CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion
作者: Kai He, Chin-Hsuan Wu, Igor Gilitschenski
分类: cs.CV, cs.GR
发布日期: 2024-12-02
备注: Project page: https://ihe-kaii.github.io/CTRL-D/
💡 一句话要点
CTRL-D:基于个性化2D扩散模型的可控动态3D场景编辑
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态3D场景编辑 神经辐射场 3D高斯溅射 扩散模型 InstructPix2Pix 可控编辑
📋 核心要点
- 现有动态3D场景编辑方法受限于编辑骨干网络,导致编辑不一致和可控性不足。
- 该方法通过微调InstructPix2Pix模型,从单张参考图像学习编辑能力,实现精确局部编辑。
- 提出的两阶段优化和编辑图像缓冲区加速收敛,提升时间一致性,实现高质量编辑。
📝 摘要(中文)
本文提出了一种新颖的框架,用于实现动态3D场景中可控且一致的编辑。该框架首先微调InstructPix2Pix模型,然后基于可变形3D高斯模型对场景进行两阶段优化。通过微调,模型能够从单个编辑后的参考图像中“学习”编辑能力,从而将复杂的动态场景编辑任务转化为简单的2D图像编辑过程。通过直接从参考图像中学习编辑区域和风格,该方法能够实现一致且精确的局部编辑,无需跟踪所需的编辑区域,有效解决了动态场景编辑中的关键挑战。随后,两阶段优化逐步编辑训练好的动态场景,并使用设计的编辑图像缓冲区来加速收敛并提高时间一致性。与最先进的方法相比,该方法提供了更灵活和可控的局部场景编辑,实现了高质量和一致的结果。
🔬 方法详解
问题定义:动态3D场景编辑旨在修改场景内容,同时保持时间一致性和场景的真实感。现有方法通常依赖于特定的编辑骨干网络,这限制了编辑的灵活性和可控性,并且难以保证编辑结果在时间上的连贯性。此外,精确控制编辑区域也是一个挑战。
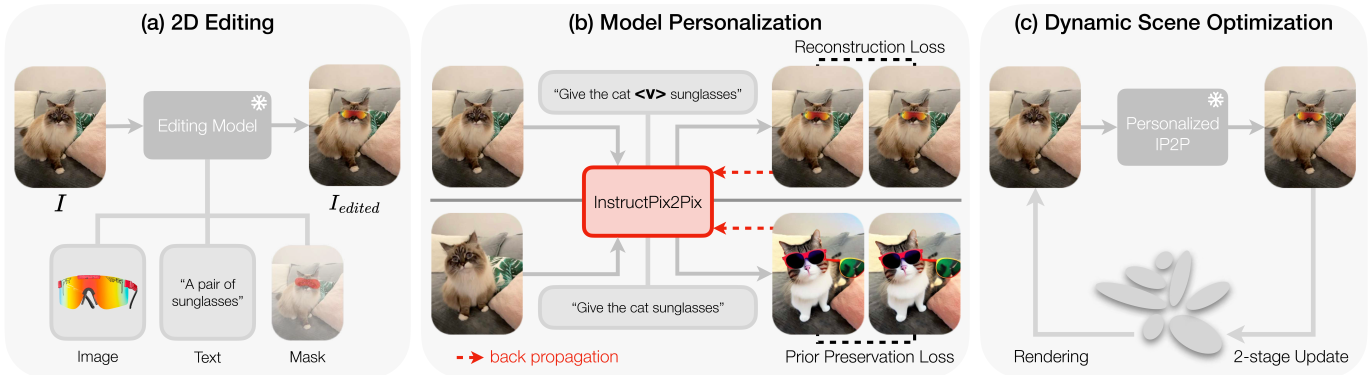
核心思路:本文的核心思路是将复杂的动态3D场景编辑问题转化为一个更易于处理的2D图像编辑问题。通过利用预训练的InstructPix2Pix模型,并对其进行微调,使其能够从单个编辑后的参考图像中学习所需的编辑风格和区域。然后,将2D编辑的结果反向投影到3D场景中,并对3D高斯模型进行优化,从而实现对动态场景的编辑。
技术框架:该框架包含两个主要阶段:1) InstructPix2Pix模型微调:使用编辑后的参考图像对InstructPix2Pix模型进行微调,使其能够理解用户的编辑意图。2) 两阶段场景优化:首先,使用微调后的InstructPix2Pix模型生成一系列编辑后的图像,然后使用这些图像作为监督信号,对3D高斯模型进行优化。该优化过程分为两个阶段:第一阶段侧重于快速收敛,第二阶段侧重于提高时间一致性。
关键创新:该方法最重要的创新点在于将动态3D场景编辑问题解耦为2D图像编辑和3D场景优化两个步骤。通过利用预训练的2D扩散模型,该方法能够实现更灵活和可控的编辑,并且能够更好地保持时间一致性。与现有方法相比,该方法不需要手动跟踪编辑区域,而是直接从参考图像中学习编辑区域和风格。
关键设计:在InstructPix2Pix模型微调阶段,使用了少量编辑后的参考图像进行微调,以避免过拟合。在两阶段场景优化阶段,设计了一个编辑图像缓冲区,用于存储最近编辑的图像,并将其作为监督信号,以加速收敛并提高时间一致性。损失函数包括图像重建损失、时间一致性损失和正则化项。
🖼️ 关键图片


📊 实验亮点
该方法在动态3D场景编辑任务上取得了显著的成果。与现有方法相比,该方法能够实现更灵活和可控的局部编辑,并且能够更好地保持时间一致性。实验结果表明,该方法生成的编辑后的场景具有更高的质量和更强的真实感。具体性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发、虚拟现实和增强现实等领域,实现对动态3D场景的快速、可控和高质量编辑。例如,可以用于修改虚拟角色的外观、改变场景的光照条件或添加新的物体。该技术还可以用于创建个性化的3D内容,例如定制化的虚拟化身或虚拟场景。
📄 摘要(原文)
Recent advances in 3D representations, such as Neural Radiance Fields and 3D Gaussian Splatting, have greatly improved realistic scene modeling and novel-view synthesis. However, achieving controllable and consistent editing in dynamic 3D scenes remains a significant challenge. Previous work is largely constrained by its editing backbones, resulting in inconsistent edits and limited controllability. In our work, we introduce a novel framework that first fine-tunes the InstructPix2Pix model, followed by a two-stage optimization of the scene based on deformable 3D Gaussians. Our fine-tuning enables the model to "learn" the editing ability from a single edited reference image, transforming the complex task of dynamic scene editing into a simple 2D image editing process. By directly learning editing regions and styles from the reference, our approach enables consistent and precise local edits without the need for tracking desired editing regions, effectively addressing key challenges in dynamic scene editing. Then, our two-stage optimization progressively edits the trained dynamic scene, using a designed edited image buffer to accelerate convergence and improve temporal consistency. Compared to state-of-the-art methods, our approach offers more flexible and controllable local scene editing, achieving high-quality and consistent results.