Scaling Inference-Time Search with Vision Value Model for Improved Visual Comprehension
作者: Xiyao Wang, Zhengyuan Yang, Linjie Li, Hongjin Lu, Yuancheng Xu, Chung-Ching Lin, Kevin Lin, Furong Huang, Lijuan Wang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-12-04 (更新: 2025-06-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出视觉价值模型VisVM,指导视觉语言模型推理时搜索,提升视觉理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 推理时搜索 视觉价值模型 图像描述生成 多模态学习
📋 核心要点
- 现有视觉语言模型缺乏有效的方法,通过扩展推理时计算来提高响应质量,这限制了其性能。
- 论文提出视觉价值模型VisVM,通过评估当前和预测未来句子的质量,引导VLM推理时搜索,避免幻觉和细节不足。
- 实验表明,VisVM显著提升了VLM生成描述性字幕的能力,减少了幻觉,并且自训练能提升VLM在多模态任务上的性能。
📝 摘要(中文)
本文提出了一种视觉价值模型(VisVM),旨在通过扩展推理时计算来提升视觉语言模型(VLM)的响应质量。与以往方法不同,VisVM不仅评估当前搜索步骤中生成的句子的质量,还能预测后续句子的质量,从而提供长期价值。通过这种方式,VisVM引导VLM避免生成容易产生幻觉或细节不足的句子,从而生成更高质量的响应。实验结果表明,与贪婪解码和其他视觉奖励信号的搜索方法相比,VisVM引导的搜索显著增强了VLM生成具有更丰富视觉细节和更少幻觉的描述性字幕的能力。此外,使用VisVM引导的字幕进行自训练可以提高VLM在各种多模态基准测试中的性能,表明了开发自改进型VLM的潜力。该价值模型和代码已开源。
🔬 方法详解
问题定义:视觉语言模型在生成描述性文本时,容易出现幻觉(hallucination)问题,即生成与图像内容不符的信息,或者缺乏足够的细节描述。现有的方法,例如贪婪解码,无法充分利用推理时计算资源来优化生成结果,导致视觉理解能力受限。
核心思路:论文的核心思路是引入一个视觉价值模型(VisVM),该模型能够评估当前生成的句子的质量,并预测后续可能生成的句子的质量,从而为搜索过程提供长期的价值导向。通过最大化这个长期价值,可以引导VLM生成更准确、更详细的描述,并减少幻觉。
技术框架:整体框架包含一个视觉语言模型(VLM)和一个视觉价值模型(VisVM)。VLM负责生成候选句子,VisVM负责评估这些句子的质量和预测未来句子的质量。在推理时,使用搜索算法(例如Beam Search)探索不同的句子序列,VisVM为每个候选序列打分,选择具有最高价值的序列作为最终输出。自训练阶段,使用VisVM引导VLM生成高质量的caption,然后用这些caption微调VLM。
关键创新:关键创新在于VisVM的设计,它不仅考虑了当前句子的质量,还考虑了未来句子的潜在价值。这种长期价值的评估能够引导VLM避免陷入局部最优,从而生成更全局一致、更符合图像内容的描述。与传统的奖励信号(例如CLIP score)相比,VisVM能够更好地捕捉视觉理解的长期依赖关系。
关键设计:VisVM的具体实现细节未知,论文开源了代码,可以参考代码了解具体实现。推测可能使用了Transformer结构,输入包括图像特征和生成的文本序列,输出是一个标量值,表示该序列的价值。损失函数的设计可能包括两部分:一部分是监督学习,使用人工标注的数据训练VisVM预测句子质量;另一部分是强化学习,使用VLM生成的句子序列作为训练数据,通过最大化VisVM的输出值来优化VLM的生成策略。
🖼️ 关键图片
📊 实验亮点
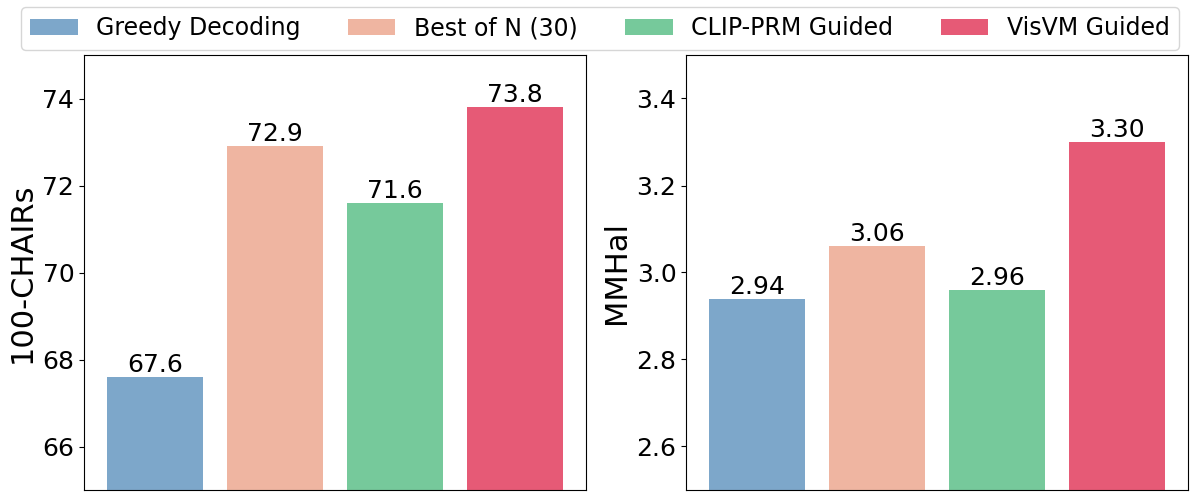
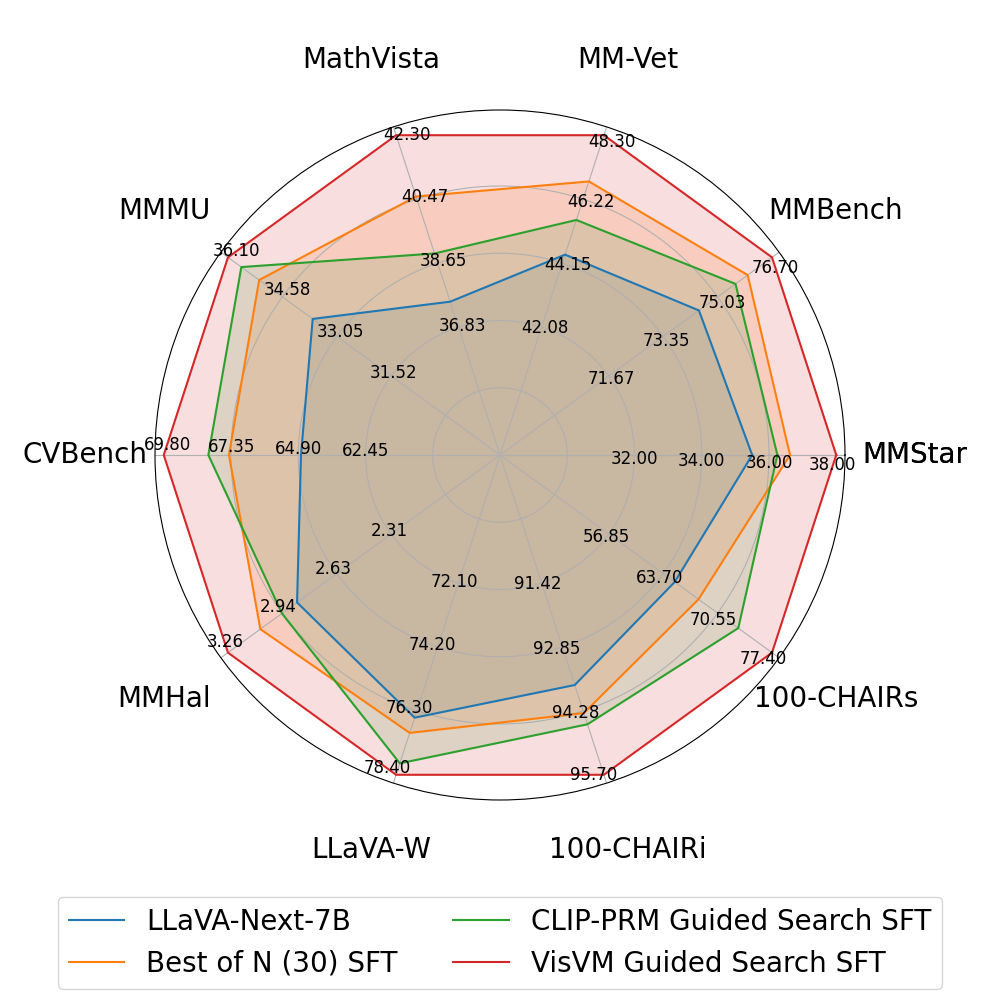
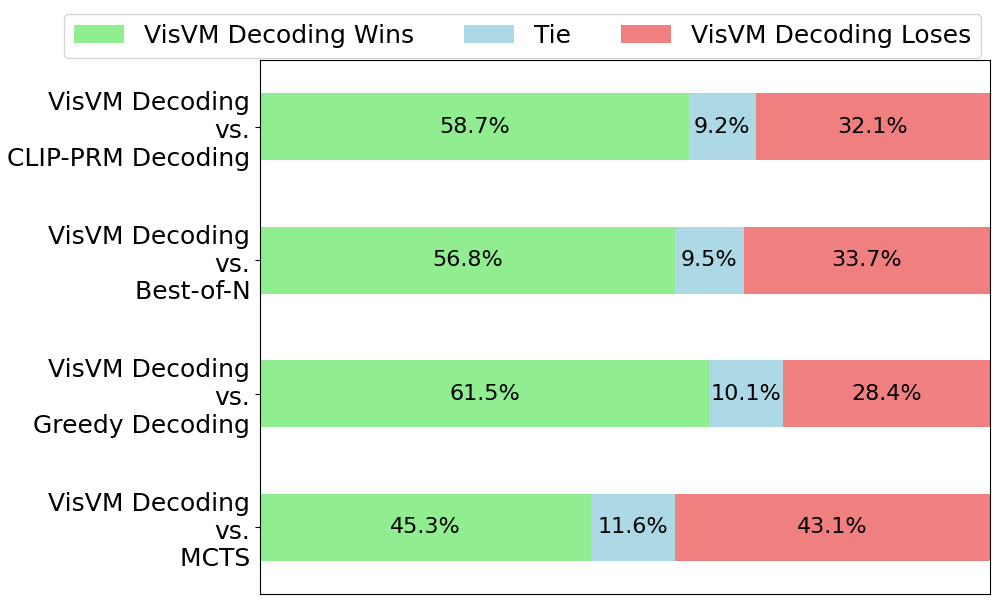
实验结果表明,VisVM引导的搜索显著提升了VLM生成描述性字幕的能力,减少了幻觉。与贪婪解码和其他视觉奖励信号的搜索方法相比,VisVM取得了显著的性能提升。此外,使用VisVM引导的字幕进行自训练可以提高VLM在各种多模态基准测试中的性能,证明了VisVM的有效性和泛化能力。具体性能数据未知,需要参考论文原文。
🎯 应用场景
该研究成果可应用于图像描述生成、视觉问答、机器人导航等领域。通过提升视觉语言模型的视觉理解能力,可以使机器更好地理解图像内容,并生成更准确、更自然的描述。这对于人机交互、智能客服、自动驾驶等应用具有重要意义,有助于构建更智能、更可靠的AI系统。
📄 摘要(原文)
Despite significant advancements in vision-language models (VLMs), there lacks effective approaches to enhance response quality by scaling inference-time computation. This capability is known to be a core step towards the self-improving models in recent large language model studies. In this paper, we present Vision Value Model (VisVM) that can guide VLM inference-time search to generate responses with better visual comprehension. Specifically, VisVM not only evaluates the generated sentence quality in the current search step, but also anticipates the quality of subsequent sentences that may result from the current step, thus providing a long-term value. In this way, VisVM steers VLMs away from generating sentences prone to hallucinations or insufficient detail, thereby producing higher quality responses. Experimental results demonstrate that VisVM-guided search significantly enhances VLMs' ability to generate descriptive captions with richer visual details and fewer hallucinations, compared with greedy decoding and search methods with other visual reward signals. Furthermore, we find that self-training the model with the VisVM-guided captions improve VLM's performance across a wide range of multimodal benchmarks, indicating the potential for developing self-improving VLMs. Our value model and code are available at https://github.com/si0wang/VisVM.