It Takes Two: Real-time Co-Speech Two-person's Interaction Generation via Reactive Auto-regressive Diffusion Model
作者: Mingyi Shi, Dafei Qin, Leo Ho, Zhouyingcheng Liao, Yinghao Huang, Junichi Yamagishi, Taku Komura
分类: cs.SD, cs.CV, cs.GR, cs.MM, eess.AS
发布日期: 2024-12-03
备注: 15 pages, 10 figures
💡 一句话要点
提出基于反应式自回归扩散模型的实时双人对话动作生成方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 双人交互 协同语音动作生成 扩散模型 自回归模型 在线生成 人机交互 动作合成
📋 核心要点
- 现有协同语音动作合成方法难以处理双人对话场景中相互影响的问题,且大多基于离线序列到序列框架,不适用于在线应用。
- 论文提出一种基于扩散模型的自回归系统,通过结合语音、历史动作和任务导向轨迹,实现双人对话中实时、自然的动作生成。
- 通过实验验证,该系统在单人和双人协同语音动作生成以及交互式动作生成等任务中均优于现有方法,实现了在线双人交互动作生成。
📝 摘要(中文)
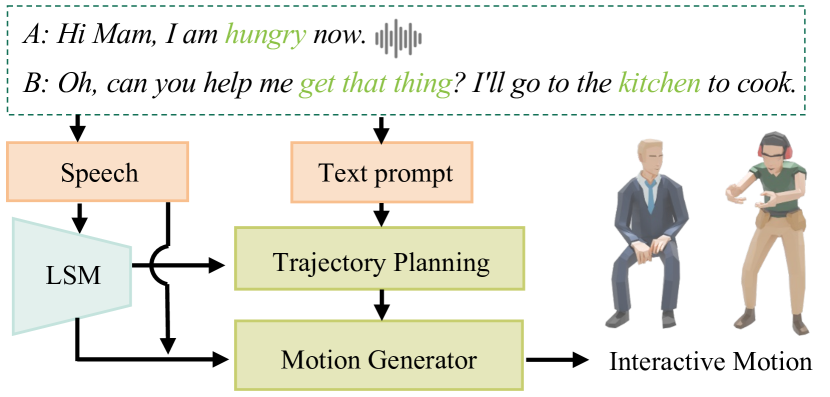
本文提出了一种音频驱动的自回归系统,用于在对话中为两个角色合成动态动作。该方法的核心是一个基于扩散的全身体动作合成模型,它以两个角色的过去状态、语音音频和面向任务的运动轨迹输入为条件,从而实现灵活的空间控制。为了增强模型学习多样化交互的能力,我们利用更具动态性和交互性的动作丰富了现有的双人对话运动数据集。通过多项实验评估,结果表明该系统在单人和双人协同语音动作生成以及交互式动作生成等多种任务中均表现出色。据我们所知,这是第一个能够在线生成双人交互式全身动作的系统。
🔬 方法详解
问题定义:现有协同语音动作生成方法在处理双人对话场景时存在局限性。一方面,它们难以捕捉到对话中个体之间的相互影响,即一个人的语音和动作会影响另一个人的反应。另一方面,大多数方法依赖于离线序列到序列的框架,无法满足实时应用的需求。因此,如何实现能够捕捉双人交互并支持在线生成的协同语音动作是一个关键问题。
核心思路:本文的核心思路是利用自回归扩散模型,以语音、历史动作和任务导向轨迹作为条件,逐步生成双人对话中的动作。自回归的特性使得模型能够捕捉到时序上的依赖关系,从而模拟对话中个体之间的相互影响。扩散模型则能够生成更加自然和多样化的动作。此外,通过面向任务的运动轨迹输入,可以实现对动作的空间控制。
技术框架:该系统主要包含以下几个模块:1) 音频特征提取模块,用于提取语音的声学特征;2) 历史动作编码模块,用于编码两个角色的历史动作状态;3) 任务导向轨迹输入模块,用于提供空间控制信息;4) 基于扩散模型的动作生成模块,该模块以音频特征、历史动作编码和任务导向轨迹为条件,逐步生成新的动作。整个系统采用自回归的方式,即当前生成的动作会作为下一步的输入,从而实现连续的动作生成。
关键创新:该方法最重要的创新点在于将自回归扩散模型应用于双人对话动作生成,并实现了在线生成。与传统的序列到序列模型相比,扩散模型能够生成更加自然和多样化的动作,而自回归的特性则使得模型能够捕捉到对话中个体之间的相互影响。此外,该系统还通过面向任务的运动轨迹输入,实现了对动作的空间控制。
关键设计:在扩散模型的设计上,采用了U-Net结构,并引入了注意力机制,以更好地捕捉音频特征、历史动作和任务导向轨迹之间的关系。损失函数方面,采用了L1损失和对抗损失相结合的方式,以提高生成动作的质量和真实感。为了增强模型学习多样化交互的能力,作者还对现有的双人对话运动数据集进行了扩充,增加了更多动态和交互式的动作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该系统在单人和双人协同语音动作生成以及交互式动作生成等多种任务中均表现出色。与现有方法相比,该系统能够生成更加自然、流畅和具有交互性的动作。此外,该系统还实现了在线生成,能够满足实时应用的需求。具体性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏、社交娱乐等领域,例如创建更具沉浸感和互动性的虚拟角色,提升在线会议和远程协作的真实感,以及为游戏角色赋予更自然的对话动作。未来,该技术有望进一步扩展到更多人、更复杂的社交场景,并与其他AI技术相结合,创造更智能、更人性化的交互体验。
📄 摘要(原文)
Conversational scenarios are very common in real-world settings, yet existing co-speech motion synthesis approaches often fall short in these contexts, where one person's audio and gestures will influence the other's responses. Additionally, most existing methods rely on offline sequence-to-sequence frameworks, which are unsuitable for online applications. In this work, we introduce an audio-driven, auto-regressive system designed to synthesize dynamic movements for two characters during a conversation. At the core of our approach is a diffusion-based full-body motion synthesis model, which is conditioned on the past states of both characters, speech audio, and a task-oriented motion trajectory input, allowing for flexible spatial control. To enhance the model's ability to learn diverse interactions, we have enriched existing two-person conversational motion datasets with more dynamic and interactive motions. We evaluate our system through multiple experiments to show it outperforms across a variety of tasks, including single and two-person co-speech motion generation, as well as interactive motion generation. To the best of our knowledge, this is the first system capable of generating interactive full-body motions for two characters from speech in an online manner.