VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning
作者: Xueqing Wu, Yuheng Ding, Bingxuan Li, Pan Lu, Da Yin, Kai-Wei Chang, Nanyun Peng
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-12-03 (更新: 2025-03-18)
备注: CVPR 2025. https://visco-benchmark.github.io/
💡 一句话要点
提出VISCO基准,用于评估视觉推理中大模型进行细粒度评价与纠正的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 视觉推理 自我改进 细粒度评价 错误纠正 基准测试 LookBack策略
📋 核心要点
- 现有大型视觉语言模型缺乏对自身推理过程进行细粒度评价与纠正的系统性分析。
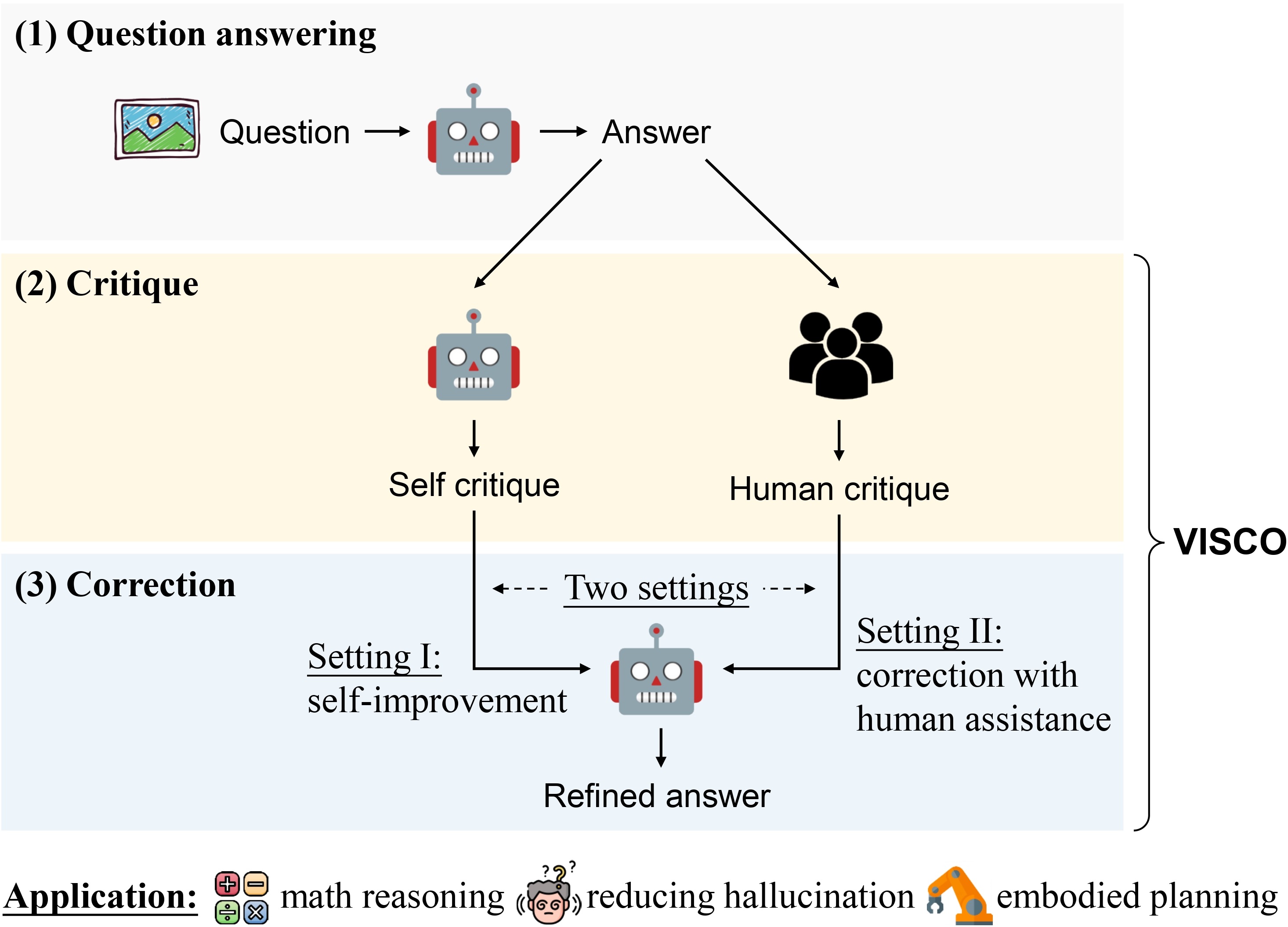
- 论文提出VISCO基准,通过要求模型评估推理链中每一步的正确性并给出解释,实现细粒度评价。
- 实验表明人工评价能显著提升纠正后的性能,但模型自身评价效果不佳,LookBack策略能有效改善评价与纠正。
📝 摘要(中文)
大型视觉语言模型(LVLMs)评价和纠正自身推理的能力是实现自我改进的关键。然而,目前仍缺乏对LVLMs此类能力的系统性分析。我们提出了VISCO,这是第一个全面分析LVLMs细粒度评价和纠正能力的基准。与现有工作中使用单一标量值来评价整个推理过程不同,VISCO具有密集和细粒度的评价,要求LVLMs评估思维链中每个步骤的正确性,并提供自然语言解释来支持其判断。对24个LVLMs的广泛评估表明,人工编写的评价在纠正后显著提高了性能,展示了自我改进策略的潜力。然而,模型生成的评价效果较差,有时甚至会损害性能,这表明评价是关键瓶颈。我们发现了评价失败的三个常见模式:未能评价视觉感知、不愿“说不”以及夸大误差传播的假设。为了解决这些问题,我们提出了一种有效的LookBack策略,该策略重新审视图像以验证初始推理中的每条信息。LookBack显著提高了评价和纠正性能,最高可达13.5%。
🔬 方法详解
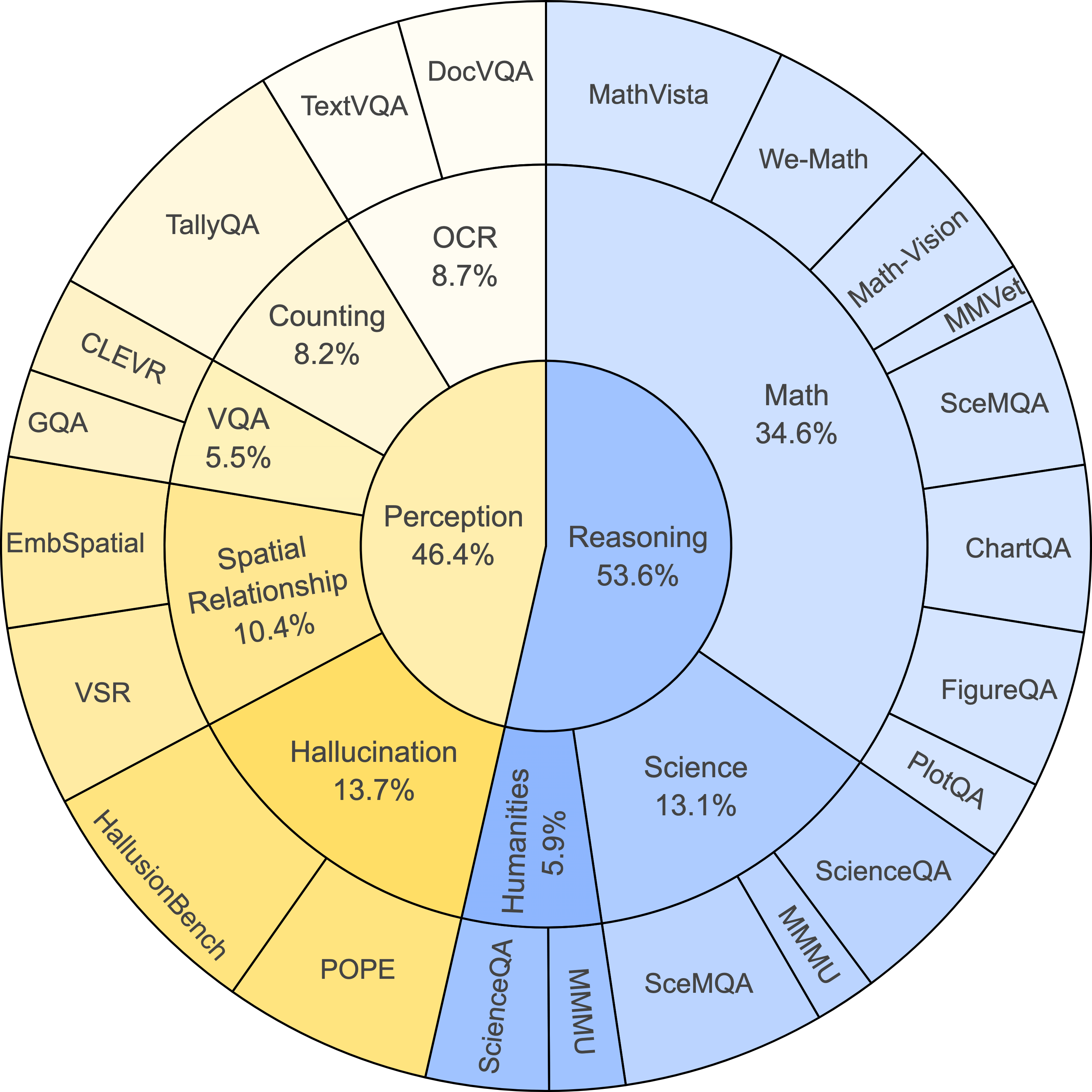
问题定义:现有的大型视觉语言模型(LVLMs)在视觉推理方面取得了显著进展,但它们自我改进的能力仍然有限。一个关键的瓶颈在于缺乏对模型推理过程进行细粒度评价和纠正的能力。现有方法通常使用单一标量值来评估整个推理过程,无法定位到具体的错误步骤,从而限制了模型自我改进的潜力。因此,如何设计一个能够全面评估LVLMs细粒度评价和纠正能力的基准是一个重要的研究问题。
核心思路:论文的核心思路是构建一个名为VISCO的基准,该基准要求LVLMs对思维链(Chain-of-Thought, CoT)推理过程中的每个步骤进行评估,并提供自然语言解释来支持其判断。通过这种细粒度的评价方式,可以更准确地识别出推理过程中的错误,从而为模型提供更有效的纠正指导。此外,论文还提出了一种名为LookBack的策略,该策略通过重新审视图像来验证初始推理中的信息,以提高评价的准确性。
技术框架:VISCO基准主要包含以下几个关键组成部分:1) 视觉推理任务:选择具有挑战性的视觉推理任务作为评估对象。2) 思维链推理过程:为每个任务提供一个思维链推理过程,将推理过程分解为多个步骤。3) 细粒度评价:要求LVLMs对每个推理步骤的正确性进行评估,并提供自然语言解释。4) 纠正机制:根据评价结果,对推理过程进行纠正。5) 评估指标:设计合适的评估指标来衡量LVLMs的评价和纠正能力。LookBack策略则是在评价阶段,让模型重新审视图像,验证每个推理步骤所依赖的视觉信息。
关键创新:论文的主要创新点在于:1) 提出了VISCO基准,这是第一个全面分析LVLMs细粒度评价和纠正能力的基准。2) 引入了LookBack策略,通过重新审视图像来提高评价的准确性。与现有方法相比,VISCO能够更准确地定位到推理过程中的错误,并为模型提供更有效的纠正指导。LookBack策略则通过引入额外的视觉信息,减少了模型在评价过程中可能出现的偏差。
关键设计:LookBack策略的关键设计在于如何有效地利用视觉信息来验证推理步骤。具体来说,该策略要求模型在评价每个推理步骤时,重新审视图像,并验证该步骤所依赖的视觉信息是否正确。例如,如果一个推理步骤涉及到识别图像中的某个物体,那么LookBack策略会要求模型重新确认该物体是否存在于图像中,以及该物体的属性是否与推理步骤中的描述一致。这种设计可以有效地减少模型在评价过程中可能出现的视觉感知错误。
🖼️ 关键图片

📊 实验亮点
实验结果表明,人工编写的评价能够显著提升模型在纠正后的性能,验证了自我改进策略的潜力。然而,模型自身生成的评价效果不佳,表明评价是关键瓶颈。LookBack策略能够显著提高评价和纠正性能,最高可达13.5%,证明了该策略的有效性。
🎯 应用场景
该研究成果可应用于提升视觉语言模型的可靠性和可解释性,例如在自动驾驶、医疗诊断、智能客服等领域,帮助模型更好地理解图像信息并进行准确推理,从而做出更可靠的决策。未来可进一步探索如何利用该基准和方法来训练更强大的自纠正视觉语言模型。
📄 摘要(原文)
The ability of large vision-language models (LVLMs) to critique and correct their reasoning is an essential building block towards their self-improvement. However, a systematic analysis of such capabilities in LVLMs is still lacking. We propose VISCO, the first benchmark to extensively analyze the fine-grained critique and correction capabilities of LVLMs. Compared to existing work that uses a single scalar value to critique the entire reasoning [4], VISCO features dense and fine-grained critique, requiring LVLMs to evaluate the correctness of each step in the chain-of-thought and provide natural language explanations to support their judgments. Extensive evaluation of 24 LVLMs demonstrates that human-written critiques significantly enhance the performance after correction, showcasing the potential of the self-improvement strategy. However, the model-generated critiques are less helpful and sometimes detrimental to the performance, suggesting that critique is the crucial bottleneck. We identified three common patterns in critique failures: failure to critique visual perception, reluctance to "say no", and exaggerated assumption of error propagation. To address these issues, we propose an effective LookBack strategy that revisits the image to verify each piece of information in the initial reasoning. LookBack significantly improves critique and correction performance by up to 13.5%.