AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
作者: Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, Xiangyu Yue
分类: cs.CV, cs.AI, cs.CL, cs.MM, cs.SD, eess.AS
发布日期: 2024-12-03
备注: Project page: https://av-odyssey.github.io/
💡 一句话要点
AV-Odyssey Bench:评估多模态LLM对视听信息理解能力的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视听理解 大型语言模型 基准测试 模型评估
📋 核心要点
- 现有MLLM在视听任务中表现出潜力,但对基本视听信息的理解能力仍有不足,例如分辨音量和音调。
- 提出AV-Odyssey Bench,包含4555个多项选择题,需要模型综合利用文本、视觉和音频信息进行推理。
- 通过基准测试,揭示了现有MLLM在视听理解方面的局限性,为未来模型发展提供指导。
📝 摘要(中文)
近年来,GPT-4o、Gemini 1.5 Pro和Reka Core等大型多模态语言模型(MLLM)已将其能力扩展到视觉和音频模态。尽管这些模型在各种视听应用中表现出令人印象深刻的性能,但我们提出的DeafTest揭示了MLLM在人类看来很简单任务上的不足,例如:1)确定两个声音中哪个更响亮,以及2)确定两个声音中哪个音调更高。受这些观察结果的启发,我们引入了AV-Odyssey Bench,这是一个综合性的视听基准,旨在评估这些MLLM是否真正理解视听信息。该基准包含4,555个精心设计的问题,每个问题都包含文本、视觉和音频组件。为了成功推断答案,模型必须有效地利用来自视觉和音频输入的线索。为了确保对MLLM响应进行精确和客观的评估,我们将问题构建为多项选择题,无需人工评估或LLM辅助评估。我们对一系列闭源和开源模型进行了基准测试,并总结了观察结果。通过揭示当前模型的局限性,我们旨在为未来的数据集收集和模型开发提供有用的见解。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)在处理视听信息时,虽然在一些复杂的应用中表现良好,但在一些基础的视听理解任务上,例如判断声音的响度和音调,却表现出明显的不足。这表明模型可能只是在表面上关联了视听信息,而缺乏真正的理解能力。
核心思路:论文的核心思路是构建一个高质量的视听基准测试集,用于系统性地评估MLLM对视听信息的理解能力。该基准测试集的设计重点在于考察模型是否能够真正理解并整合来自不同模态的信息,而不仅仅是进行简单的模式匹配。
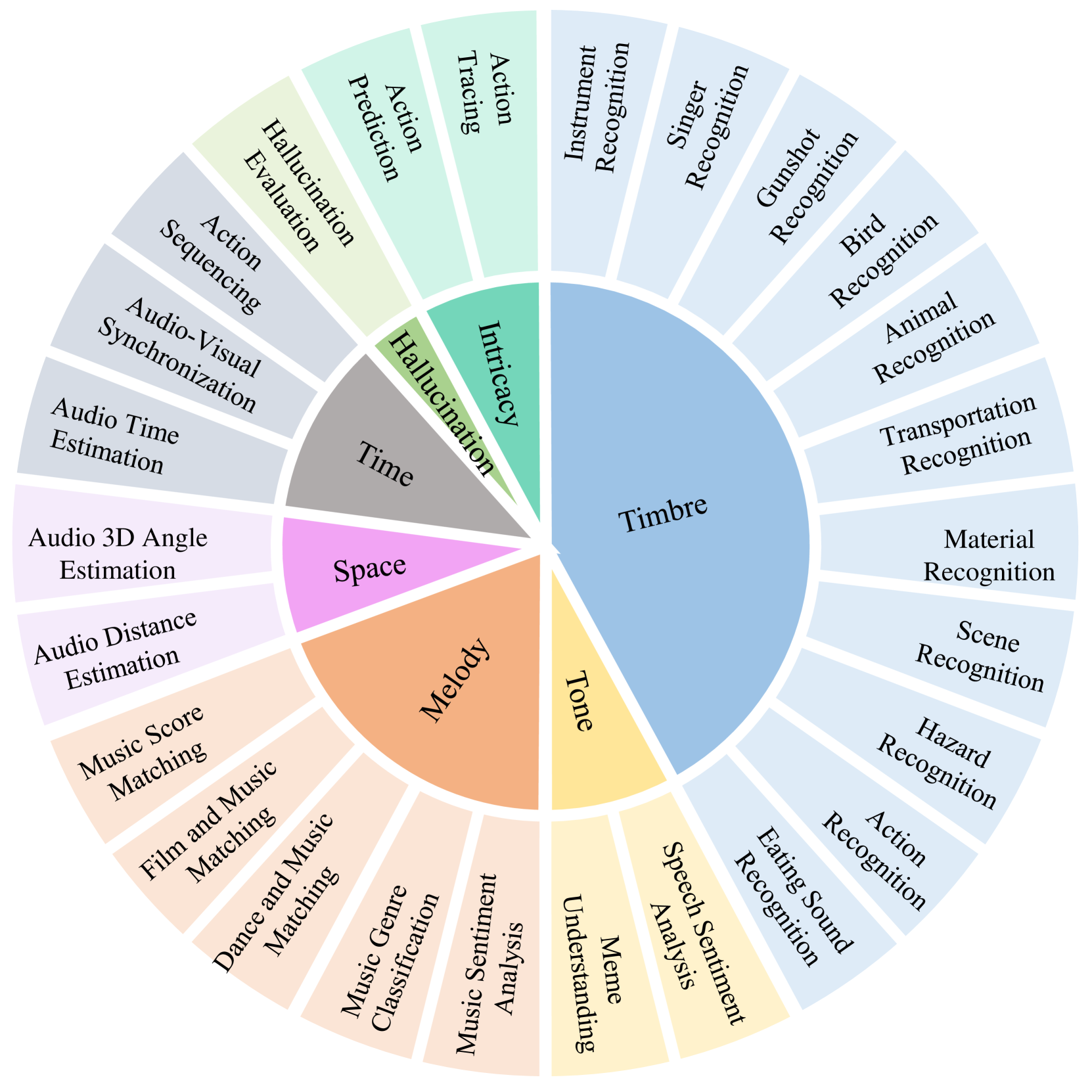
技术框架:AV-Odyssey Bench包含4555个精心设计的多项选择题,每个问题都包含文本描述、视觉信息(图像)和音频信息。模型需要同时利用这三种模态的信息才能正确回答问题。问题的设计涵盖了多种视听理解能力,例如识别物体发出的声音、理解声音与视觉场景的关联等。评估过程采用多项选择题的形式,避免了主观评价,保证了评估的客观性和准确性。
关键创新:该基准测试集的主要创新在于其综合性和客观性。它不仅包含了大量的测试用例,而且每个用例都经过精心设计,能够有效地考察模型对视听信息的理解能力。此外,采用多项选择题的形式,避免了人工评估的主观性,使得评估结果更加可靠。
关键设计:AV-Odyssey Bench的关键设计在于问题的多样性和难度。问题涵盖了各种不同的视听场景和任务,例如识别不同乐器的声音、判断声音的来源方向、理解声音与视觉事件的关联等。问题的难度也经过精心控制,既要能够区分不同模型的性能,又要避免过于简单或过于困难。
🖼️ 关键图片


📊 实验亮点
论文对一系列闭源和开源模型进行了基准测试,结果表明,即使是像GPT-4o这样的先进模型,在AV-Odyssey Bench上也存在明显的不足。这表明现有MLLM在视听理解方面仍有很大的提升空间,也验证了该基准测试集的有效性。
🎯 应用场景
AV-Odyssey Bench可用于评估和提升多模态LLM在机器人、自动驾驶、智能助手等领域的性能。通过该基准,研究人员可以更好地了解现有模型的局限性,并开发更强大的视听理解模型,从而提升相关应用的智能化水平和用户体验。
📄 摘要(原文)
Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities. While these models demonstrate impressive performance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch. Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio-visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components. To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure precise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for human evaluation or LLM-assisted assessment. We benchmark a series of closed-source and open-source models and summarize the observations. By revealing the limitations of current models, we aim to provide useful insight for future dataset collection and model development.