CRAFT: Designing Creative and Functional 3D Objects
作者: Michelle Guo, Mia Tang, Hannah Cha, Ruohan Zhang, C. Karen Liu, Jiajun Wu
分类: cs.CV, cs.GR
发布日期: 2024-12-05 (更新: 2025-03-28)
备注: Project webpage: https://miatang13.github.io/Craft/. Published at WACV 2025
💡 一句话要点
CRAFT:设计具有创造性和功能性的、符合人体工学的3D物体
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 3D物体生成 人体工学设计 网格变形 语义对齐 接触损失 穿透损失 AI设计 虚拟角色
📋 核心要点
- 现有AI设计工具难以兼顾人体工学和设计规范的语义信息,导致设计过程存在挑战。
- CRAFT方法通过优化语义对齐、接触和穿透损失的网格变形过程,实现符合人体工学的3D物体合成。
- 实验结果表明,该方法能够从文本、图像或草图生成虚拟或真实世界的物体,无需人工干预。
📝 摘要(中文)
本文提出了一种从基础网格合成符合人体工学的3D物体的方法,该方法以输入的人体几何形状以及文本或图像作为指导。生成的对象可以在虚拟角色上进行模拟,或者可以制造用于真实世界的用途。我们提出使用网格变形程序,该程序优化语义对齐以及接触和穿透损失。使用我们的方法,用户可以从文本、图像或草图生成虚拟或真实世界的对象,而无需手动艺术家干预。我们在各种对象类别上展示了定性和定量结果,证明了我们方法的有效性。
🔬 方法详解
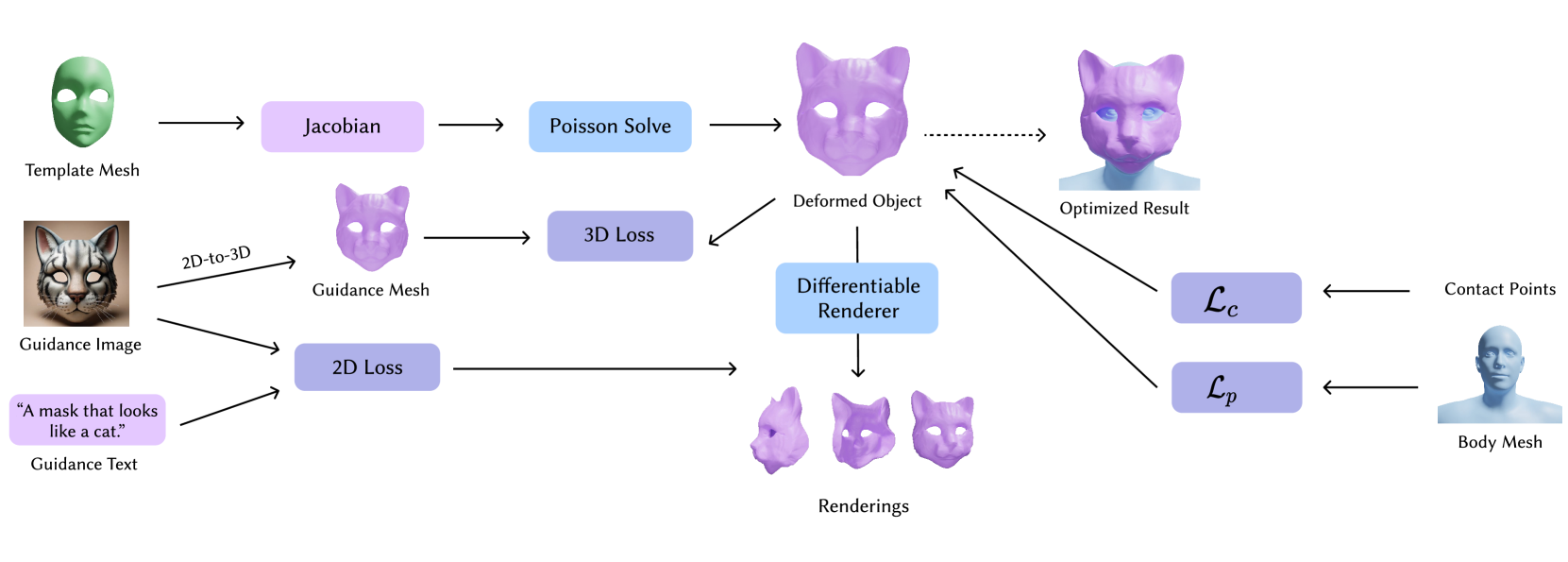
问题定义:论文旨在解决如何根据人体几何形状和语义指导(文本或图像)自动生成符合人体工学的3D物体的问题。现有方法通常难以同时满足人体工学约束(如避免穿透)和语义一致性,需要大量人工干预,效率低下。
核心思路:论文的核心思路是通过优化网格变形过程,使其同时满足语义对齐和人体工学约束。具体来说,就是将语义指导(文本或图像)和人体几何形状作为输入,通过优化一个包含语义对齐损失、接触损失和穿透损失的损失函数,来驱动基础网格的变形,从而生成符合要求的3D物体。
技术框架:CRAFT方法的技术框架主要包含以下几个阶段:1) 输入:接收基础网格、人体几何形状以及文本或图像作为输入。2) 语义编码:使用预训练的文本或图像编码器提取语义特征。3) 网格变形:通过优化损失函数来变形基础网格,损失函数包含语义对齐损失、接触损失和穿透损失。4) 输出:输出变形后的3D物体。
关键创新:该方法最重要的创新点在于将语义对齐和人体工学约束集成到一个统一的优化框架中。通过同时优化语义对齐损失、接触损失和穿透损失,可以生成既符合语义要求又符合人体工学约束的3D物体,显著减少了人工干预的需求。
关键设计:关键设计包括:1) 语义对齐损失:用于确保生成的3D物体与输入的文本或图像在语义上保持一致。可以使用对比学习损失或交叉熵损失来实现。2) 接触损失:用于鼓励生成的3D物体与人体接触,但避免过度接触。可以使用基于距离场的损失函数来实现。3) 穿透损失:用于惩罚生成的3D物体与人体之间的穿透。可以使用基于体积的损失函数来实现。具体的参数设置和网络结构在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
论文在多个对象类别上进行了定性和定量实验,结果表明CRAFT方法能够有效地生成符合人体工学和语义要求的3D物体。与现有方法相比,CRAFT方法能够显著减少人工干预的需求,并生成更逼真、更实用的3D物体。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
CRAFT方法具有广泛的应用前景,例如虚拟服装设计、游戏道具生成、个性化医疗器械设计等。该方法可以帮助设计师快速生成符合人体工学和语义要求的3D物体,提高设计效率,降低设计成本。未来,该方法可以进一步扩展到更多领域,例如建筑设计、工业设计等。
📄 摘要(原文)
For designing a wide range of everyday objects, the design process should be aware of both the human body and the underlying semantics of the design specification. However, these two objectives present significant challenges to the current AI-based designing tools. In this work, we present a method to synthesize body-aware 3D objects from a base mesh given an input body geometry and either text or image as guidance. The generated objects can be simulated on virtual characters, or fabricated for real-world use. We propose to use a mesh deformation procedure that optimizes for both semantic alignment as well as contact and penetration losses. Using our method, users can generate both virtual or real-world objects from text, image, or sketch, without the need for manual artist intervention. We present both qualitative and quantitative results on various object categories, demonstrating the effectiveness of our approach.