COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training
作者: Sanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, Stephan Alaniz, Zeynep Akata
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-02 (更新: 2025-03-26)
备注: CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
COSMOS:跨模态自蒸馏视觉语言预训练,提升下游任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言预训练 跨模态学习 自蒸馏 对比学习 多模态增强 跨注意力机制 零样本学习
📋 核心要点
- 现有VLM依赖对比损失,易忽略图像背景信息,限制了模型在下游任务中的表现。
- COSMOS通过跨模态自蒸馏,结合文本裁剪策略和跨注意力模块,学习更全面的跨模态表示。
- 实验表明,COSMOS在零样本下游任务上超越了现有基线,并在视觉感知和上下文理解方面优于CLIP。
📝 摘要(中文)
本文提出COSMOS:一种用于视觉语言预训练的跨模态自蒸馏方法。现有的基于对比损失的视觉语言模型(VLM)主要关注前景对象,忽略了图像中的其他重要信息,限制了其在下游任务中的有效性。为了解决这个问题,COSMOS将一种新颖的文本裁剪策略和跨注意力模块集成到自监督学习框架中。通过创建图像和文本的全局和局部视图(即多模态增强),为VLM中的自蒸馏提供基础。此外,引入跨注意力模块,使COSMOS能够学习通过跨模态自蒸馏损失优化的全面跨模态表示。COSMOS在各种零样本下游任务(包括检索、分类和语义分割)上始终优于先前的强大基线。此外,在视觉感知和上下文理解任务中,它超越了在更大数据集上训练的基于CLIP的模型。代码已开源。
🔬 方法详解
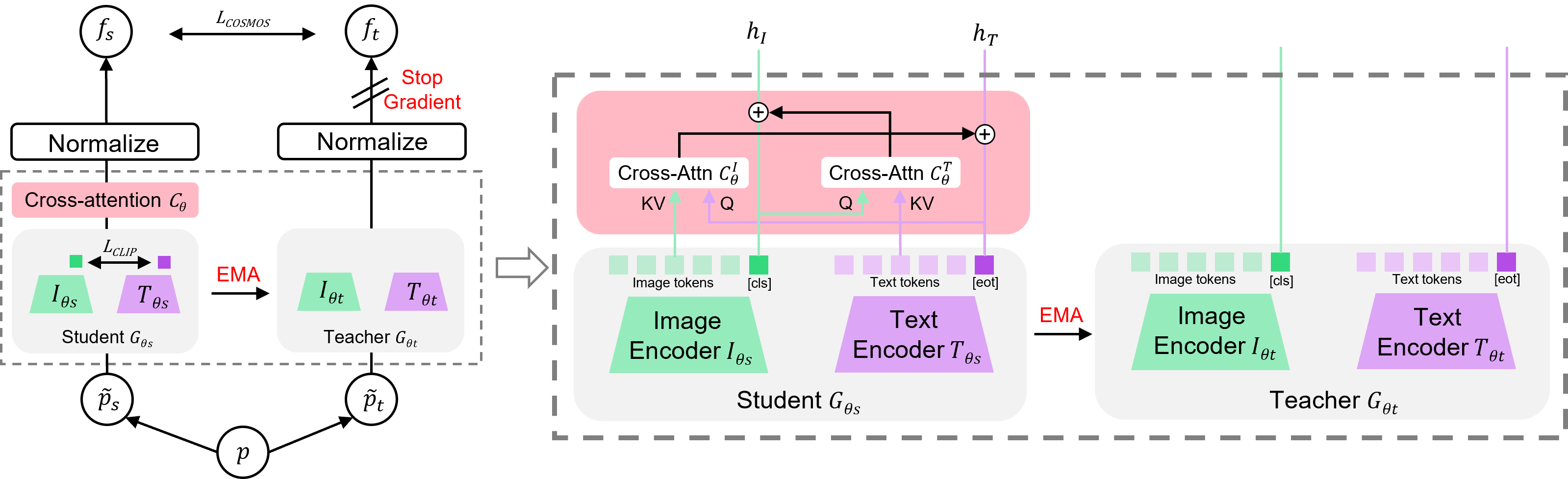
问题定义:现有的视觉语言模型(VLMs),特别是那些使用对比损失训练的模型,在各种视觉和语言任务中取得了显著进展。然而,对比损失的全局性质导致这些模型主要关注图像中的前景对象,而忽略了其他重要的上下文信息。这种对背景信息的忽视限制了它们在需要更细粒度理解的下游任务中的有效性。因此,需要一种方法来使VLMs能够学习更全面的图像表示,包括前景和背景信息。
核心思路:COSMOS的核心思路是通过跨模态自蒸馏来增强VLM的学习能力。具体来说,它创建图像和文本的全局和局部视图(多模态增强),并利用这些视图进行自蒸馏。通过让模型学习从自身的全局视图中提炼局部视图的信息,以及反过来,模型能够更好地捕捉图像和文本中的细粒度信息和上下文关系。此外,引入跨注意力模块,促进不同模态之间的信息交互。
技术框架:COSMOS的整体框架包括以下几个关键模块:1) 多模态增强模块:用于生成图像和文本的全局和局部视图。对于图像,可以使用裁剪、缩放等操作;对于文本,可以使用文本裁剪策略。2) 跨注意力模块:用于在视觉和语言模态之间进行信息交互,从而学习更丰富的跨模态表示。3) 自蒸馏损失:用于指导模型学习从自身的全局视图中提炼局部视图的信息,以及反过来。整个流程可以概括为:输入图像和文本 -> 多模态增强 -> 特征提取 -> 跨注意力交互 -> 自蒸馏损失计算 -> 模型更新。
关键创新:COSMOS的关键创新在于其跨模态自蒸馏框架,该框架结合了多模态增强和跨注意力机制。与传统的对比学习方法不同,COSMOS不仅关注全局的图像-文本对齐,还关注局部视图之间的信息一致性。这种自蒸馏方法能够有效地利用未标注数据,提高模型的泛化能力。此外,文本裁剪策略也是一个创新点,它允许模型关注文本中的不同部分,从而更好地理解图像内容。
关键设计:COSMOS的关键设计包括:1) 文本裁剪策略:具体实现方式未知,但其目的是生成文本的局部视图,以便与图像的局部区域对齐。2) 跨注意力模块:具体实现方式未知,但其目的是促进视觉和语言模态之间的信息交互。3) 自蒸馏损失:具体形式未知,但其目的是鼓励模型学习从自身的全局视图中提炼局部视图的信息,以及反过来。损失函数的权重设置也是一个重要的技术细节,需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
COSMOS在多个零样本下游任务上取得了显著的性能提升。例如,在图像检索任务中,COSMOS优于先前的强大基线。在视觉感知和上下文理解任务中,COSMOS超越了在更大数据集上训练的基于CLIP的模型。这些实验结果表明,COSMOS能够有效地学习更全面的图像表示,并提高模型的泛化能力。具体的性能数据和提升幅度可以在论文原文中找到。
🎯 应用场景
COSMOS具有广泛的应用前景,包括图像检索、图像分类、语义分割、视觉问答等。通过学习更全面的图像表示,COSMOS可以提高这些任务的性能。此外,COSMOS还可以应用于机器人视觉、自动驾驶等领域,帮助机器人更好地理解周围环境。该研究的未来影响在于推动视觉语言模型的进一步发展,使其能够更好地理解和利用多模态信息。
📄 摘要(原文)
Vision-Language Models (VLMs) trained with contrastive loss have achieved significant advancements in various vision and language tasks. However, the global nature of the contrastive loss makes VLMs focus predominantly on foreground objects, neglecting other crucial information in the image, which limits their effectiveness in downstream tasks. To address these challenges, we propose COSMOS: CrOSs-MOdality Self-distillation for vision-language pre-training that integrates a novel text-cropping strategy and cross-attention module into a self-supervised learning framework. We create global and local views of images and texts (i.e., multi-modal augmentations), which are essential for self-distillation in VLMs. We further introduce a cross-attention module, enabling COSMOS to learn comprehensive cross-modal representations optimized via a cross-modality self-distillation loss. COSMOS consistently outperforms previous strong baselines on various zero-shot downstream tasks, including retrieval, classification, and semantic segmentation. Additionally, it surpasses CLIP-based models trained on larger datasets in visual perception and contextual understanding tasks. Code is available at https://github.com/ExplainableML/cosmos.