VideoSAVi: Self-Aligned Video Language Models without Human Supervision
作者: Yogesh Kulkarni, Pooyan Fazli
分类: cs.CV
发布日期: 2024-12-01 (更新: 2025-08-09)
备注: COLM 2025
💡 一句话要点
提出VideoSAVi,无需人工标注实现视频语言模型的自对齐训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语言模型 自监督学习 自对齐 直接偏好优化 视频理解
📋 核心要点
- 现有Video-LLM依赖人工标注或API生成偏好数据,成本高昂且效率低下。
- VideoSAVi通过自批评机制生成偏好对,利用DPO进行迭代训练,实现自对齐。
- 实验表明,VideoSAVi在多个视频理解基准测试中显著优于基线模型。
📝 摘要(中文)
视频大语言模型(Video-LLM)的最新进展显著提升了视频理解能力。现有的偏好优化方法通常依赖于专有API或人工标注的字幕来生成偏好数据(即,模型输出的质量或与人类判断对齐的排序对),然后用于训练模型以进行视频-语言对齐。这种方法既昂贵又费力。为了解决这个限制,我们引入了VideoSAVi(自对齐视频语言模型),这是一种自训练流程,使Video-LLM能够从视频内容中学习,而无需外部监督。我们的方法包括一种自我批评机制,该机制识别模型初始响应中的推理错误并生成改进的替代方案,直接从视频内容创建偏好对。然后,VideoSAVi应用直接偏好优化(DPO)来迭代地使用偏好数据训练模型,从而增强其用于视频理解的时间和空间推理。实验表明,与基线模型相比,VideoSAVi在多个基准测试中实现了显着改进,包括在MVBench上提高了+4.2个百分点,在PerceptionTest上提高了+3.9个百分点,在具有挑战性的EgoSchema数据集上提高了+6.8个百分点。我们的模型无关方法在计算上是高效的,仅需要32帧,为无需依赖外部模型或注释的自对齐视频理解提供了一个有希望的方向。
🔬 方法详解
问题定义:现有视频语言模型训练依赖于人工标注或专有API提供的偏好数据,这些数据用于指导模型学习视频内容与语言描述之间的对齐关系。然而,人工标注成本高昂,且专有API的使用受到限制。因此,如何降低对人工标注的依赖,实现视频语言模型的自监督训练是一个关键问题。
核心思路:VideoSAVi的核心思路是通过模型的自我批评机制,自动生成偏好数据,并利用这些数据进行模型的迭代训练。具体来说,模型首先对视频内容生成初始的语言描述,然后通过自我批评模块评估这些描述的质量,并生成改进的替代方案。这些原始描述和改进后的描述构成偏好对,用于训练模型。
技术框架:VideoSAVi的整体框架包含以下几个主要阶段:1) 初始响应生成:模型根据输入的视频内容生成初始的语言描述。2) 自我批评:自我批评模块评估初始响应的质量,并识别其中的推理错误。3) 替代方案生成:基于自我批评的结果,生成改进的替代方案。4) 偏好数据构建:将初始响应和改进后的替代方案构成偏好对。5) 直接偏好优化(DPO):使用偏好数据训练模型,优化模型参数。
关键创新:VideoSAVi最重要的技术创新点在于其自我批评机制,该机制能够自动识别模型生成的语言描述中的错误,并生成改进的替代方案。这种自我学习的方式避免了对人工标注的依赖,降低了训练成本。与现有方法相比,VideoSAVi能够直接从视频内容中学习,无需外部监督信号。
关键设计:VideoSAVi采用32帧作为输入,以保证计算效率。自我批评模块的设计至关重要,它需要能够准确地评估模型生成的语言描述的质量。直接偏好优化(DPO)被用于模型的训练,DPO是一种有效的偏好学习算法,能够直接优化模型的偏好排序能力。具体的损失函数和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

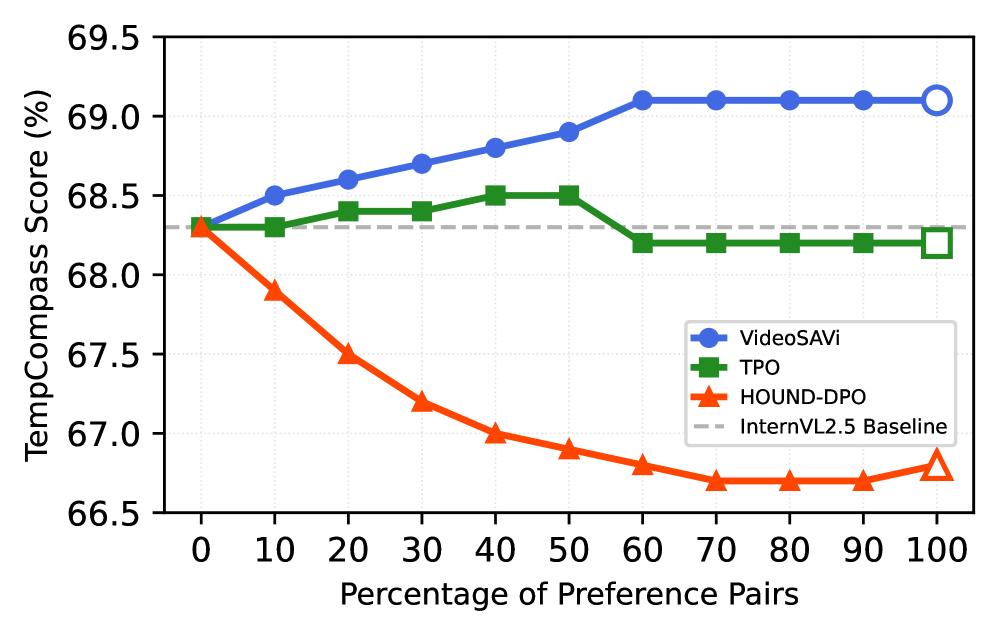
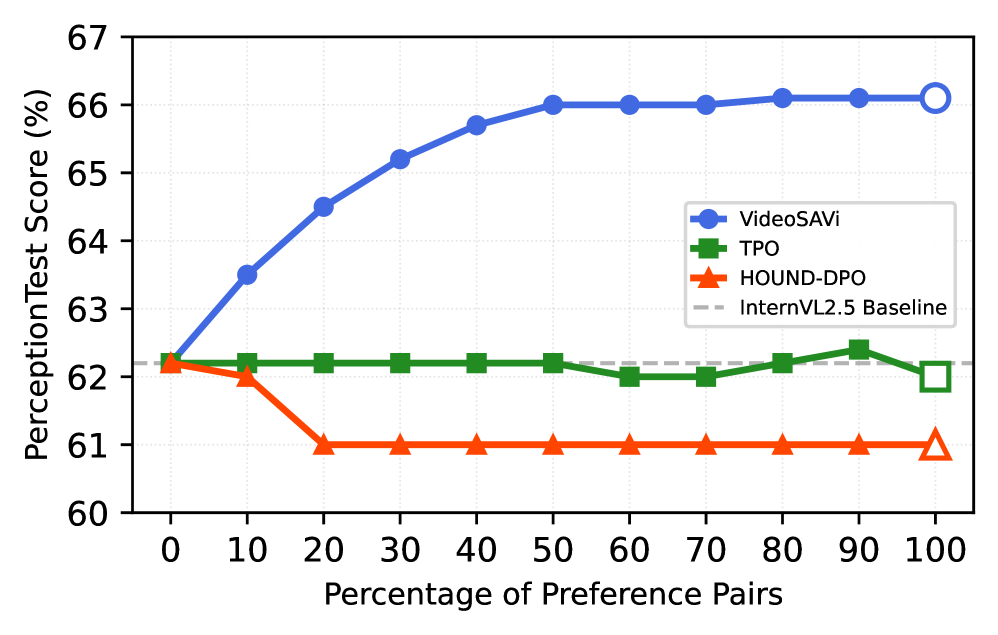
📊 实验亮点
VideoSAVi在多个视频理解基准测试中取得了显著的性能提升。在MVBench上,VideoSAVi的性能提升了+4.2个百分点;在PerceptionTest上,性能提升了+3.9个百分点;在EgoSchema数据集上,性能提升了+6.8个百分点。这些结果表明,VideoSAVi能够有效地提高视频语言模型的理解能力,并且具有良好的泛化性能。
🎯 应用场景
VideoSAVi具有广泛的应用前景,例如智能视频监控、自动驾驶、机器人导航等领域。它可以用于提升机器对视频内容的理解能力,从而实现更智能化的决策和控制。此外,VideoSAVi还可以应用于视频内容生成、视频摘要等任务,提高内容创作的效率和质量。该研究有望推动视频理解技术的发展,促进人工智能在各个领域的应用。
📄 摘要(原文)
Recent advances in video-large language models (Video-LLMs) have led to significant progress in video understanding. Current preference optimization methods often rely on proprietary APIs or human-annotated captions to generate preference data (i.e., pairs of model outputs ranked by quality or alignment with human judgment), which is then used to train models for video-language alignment. This approach is both costly and labor-intensive. To address this limitation, we introduce VideoSAVi (Self-Aligned Video Language Model), a self-training pipeline that enables Video-LLMs to learn from video content without external supervision. Our approach includes a self-critiquing mechanism that identifies reasoning errors in the model's initial responses and generates improved alternatives, creating preference pairs directly from video content. VideoSAVi then applies Direct Preference Optimization (DPO) to iteratively train the model using the preference data, thus enhancing its temporal and spatial reasoning for video understanding. Experiments show that VideoSAVi delivers significant improvements across multiple benchmarks, including a +4.2 percentage point gain on MVBench, +3.9 on PerceptionTest, and +6.8 on the challenging EgoSchema dataset compared to baseline models. Our model-agnostic approach is computationally efficient, requiring only 32 frames, offering a promising direction for self-aligned video understanding without reliance on external models or annotations.