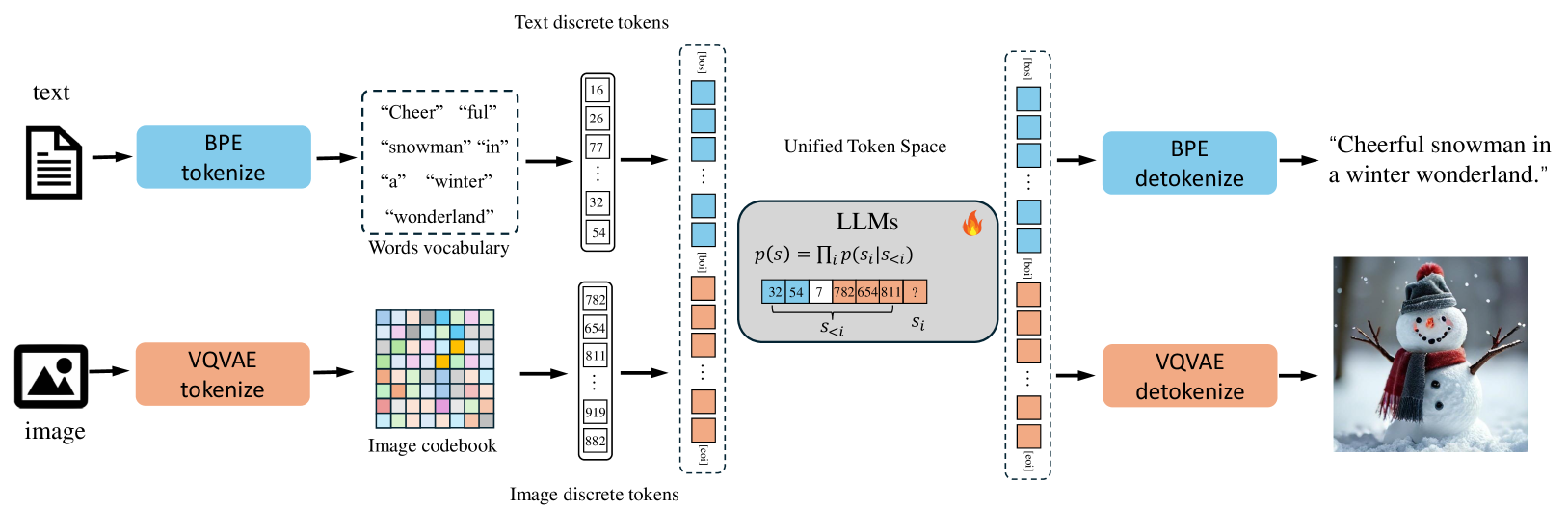
- Liquid通过统一的标记空间,将图像标记化为离散代码,与文本标记在共享特征空间中学习,实现视觉和语言的无缝集成。
- 实验表明,Liquid在多模态能力上超越Chameleon,语言性能媲美LLAMA2,且在视觉生成任务上优于SD v2.1和SD-XL。
📝 摘要(中文)
本文提出了一种名为Liquid的自回归生成范式,它通过将图像标记化为离散代码,并在视觉和语言的共享特征空间中学习这些代码嵌入以及文本标记,从而无缝地整合了视觉理解和生成。与以往的多模态大型语言模型(MLLM)不同,Liquid使用单个大型语言模型(LLM)实现这种集成,无需像CLIP这样的外部预训练视觉嵌入。Liquid首次揭示了一种缩放规律,即视觉和语言任务的统一训练不可避免地带来的性能下降会随着模型尺寸的增加而减小。此外,统一的标记空间使得视觉生成和理解任务能够相互促进,有效消除了早期模型中常见的干扰。实验表明,现有的LLM可以作为Liquid的强大基础,节省100倍的训练成本,同时在多模态能力上优于Chameleon,并在语言性能上与主流LLM(如LLAMA2)相媲美。Liquid还在MJHQ-30K数据集上优于SD v2.1和SD-XL等模型(FID为5.47),在视觉-语言和纯文本任务中均表现出色。这项工作表明,Qwen2.5和GEMMA2等LLM是强大的多模态生成器,为增强视觉-语言理解和生成提供了一种可扩展的解决方案。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)通常依赖于预训练的视觉编码器(如CLIP)来处理图像,这增加了模型的复杂性,并且视觉和语言特征之间的对齐可能存在问题。此外,统一训练视觉和语言任务时,模型性能可能会下降,即存在任务间的干扰,限制了模型的能力。
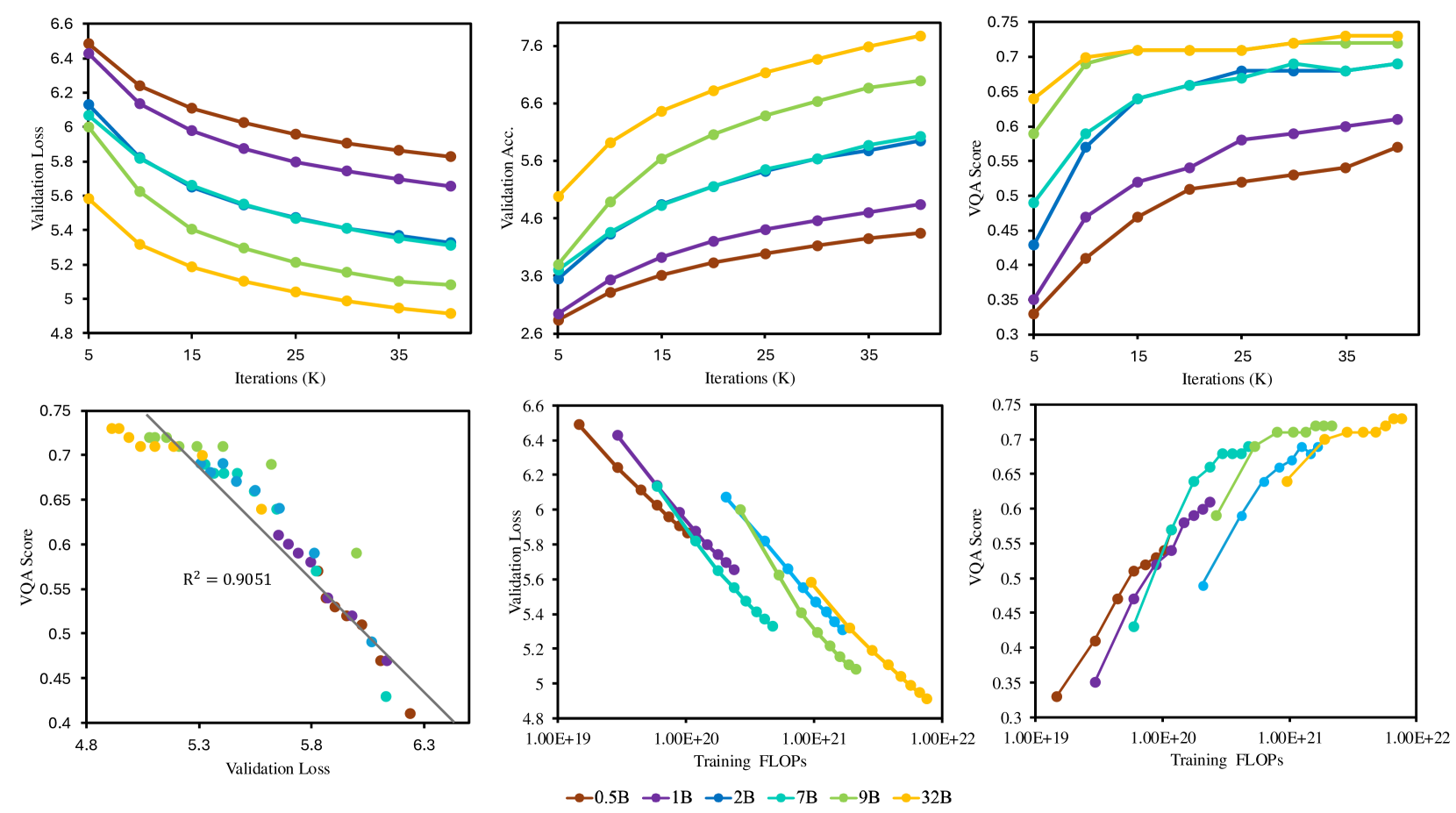
核心思路:Liquid的核心思路是构建一个统一的标记空间,将图像也表示为离散的token,并与文本token一起输入到单个大型语言模型(LLM)中进行训练。通过这种方式,模型可以直接学习视觉和语言之间的关系,而无需依赖外部的视觉编码器。此外,论文发现随着模型规模的增大,统一训练带来的性能下降会逐渐减小,从而验证了这种方法的有效性。
技术框架:Liquid的整体框架包括图像tokenization模块和LLM。图像首先被tokenization为离散的视觉token,然后这些token与文本token一起输入到LLM中。LLM使用自回归的方式生成文本或图像token。整个模型采用端到端的方式进行训练,优化目标是最大化生成序列的概率。
关键创新:Liquid的关键创新在于使用统一的token空间来表示视觉和语言信息,并使用单个LLM进行处理。这消除了对外部视觉编码器的依赖,简化了模型结构,并允许视觉和语言任务相互促进。此外,论文还揭示了模型规模对统一训练性能的影响,为未来的多模态模型设计提供了指导。
关键设计:图像tokenization模块可以使用VQ-VAE等方法将图像编码为离散的视觉token。LLM可以使用现有的预训练LLM,如Qwen2.5或GEMMA2。训练过程中,可以使用标准的自回归语言模型训练方法,并根据具体任务调整损失函数。例如,在图像生成任务中,可以使用交叉熵损失函数来衡量生成token与真实token之间的差异。
🖼️ 关键图片
📊 实验亮点
Liquid在多项实验中表现出色。在多模态能力上,Liquid优于Chameleon,并在语言性能上与LLAMA2相媲美。在MJHQ-30K数据集上,Liquid的FID得分为5.47,优于SD v2.1和SD-XL等模型。这些结果表明,Liquid是一种强大的多模态生成模型,具有很高的实用价值。
🎯 应用场景
Liquid具有广泛的应用前景,包括图像描述生成、视觉问答、图像生成、多模态对话等。该模型可以应用于智能客服、教育、娱乐等领域,为用户提供更加自然和智能的交互体验。未来,Liquid有望成为通用人工智能的重要组成部分,推动人工智能技术的发展。
📄 摘要(原文)
We present Liquid, an auto-regressive generation paradigm that seamlessly integrates visual comprehension and generation by tokenizing images into discrete codes and learning these code embeddings alongside text tokens within a shared feature space for both vision and language. Unlike previous multimodal large language model (MLLM), Liquid achieves this integration using a single large language model (LLM), eliminating the need for external pretrained visual embeddings such as CLIP. For the first time, Liquid uncovers a scaling law that performance drop unavoidably brought by the unified training of visual and language tasks diminishes as the model size increases. Furthermore, the unified token space enables visual generation and comprehension tasks to mutually enhance each other, effectively removing the typical interference seen in earlier models. We show that existing LLMs can serve as strong foundations for Liquid, saving 100x in training costs while outperforming Chameleon in multimodal capabilities and maintaining language performance comparable to mainstream LLMs like LLAMA2. Liquid also outperforms models like SD v2.1 and SD-XL (FID of 5.47 on MJHQ-30K), excelling in both vision-language and text-only tasks. This work demonstrates that LLMs such as Qwen2.5 and GEMMA2 are powerful multimodal generators, offering a scalable solution for enhancing both vision-language understanding and generation. The code and models will be released at https://github.com/FoundationVision/Liquid.