WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image
作者: Yuci Liang, Xinheng Lyu, Wenting Chen, Meidan Ding, Jipeng Zhang, Xiangjian He, Song Wu, Xiaohan Xing, Sen Yang, Xiyue Wang, Linlin Shen
分类: cs.CV, cs.CL
发布日期: 2024-12-03 (更新: 2025-08-12)
备注: ICCV 2025, 38 pages, 22 figures, 35 tables
💡 一句话要点
WSI-LLaVA:用于全切片图像理解的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全切片图像 多模态大语言模型 计算病理学 形态学分析 病理诊断
📋 核心要点
- 现有patch级别MLLM无法全面分析WSI,且忽略关键形态学特征,限制了诊断准确性。
- WSI-LLaVA通过三阶段训练,实现WSI-文本对齐、特征空间对齐和任务指令微调,提升模型性能。
- 实验表明,WSI-LLaVA在形态学分析方面显著优于现有模型,并提升了诊断准确性。
📝 摘要(中文)
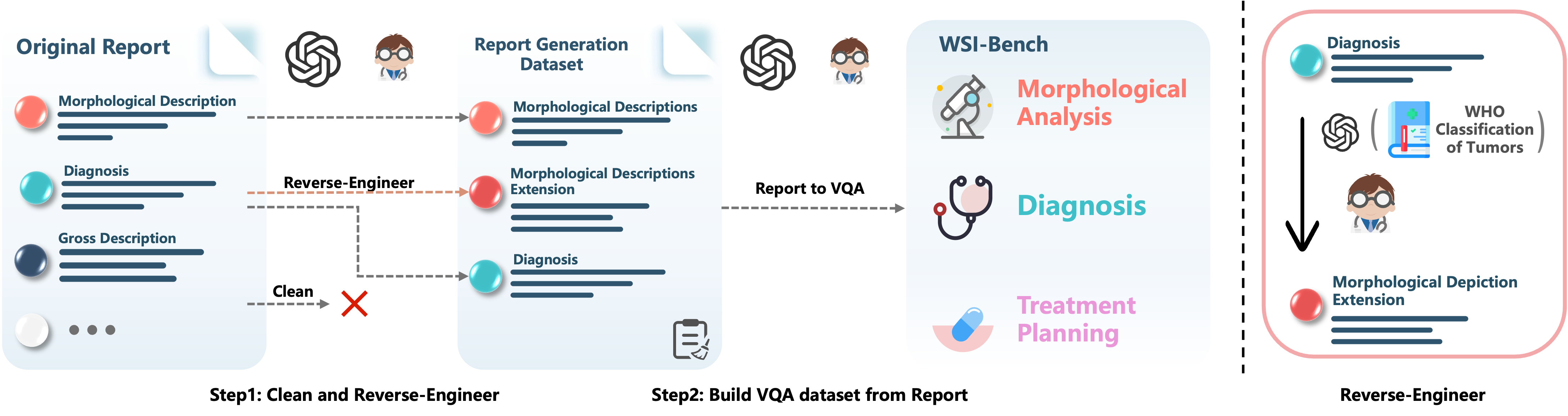
计算病理学的最新进展催生了patch级别的多模态大语言模型(MLLM),但这些模型无法全面分析全切片图像(WSI),并且容易忽略病理学家用于诊断的关键形态学特征。为了解决这些挑战,我们首先推出了WSI-Bench,这是一个大规模的形态学感知基准,包含来自30种癌症类型的9,850张WSI的18万个VQA对,旨在评估MLLM对准确诊断至关重要的形态学特征的理解。在此基准的基础上,我们提出了WSI-LLaVA,这是一个用于千兆像素WSI理解的新框架,它采用三阶段训练方法:WSI-文本对齐、特征空间对齐和特定任务的指令微调。为了更好地评估模型在病理学环境中的性能,我们开发了两个专门的WSI指标:WSI-Precision和WSI-Relevance。实验结果表明,WSI-LLaVA在所有能力维度上均优于现有模型,尤其在形态学分析方面有显著改进,从而建立了形态学理解与诊断准确性之间的明确相关性。
🔬 方法详解
问题定义:现有方法主要集中在patch级别的分析,无法有效利用全切片图像的全局信息。同时,现有模型对病理诊断中至关重要的形态学特征的理解不足,导致诊断准确率受限。现有方法缺乏针对WSI的专门评估指标,难以客观评价模型性能。
核心思路:WSI-LLaVA的核心思路是通过多阶段训练,使模型能够理解WSI的全局信息,并关注重要的形态学特征。通过WSI-Bench基准数据集的训练,模型能够学习到形态学特征与诊断结果之间的关系。同时,引入WSI-Precision和WSI-Relevance指标,更准确地评估模型在病理学任务中的性能。
技术框架:WSI-LLaVA采用三阶段训练框架。第一阶段是WSI-文本对齐,旨在将WSI的视觉信息与文本描述对齐。第二阶段是特征空间对齐,通过对齐视觉和文本特征空间,增强模型的多模态理解能力。第三阶段是任务特定指令微调,针对特定的病理诊断任务,对模型进行微调,以提高诊断准确率。
关键创新:WSI-LLaVA的关键创新在于其针对WSI的全局理解能力和对形态学特征的关注。通过WSI-Bench基准数据集的训练,模型能够学习到形态学特征与诊断结果之间的关系。此外,WSI-Precision和WSI-Relevance指标的引入,为WSI模型的评估提供了更准确的手段。
关键设计:WSI-LLaVA使用预训练的视觉编码器提取WSI的视觉特征,并使用预训练的语言模型处理文本描述。在WSI-文本对齐阶段,使用对比学习损失函数,使模型能够学习到WSI和文本之间的对应关系。在特征空间对齐阶段,使用KL散度损失函数,对齐视觉和文本特征空间。在任务特定指令微调阶段,使用交叉熵损失函数,优化模型在特定诊断任务上的性能。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片


📊 实验亮点
WSI-LLaVA在WSI-Bench基准测试中,在所有能力维度上均优于现有模型。尤其在形态学分析方面,WSI-LLaVA取得了显著的改进,证明了形态学理解与诊断准确性之间的明确相关性。具体性能数据和对比基线在论文中有详细描述,此处未知。
🎯 应用场景
WSI-LLaVA可应用于辅助病理诊断、远程病理会诊、病理学研究等领域。该模型能够帮助病理学家更准确、高效地分析WSI,提高诊断准确率,减少误诊率。此外,该模型还可以用于病理学教学和培训,帮助学生和医生更好地理解病理学知识。
📄 摘要(原文)
Recent advancements in computational pathology have produced patch-level Multi-modal Large Language Models (MLLMs), but these models are limited by their inability to analyze whole slide images (WSIs) comprehensively and their tendency to bypass crucial morphological features that pathologists rely on for diagnosis. To address these challenges, we first introduce WSI-Bench, a large-scale morphology-aware benchmark containing 180k VQA pairs from 9,850 WSIs across 30 cancer types, designed to evaluate MLLMs' understanding of morphological characteristics crucial for accurate diagnosis. Building upon this benchmark, we present WSI-LLaVA, a novel framework for gigapixel WSI understanding that employs a three-stage training approach: WSI-text alignment, feature space alignment, and task-specific instruction tuning. To better assess model performance in pathological contexts, we develop two specialized WSI metrics: WSI-Precision and WSI-Relevance. Experimental results demonstrate that WSI-LLaVA outperforms existing models across all capability dimensions, with a significant improvement in morphological analysis, establishing a clear correlation between morphological understanding and diagnostic accuracy.