Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
作者: Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G. Shapiro, Ranjay Krishna
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-12-04 (更新: 2024-12-08)
💡 一句话要点
提出AURORA,通过感知Tokens增强多模态语言模型中的视觉推理能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态语言模型 视觉推理 感知Tokens 深度估计 目标检测 VQVAE 多任务学习
📋 核心要点
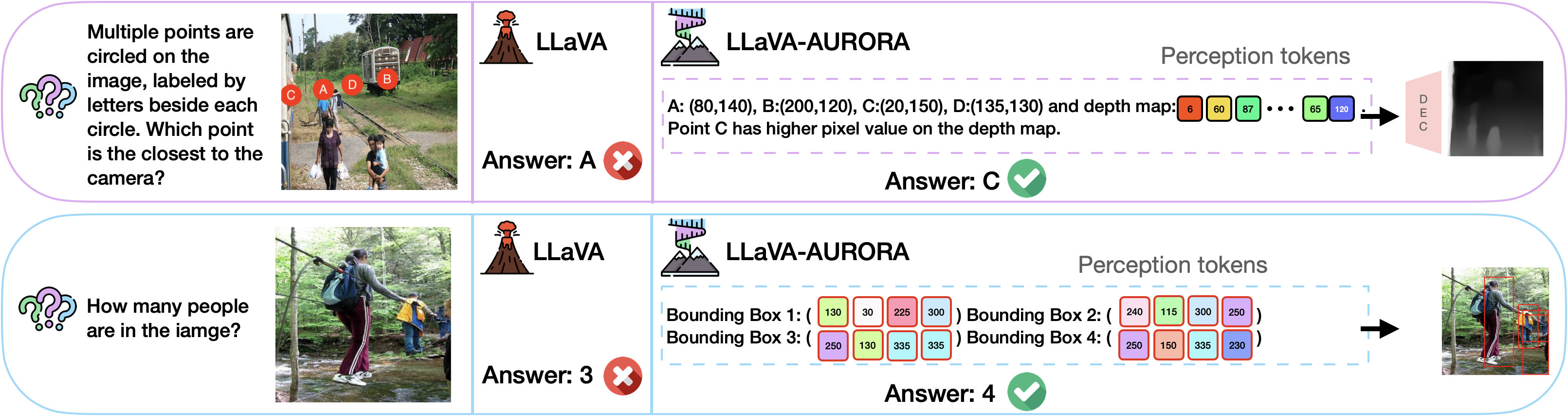
- 多模态语言模型在视觉感知任务中存在不足,尤其是在需要深度估计或目标检测等中间表示的任务中。
- AURORA通过引入感知Tokens,将图像的中间表示(如深度图或边界框)转化为tokens,辅助MLM进行视觉推理。
- 实验表明,AURORA在多个计数和深度估计基准测试中显著优于微调方法,提升了模型的泛化能力。
📝 摘要(中文)
多模态语言模型(MLMs)在基础视觉感知任务中仍面临挑战,而这些任务通常是专用模型的优势。例如,需要推理3D结构的任务受益于深度估计,而推理2D对象实例的任务受益于对象检测。然而,MLMs无法生成中间深度图或边界框来进行推理。在相关数据上微调MLMs泛化能力较差,而将计算外包给专用视觉工具则计算密集且内存效率低下。为了解决这个问题,我们引入了感知Tokens,这是一种旨在辅助语言不足以完成的推理任务的内在图像表示。感知Tokens充当辅助推理tokens,类似于语言模型中的思维链提示。例如,在深度相关任务中,增强了感知tokens的MLM可以通过生成深度图作为tokens来进行推理,从而有效地解决问题。我们提出AURORA,一种通过感知tokens增强MLMs的训练方法,以改进对视觉输入的推理。AURORA利用VQVAE将中间图像表示(如深度图)转换为tokenized格式和边界框tokens,然后将其用于多任务训练框架。AURORA在计数基准测试中取得了显著的改进:在BLINK上+10.8%,在CVBench上+11.3%,在SEED-Bench上+8.3%,优于跨数据集泛化的微调方法。它还在相对深度上有所提高:在BLINK上超过+6%。通过感知tokens,AURORA将MLMs的范围扩展到基于语言的推理之外,为更有效的视觉推理能力铺平了道路。
🔬 方法详解
问题定义:多模态语言模型(MLMs)在视觉感知任务中表现不佳,尤其是在需要中间视觉表示(如深度图、边界框)进行推理的任务中。直接微调MLMs泛化能力差,外包计算给专用视觉工具则计算成本高昂。现有的MLM缺乏利用中间视觉信息进行有效推理的机制。
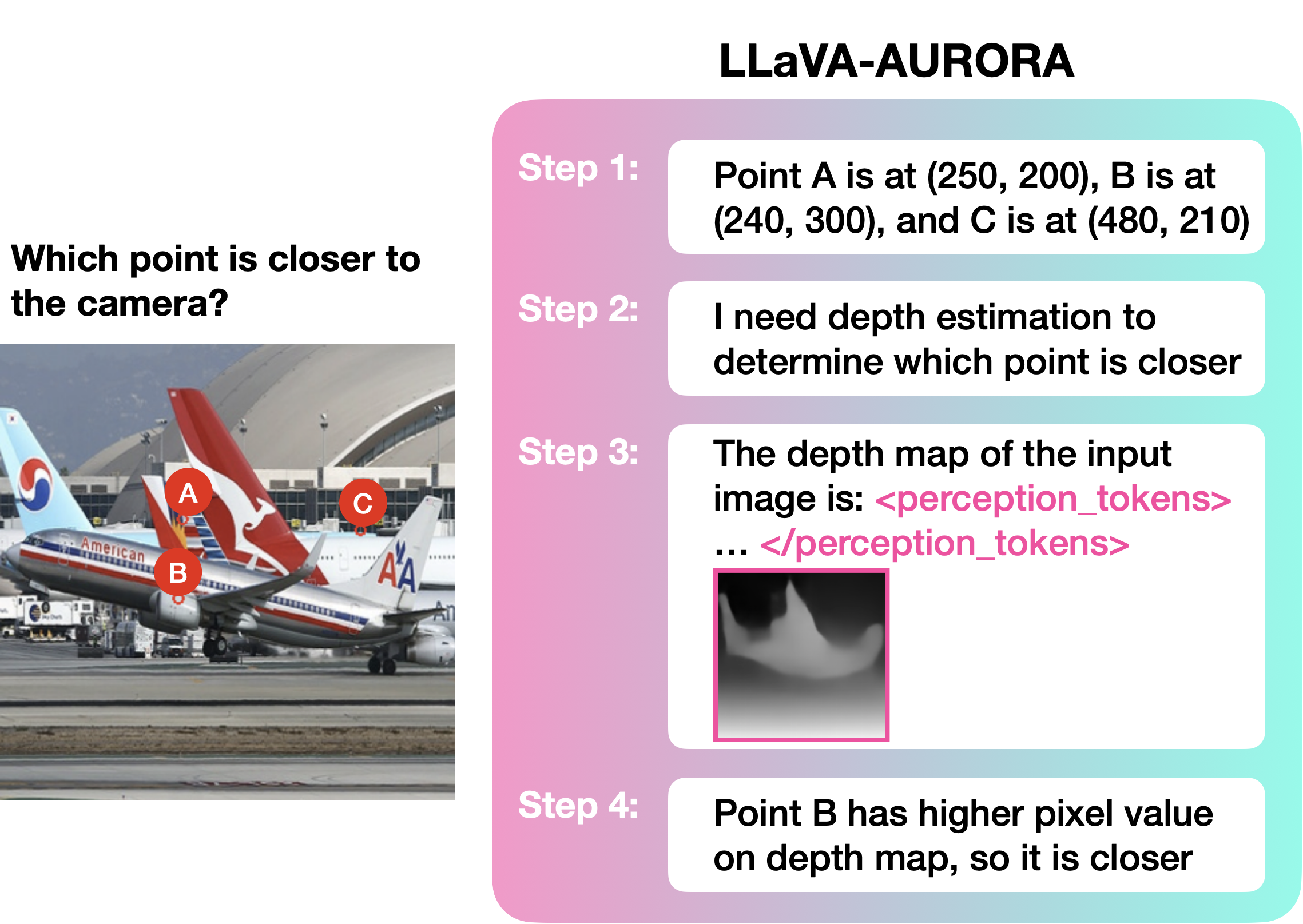
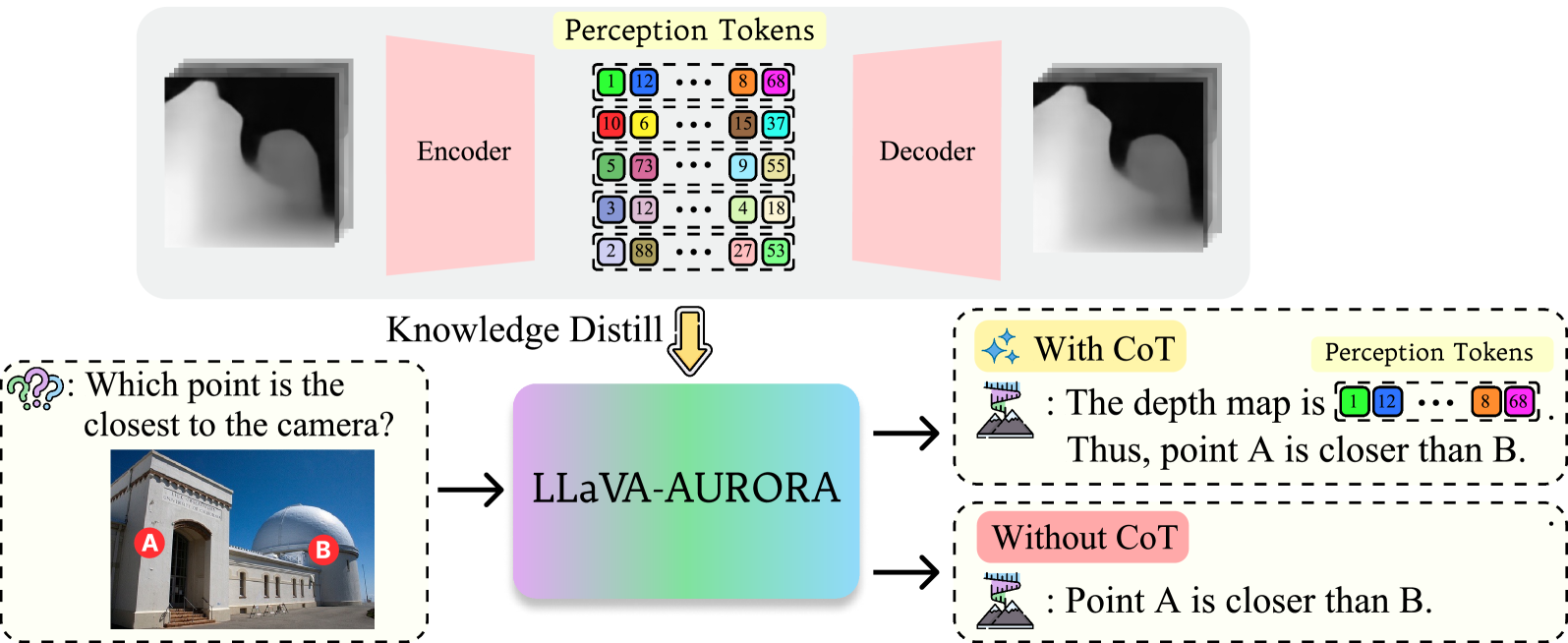
核心思路:核心思想是引入“感知Tokens”,将中间视觉表示(如深度图或边界框)编码成离散的tokens,作为MLM的辅助输入。这些tokens充当视觉推理的“思维链”,帮助MLM更好地理解和处理视觉信息。通过将视觉信息转化为tokens,可以利用MLM强大的语言建模能力进行推理。
技术框架:AURORA框架包含以下几个主要模块:1) 视觉信息编码器:使用VQVAE将中间视觉表示(如深度图或边界框)编码成离散的tokens。2) 多模态语言模型:使用预训练的MLM作为主干网络。3) 感知Tokens注入模块:将视觉tokens注入到MLM的输入序列中。4) 多任务训练框架:同时训练MLM进行语言任务和视觉推理任务。
关键创新:关键创新在于“感知Tokens”的概念,它将中间视觉表示转化为离散的tokens,从而使MLM能够利用这些信息进行推理。与直接微调MLM或外包计算不同,AURORA通过内在的方式增强了MLM的视觉推理能力。此外,AURORA的多任务训练框架也至关重要,它确保MLM能够同时学习语言和视觉信息。
关键设计:VQVAE用于将深度图或边界框等视觉信息编码成tokens。VQVAE的码本大小是一个关键参数,影响着视觉信息的压缩程度和重建质量。多任务训练框架包含语言任务损失和视觉推理任务损失。损失函数的权重需要仔细调整,以平衡语言和视觉任务的学习。
🖼️ 关键图片
📊 实验亮点
AURORA在多个计数基准测试中取得了显著的改进:在BLINK上+10.8%,在CVBench上+11.3%,在SEED-Bench上+8.3%,显著优于微调方法。此外,在相对深度估计任务中,AURORA在BLINK数据集上取得了超过+6%的提升。这些结果表明,AURORA能够有效地增强MLM的视觉推理能力,并提高其在各种视觉任务中的性能。
🎯 应用场景
该研究成果可应用于各种需要视觉推理的多模态任务,例如视觉问答、图像描述、机器人导航等。通过增强MLM的视觉感知能力,可以提高这些任务的性能和鲁棒性。此外,该方法还可以扩展到其他类型的视觉信息,例如分割图、表面法向量等,从而进一步增强MLM的通用性。
📄 摘要(原文)
Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.