A Lesson in Splats: Teacher-Guided Diffusion for 3D Gaussian Splats Generation with 2D Supervision
作者: Chensheng Peng, Ido Sobol, Masayoshi Tomizuka, Kurt Keutzer, Chenfeng Xu, Or Litany
分类: cs.CV
发布日期: 2024-12-01 (更新: 2025-07-26)
备注: ICCV 2025
💡 一句话要点
提出一种教师引导的扩散模型,仅用2D监督生成3D高斯溅射,提升生成质量。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D生成模型 扩散模型 2D监督 3D高斯溅射 稀疏视图重建
📋 核心要点
- 现有3D生成模型依赖完整3D监督,但大规模3D数据集稀缺,导致模型泛化能力受限。
- 利用确定性图像到3D模型作为教师,生成带噪声的3D输入,解耦3D去噪和2D监督。
- 实验表明,该方法在对象和场景级别数据集上均优于确定性教师模型,提升了3D生成的质量。
📝 摘要(中文)
本文提出了一种新颖的框架,仅使用2D监督训练3D图像条件扩散模型。从2D图像恢复3D结构本质上是不适定的,因为存在多种可能的重建方案,这使得生成模型成为一个自然的选择。然而,大多数现有的3D生成模型依赖于完整的3D监督,由于缺乏大规模的3D数据集,这在实践中是不可行的。为了解决这个问题,我们提出利用稀疏视图监督作为一种可扩展的替代方案。虽然最近的重建模型使用带有可微渲染的稀疏视图监督将2D图像提升到3D,但它们主要是确定性的,无法捕捉到各种合理的解决方案,并在不确定的区域产生模糊的预测。使用2D监督训练3D扩散模型的一个关键挑战是,标准的训练范式要求去噪过程和监督都在同一模态中。我们通过将去噪的噪声样本与监督信号解耦来解决这个问题,允许前者保持在3D中,而后者以2D形式提供。我们的方法利用来自确定性图像到3D模型的次优预测——充当“教师”——来生成噪声3D输入,从而实现有效的3D扩散训练,而无需完整的3D ground truth。我们在对象级别和场景级别的数据集上验证了我们的框架,使用了两个不同的3D高斯溅射(3DGS)教师。我们的结果表明,我们的方法始终优于这些确定性教师,证明了其在可扩展和高保真3D生成建模中的有效性。
🔬 方法详解
问题定义:论文旨在解决仅使用2D图像监督训练3D生成模型的问题。现有方法要么依赖于昂贵的3D标注数据,要么使用确定性模型进行3D重建,但确定性模型无法捕捉到3D重建的不确定性,导致生成结果模糊或不真实。
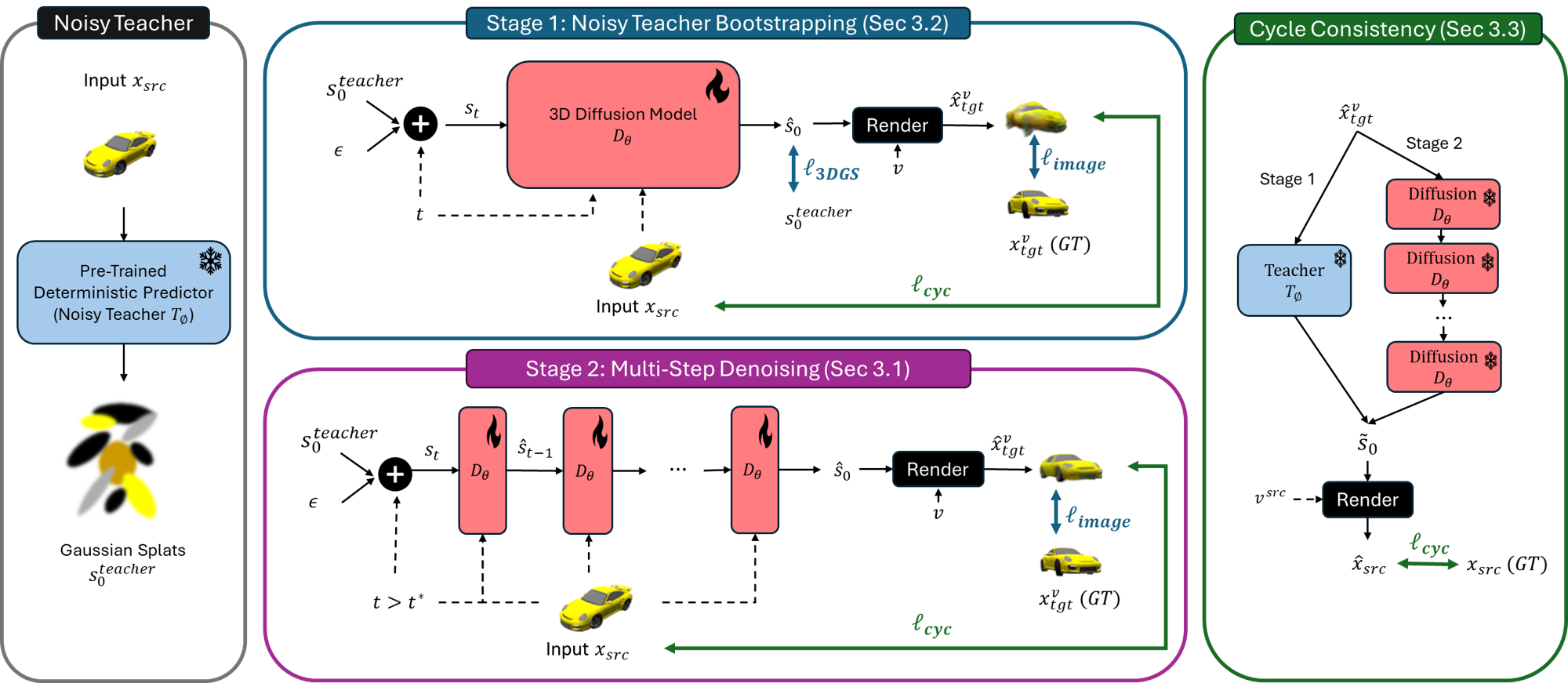
核心思路:论文的核心思路是利用一个预训练的确定性图像到3D模型(教师模型)生成初始的3D表示,然后使用扩散模型对该3D表示进行去噪和优化,同时使用2D图像作为监督信号。通过解耦3D去噪过程和2D监督信号,可以在没有3D ground truth的情况下训练3D扩散模型。
技术框架:整体框架包含两个主要部分:1) 教师模型:一个预训练的确定性图像到3D模型,用于从2D图像生成初始的3D高斯溅射表示。2) 扩散模型:一个3D扩散模型,用于对教师模型生成的3D表示进行去噪和优化。训练过程中,首先使用教师模型从2D图像生成3D高斯溅射,然后向该3D表示添加噪声,接着使用扩散模型进行去噪,并使用2D图像作为监督信号来优化扩散模型。
关键创新:最重要的技术创新点在于解耦了3D去噪过程和2D监督信号。传统的扩散模型需要输入和监督信号在同一模态下,而该方法允许在3D空间中进行去噪,同时使用2D图像进行监督,从而避免了对3D ground truth的依赖。
关键设计:论文使用了3D高斯溅射作为3D表示,因为它具有可微渲染的特性,可以方便地使用2D图像进行监督。损失函数包括一个2D图像重建损失,用于衡量去噪后的3D高斯溅射渲染出的图像与原始2D图像之间的差异。此外,论文还可能使用了正则化项来约束3D高斯溅射的形状和密度。
🖼️ 关键图片
📊 实验亮点
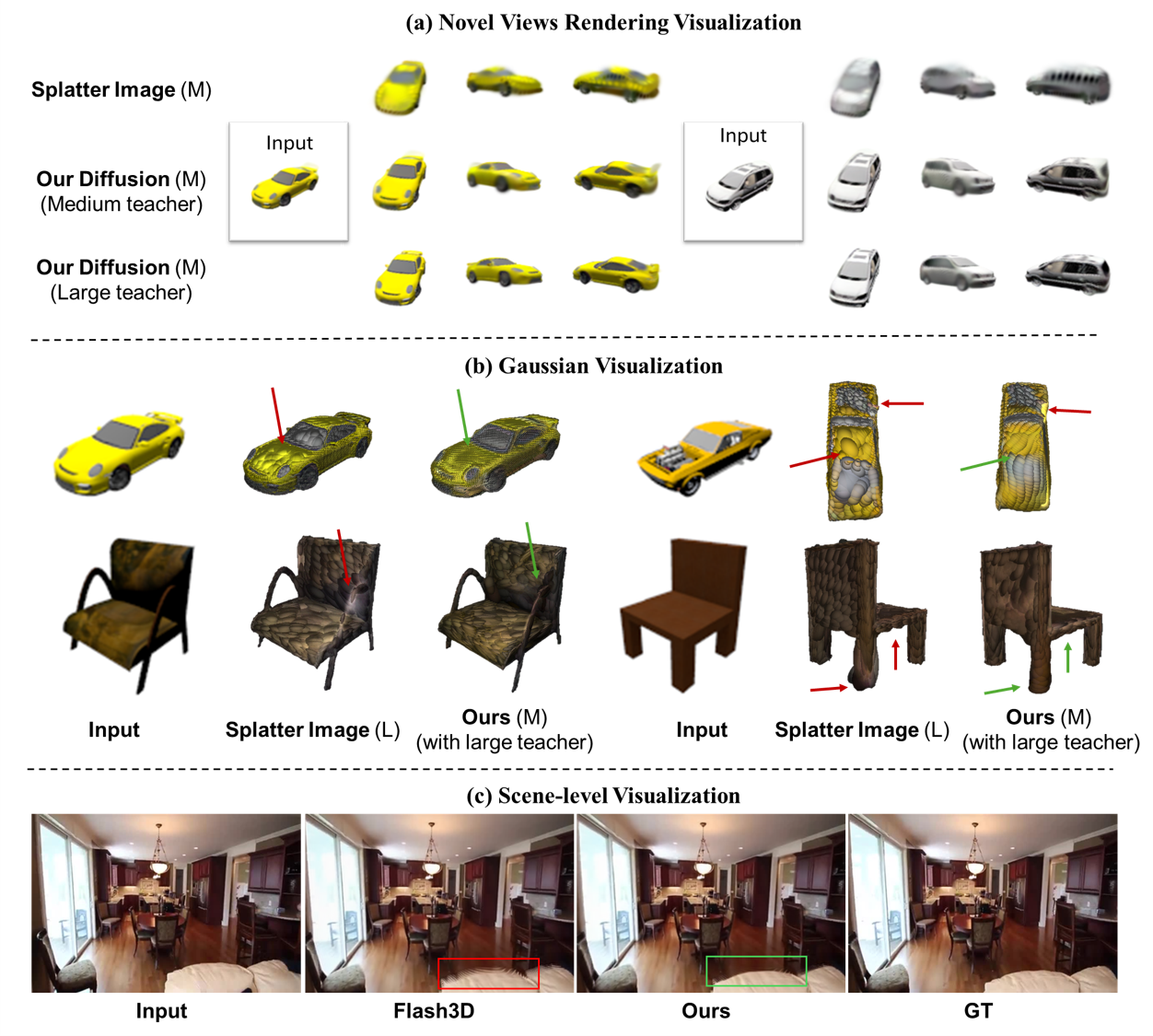
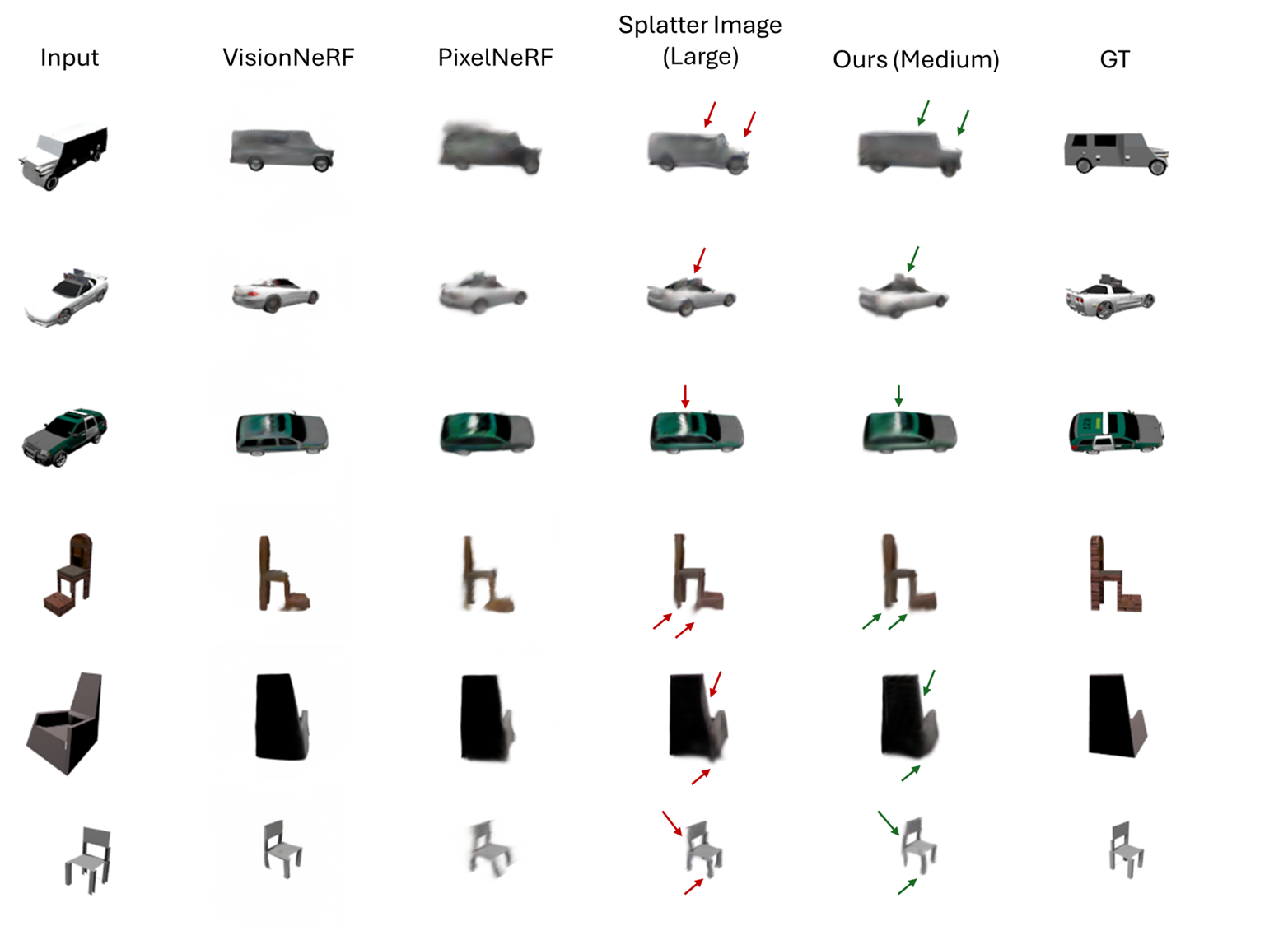
实验结果表明,该方法在对象级别和场景级别的数据集上均优于确定性教师模型。具体而言,该方法能够生成更清晰、更真实的3D模型,并且能够更好地捕捉到3D重建的不确定性。论文使用了定量指标和定性可视化来验证该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要从2D图像生成3D模型的场景,例如:自动驾驶中的场景重建、游戏开发中的3D资产生成、以及虚拟现实/增强现实中的3D内容创建。该方法降低了对3D标注数据的依赖,使得3D生成模型能够更广泛地应用。
📄 摘要(原文)
We present a novel framework for training 3D image-conditioned diffusion models using only 2D supervision. Recovering 3D structure from 2D images is inherently ill-posed due to the ambiguity of possible reconstructions, making generative models a natural choice. However, most existing 3D generative models rely on full 3D supervision, which is impractical due to the scarcity of large-scale 3D datasets. To address this, we propose leveraging sparse-view supervision as a scalable alternative. While recent reconstruction models use sparse-view supervision with differentiable rendering to lift 2D images to 3D, they are predominantly deterministic, failing to capture the diverse set of plausible solutions and producing blurry predictions in uncertain regions. A key challenge in training 3D diffusion models with 2D supervision is that the standard training paradigm requires both the denoising process and supervision to be in the same modality. We address this by decoupling the noisy samples being denoised from the supervision signal, allowing the former to remain in 3D while the latter is provided in 2D. Our approach leverages suboptimal predictions from a deterministic image-to-3D model-acting as a "teacher"-to generate noisy 3D inputs, enabling effective 3D diffusion training without requiring full 3D ground truth. We validate our framework on both object-level and scene-level datasets, using two different 3D Gaussian Splat (3DGS) teachers. Our results show that our approach consistently improves upon these deterministic teachers, demonstrating its effectiveness in scalable and high-fidelity 3D generative modeling. See our project page at https://lesson-in-splats.github.io/