FLAIR: VLM with Fine-grained Language-informed Image Representations
作者: Rui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, Zeynep Akata, Stephan Alaniz
分类: cs.CV, cs.AI
发布日期: 2024-12-04
🔗 代码/项目: GITHUB
💡 一句话要点
FLAIR:利用细粒度语言信息图像表征的视觉语言模型,提升局部图像内容检索能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 细粒度图像表征 文本条件注意力 图像检索 零样本学习
📋 核心要点
- CLIP等模型在全局层面进行图文匹配,忽略了图像局部细节,限制了其细粒度视觉特征的捕捉能力。
- FLAIR通过采样图像的细粒度描述子标题,学习文本相关的局部图像嵌入,从而提升模型对图像细节的理解。
- 实验表明,FLAIR在多模态检索和细粒度检索任务上均取得了SOTA性能,并在零样本语义分割上超越了更大规模的模型。
📝 摘要(中文)
CLIP在图像和文本对齐方面表现出色,但其捕捉细粒度视觉特征的能力有限,因为它是在全局层面匹配图像和文本。为了解决这个问题,我们提出了FLAIR,即细粒度语言信息图像表征。FLAIR利用长而详细的图像描述来学习局部图像嵌入。通过采样描述图像细粒度细节的各种子标题,我们训练视觉语言模型,使其不仅生成全局嵌入,还生成特定于文本的图像表征。我们的模型在局部图像token之上引入了文本条件注意力池化,以生成擅长检索详细图像内容的细粒度图像表征。我们在现有的多模态检索基准以及我们新引入的细粒度检索任务上实现了最先进的性能,该任务评估视觉语言模型检索部分图像内容的能力。此外,我们的实验证明了FLAIR在3000万图像-文本对上训练后,能够有效捕捉细粒度视觉信息,包括零样本语义分割,优于在数十亿对上训练的模型。代码可在https://github.com/ExplainableML/flair 获取。
🔬 方法详解
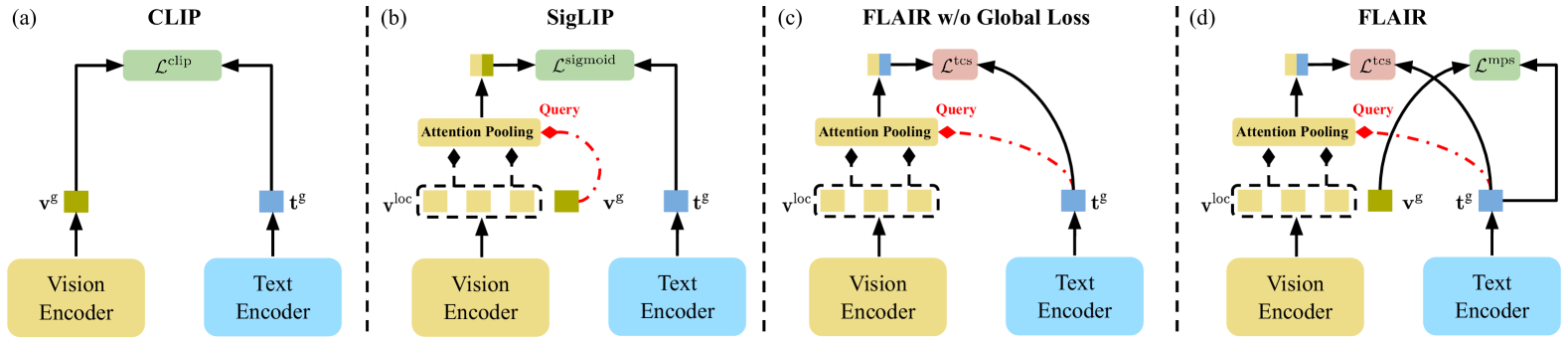
问题定义:现有视觉语言模型(如CLIP)在图像和文本的对齐上取得了显著成果,但它们主要关注全局层面的匹配,忽略了图像中细粒度的局部信息。这导致模型在需要理解和检索图像局部内容时表现不佳。现有方法的痛点在于无法有效利用图像的详细描述信息,从而限制了模型对图像细节的理解能力。
核心思路:FLAIR的核心思路是利用图像的细粒度描述(即详细的图像描述或子标题)来学习局部图像嵌入。通过将图像分解为多个局部区域,并为每个区域生成对应的文本描述,模型可以学习到文本相关的局部图像表征。这样,模型不仅能够理解图像的整体内容,还能够理解图像的局部细节,从而提升其在细粒度图像检索和理解任务中的性能。
技术框架:FLAIR的整体架构包括以下几个主要模块:1) 图像编码器:用于提取图像的局部特征token。2) 文本编码器:用于编码图像的详细描述文本,并采样生成多个子标题。3) 文本条件注意力池化:在图像token之上应用文本条件注意力机制,根据不同的子标题生成不同的局部图像表征。4) 对比学习损失:用于训练模型,使文本描述和对应的局部图像表征在嵌入空间中更加接近。整个流程是,输入图像和对应的详细描述,模型首先提取图像的局部特征和文本特征,然后通过文本条件注意力池化生成细粒度的图像表征,最后通过对比学习损失进行训练。
关键创新:FLAIR最重要的技术创新点在于引入了文本条件注意力池化机制,该机制能够根据不同的文本描述,动态地调整图像局部区域的权重,从而生成特定于文本的局部图像表征。与现有方法相比,FLAIR能够更有效地利用图像的详细描述信息,从而提升模型对图像细节的理解能力。此外,FLAIR还提出了一个新的细粒度检索任务,用于评估视觉语言模型检索部分图像内容的能力。
关键设计:FLAIR的关键设计包括:1) 使用Transformer作为图像和文本编码器。2) 采用对比学习损失(如InfoNCE)来训练模型。3) 设计文本条件注意力池化模块,该模块使用文本嵌入作为query,图像token作为key和value,计算注意力权重,并对图像token进行加权平均。4) 在训练过程中,对图像的详细描述进行采样,生成多个子标题,以增加训练数据的多样性。具体参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片


📊 实验亮点
FLAIR在多个基准测试中取得了显著的性能提升。在现有的多模态检索基准上,FLAIR取得了SOTA性能。在作者提出的细粒度检索任务上,FLAIR也表现出色,证明了其在检索局部图像内容方面的优势。更令人印象深刻的是,FLAIR在仅使用3000万图像-文本对进行训练后,在零样本语义分割任务上超越了在数十亿图像-文本对上训练的模型,突显了其高效学习细粒度视觉信息的能力。
🎯 应用场景
FLAIR在图像检索、图像编辑、视觉问答等领域具有广泛的应用前景。例如,在图像检索中,用户可以通过输入详细的文本描述来检索包含特定局部内容的图像。在图像编辑中,可以根据文本描述对图像的局部区域进行修改。在视觉问答中,模型可以根据问题中的细节信息,更准确地回答关于图像局部内容的问题。未来,FLAIR有望应用于智能安防、自动驾驶、医疗影像分析等领域,提升计算机视觉系统的智能化水平。
📄 摘要(原文)
CLIP has shown impressive results in aligning images and texts at scale. However, its ability to capture detailed visual features remains limited because CLIP matches images and texts at a global level. To address this issue, we propose FLAIR, Fine-grained Language-informed Image Representations, an approach that utilizes long and detailed image descriptions to learn localized image embeddings. By sampling diverse sub-captions that describe fine-grained details about an image, we train our vision-language model to produce not only global embeddings but also text-specific image representations. Our model introduces text-conditioned attention pooling on top of local image tokens to produce fine-grained image representations that excel at retrieving detailed image content. We achieve state-of-the-art performance on both, existing multimodal retrieval benchmarks, as well as, our newly introduced fine-grained retrieval task which evaluates vision-language models' ability to retrieve partial image content. Furthermore, our experiments demonstrate the effectiveness of FLAIR trained on 30M image-text pairs in capturing fine-grained visual information, including zero-shot semantic segmentation, outperforming models trained on billions of pairs. Code is available at https://github.com/ExplainableML/flair .