VASCAR: Content-Aware Layout Generation via Visual-Aware Self-Correction
作者: Jiahao Zhang, Ryota Yoshihashi, Shunsuke Kitada, Atsuki Osanai, Yuta Nakashima
分类: cs.CV
发布日期: 2024-12-05 (更新: 2025-03-11)
💡 一句话要点
VASCAR:通过视觉感知自校正实现内容感知的布局生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容感知布局生成 视觉语言模型 自校正 迭代优化 海报设计
📋 核心要点
- 现有大型语言模型在内容感知布局生成中,由于缺乏视觉感知能力,效果受限。
- VASCAR借鉴设计师的迭代修改流程,通过视觉感知自校正,提升布局生成质量。
- 实验表明,VASCAR在GPT-4o和Gemini上均表现出色,达到最先进的布局生成水平。
📝 摘要(中文)
大型语言模型(LLM)因其生成结构化描述语言(如HTML或JSON)的能力,已被证明在布局生成方面有效。然而,本文认为,尽管LLM在某些情况下表现良好,但其无法感知图像的内在局限性限制了其在需要视觉内容的任务中的有效性,例如内容感知的布局生成。因此,我们探索了大型视觉语言模型(LVLM)是否可以应用于内容感知的布局生成。为此,受到设计师迭代修改和启发式评估工作流程的启发,我们提出了无需训练的视觉感知自校正布局生成(VASCAR)。VASCAR使LVLM(如GPT-4o和Gemini)能够参考渲染的布局图像迭代地改进其输出,这些图像被可视化为海报背景(即画布)上的彩色边界框。大量的实验和用户研究表明了VASCAR的有效性,实现了最先进(SOTA)的布局生成质量。此外,VASCAR在GPT-4o和Gemini上的通用性证明了其多功能性。
🔬 方法详解
问题定义:论文旨在解决内容感知的布局生成问题。现有方法,特别是基于大型语言模型的方法,虽然可以生成布局,但由于缺乏对视觉内容的感知能力,无法很好地处理需要考虑图像内容的布局任务。这些方法无法理解图像中的元素,也无法根据图像内容调整布局。
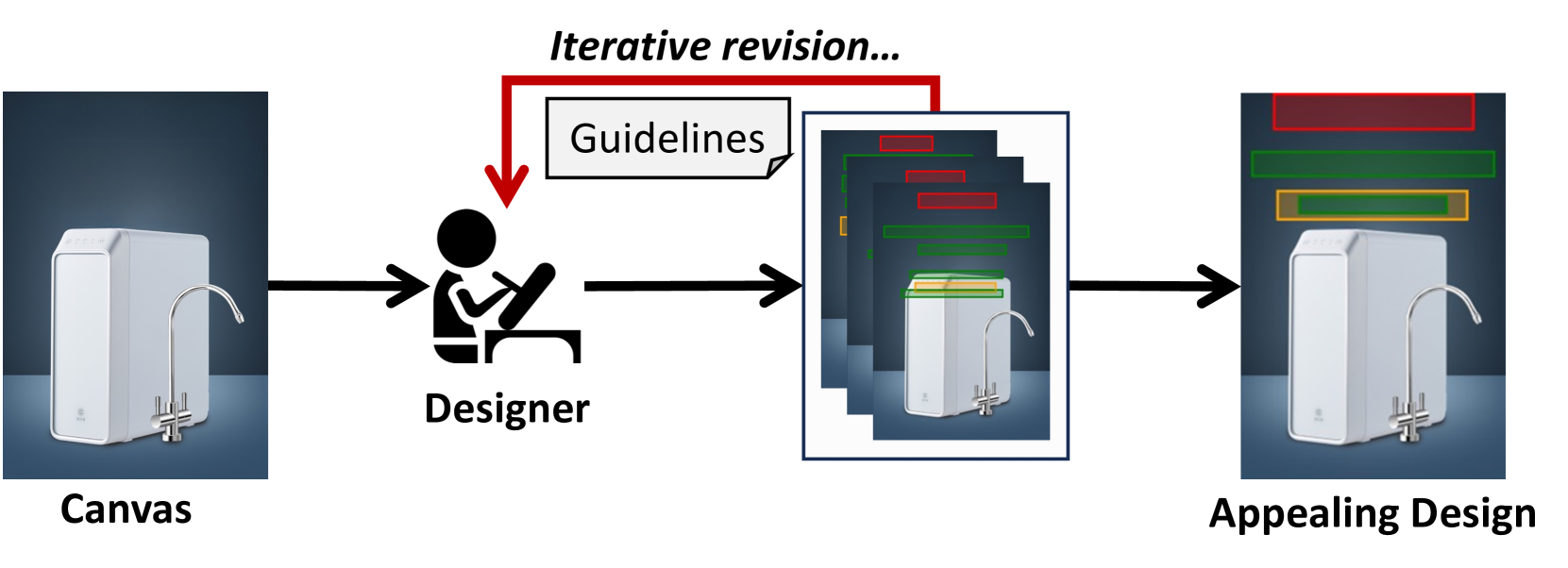
核心思路:论文的核心思路是让大型视觉语言模型(LVLM)能够像设计师一样,通过迭代地参考渲染的布局图像来修正和改进其布局生成结果。这种自校正过程模拟了设计师在设计过程中不断审查和修改布局的流程,从而提升布局的质量。
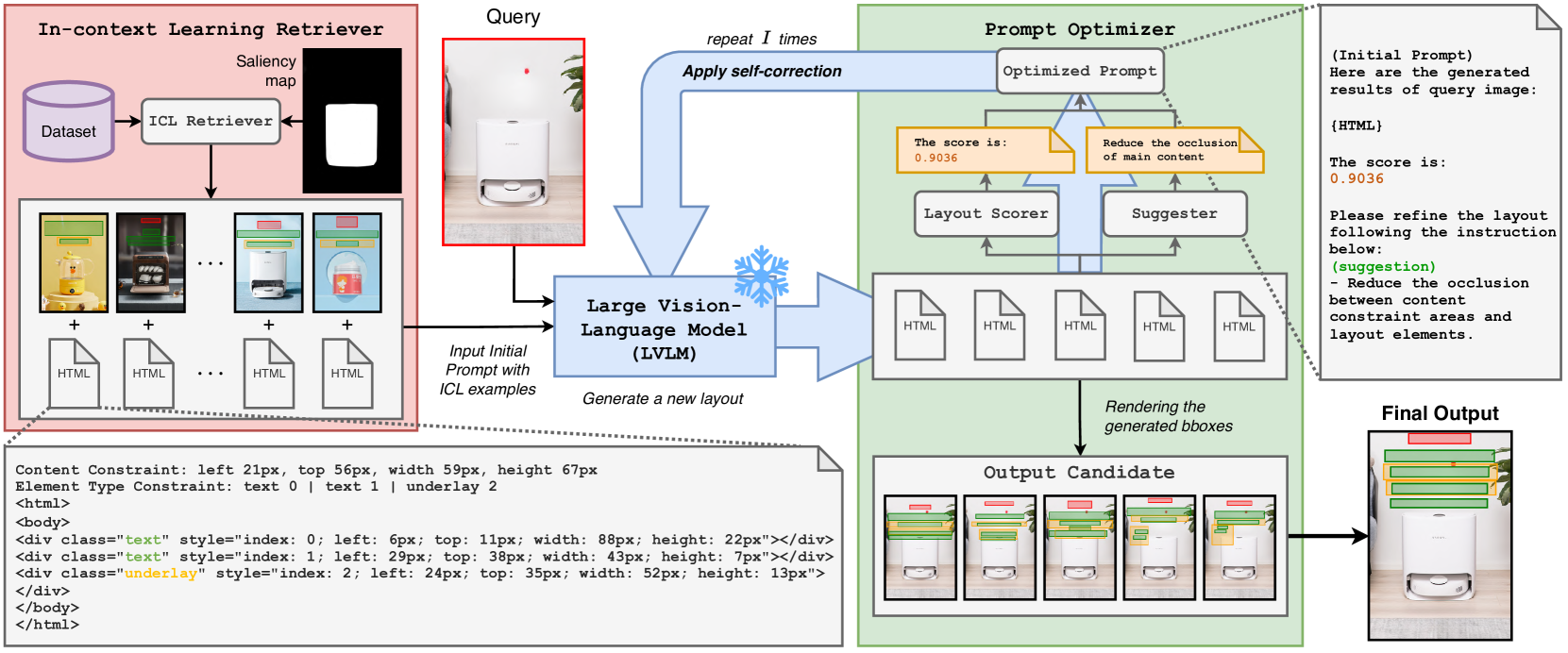
技术框架:VASCAR的核心是一个迭代的自校正框架。首先,LVLM生成一个初始布局。然后,该布局被渲染成图像,其中每个元素都用彩色边界框表示。接下来,LVLM接收渲染的布局图像作为输入,并根据图像中的视觉信息修正其布局。这个过程可以重复多次,直到生成满意的布局为止。整个过程无需额外的训练。
关键创新:VASCAR的关键创新在于其视觉感知的自校正机制。通过将渲染的布局图像反馈给LVLM,VASCAR使LVLM能够利用视觉信息来指导布局生成过程。这种方法不同于传统的基于语言模型的布局生成方法,后者仅依赖于文本描述,忽略了视觉内容的重要性。
关键设计:VASCAR的关键设计包括:1) 使用彩色边界框来可视化布局元素,以便LVLM能够更容易地识别和理解图像中的元素。2) 迭代的自校正过程,允许LVLM逐步改进其布局,直到达到满意的结果。3) 无需训练的设计,使得VASCAR可以很容易地应用于不同的LVLM,如GPT-4o和Gemini。论文没有明确提及损失函数或网络结构等细节,因为该方法主要依赖于现有LVLM的能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VASCAR在内容感知的布局生成任务中取得了最先进的性能。通过用户研究,证明了VASCAR生成的布局在视觉质量和内容相关性方面优于其他方法。VASCAR在GPT-4o和Gemini上的成功应用,验证了其通用性和有效性。
🎯 应用场景
VASCAR可应用于海报设计、网页设计、移动应用界面设计等领域。该研究的实际价值在于能够自动化生成高质量的内容感知布局,提高设计效率,降低设计成本。未来,VASCAR可以进一步扩展到更复杂的设计任务中,例如三维场景布局和视频编辑。
📄 摘要(原文)
Large language models (LLMs) have proven effective for layout generation due to their ability to produce structure-description languages, such as HTML or JSON. In this paper, we argue that while LLMs can perform reasonably well in certain cases, their intrinsic limitation of not being able to perceive images restricts their effectiveness in tasks requiring visual content, e.g., content-aware layout generation. Therefore, we explore whether large vision-language models (LVLMs) can be applied to content-aware layout generation. To this end, inspired by the iterative revision and heuristic evaluation workflow of designers, we propose the training-free Visual-Aware Self-Correction LAyout GeneRation (VASCAR). VASCAR enables LVLMs (e.g., GPT-4o and Gemini) iteratively refine their outputs with reference to rendered layout images, which are visualized as colored bounding boxes on poster background (i.e., canvas). Extensive experiments and user study demonstrate VASCAR's effectiveness, achieving state-of-the-art (SOTA) layout generation quality. Furthermore, the generalizability of VASCAR across GPT-4o and Gemini demonstrates its versatility.