Accelerating Multimodal Large Language Models by Searching Optimal Vision Token Reduction
作者: Shiyu Zhao, Zhenting Wang, Felix Juefei-Xu, Xide Xia, Miao Liu, Xiaofang Wang, Mingfu Liang, Ning Zhang, Dimitris N. Metaxas, Licheng Yu
分类: cs.CV
发布日期: 2024-11-30 (更新: 2024-12-08)
备注: Technical report, 18 pages
💡 一句话要点
提出G-Search与P-Sigmoid以加速多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉标记 贪婪搜索 参数化sigmoid 计算效率 贝叶斯优化 图像处理 自然语言处理
📋 核心要点
- 现有的多模态大语言模型在处理高分辨率图像时,视觉标记数量急剧增加,导致计算成本过高。
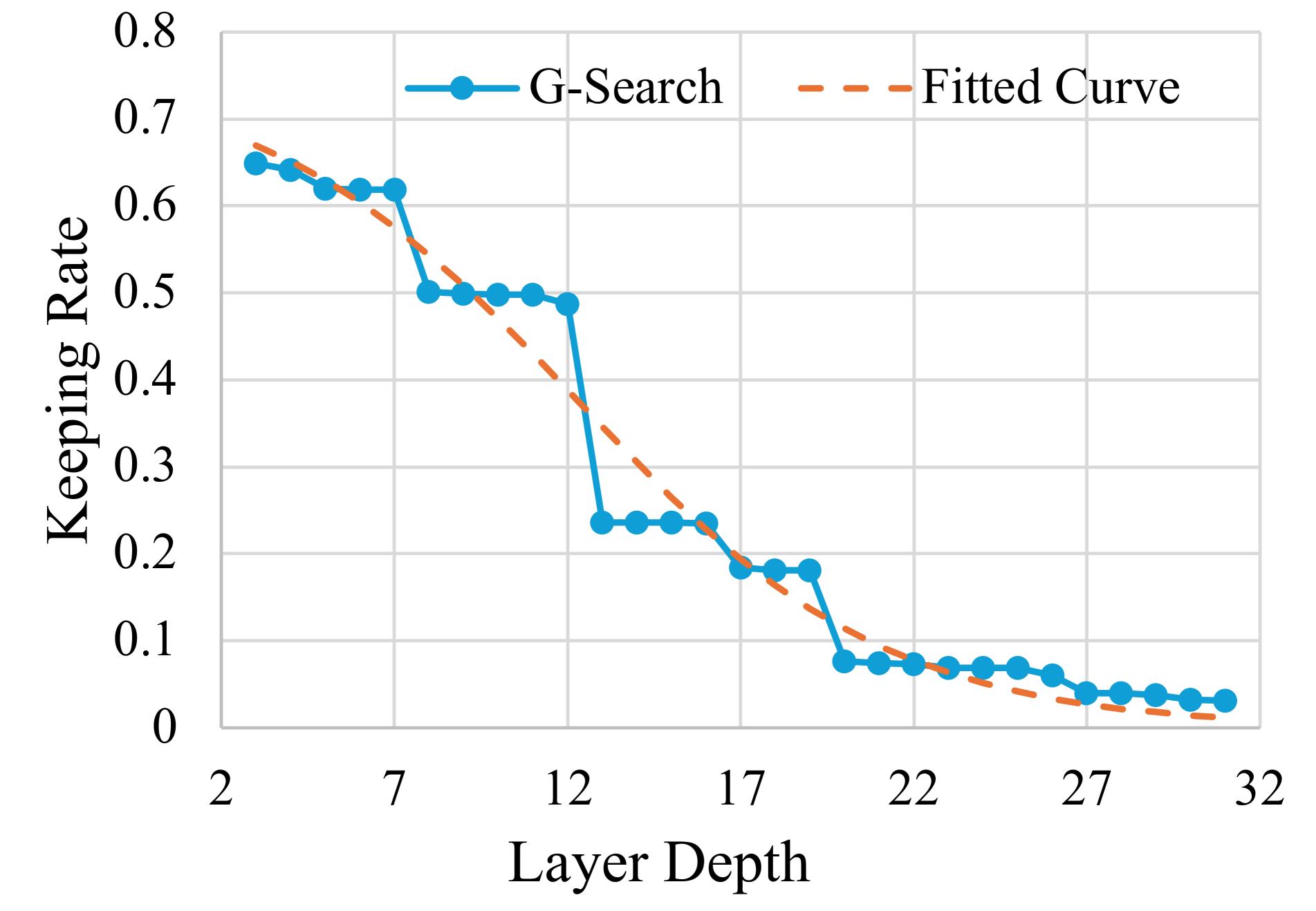
- 本文提出贪婪搜索算法(G-Search)和参数化sigmoid函数(P-Sigmoid),以优化视觉标记的选择和减少。
- 实验结果显示,所提方法在不降低性能的情况下,能将流行的MLLM加速超过2倍,且在预算有限时表现优于其他方法。
📝 摘要(中文)
当前的多模态大语言模型(MLLMs)在处理图像输入时,使用视觉标记(vision tokens),但随着图像分辨率的增加,视觉标记数量呈平方增长,导致计算成本高昂。本文从两个方面提升MLLM的效率:一是减少计算成本而不降低性能,二是在给定预算下提升性能。研究发现,除了第一层外,各层的视觉标记按注意力分数排序的排名相似,因此提出了一种贪婪搜索算法(G-Search)来确定每层保留的最少视觉标记数量。此外,基于G-Search的结果,设计了一个参数化的sigmoid函数(P-Sigmoid)来指导每层的标记减少。实验表明,该方法能显著加速流行的MLLM,如LLaVA和InternVL2模型,提升超过2倍且无性能下降。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型在处理高分辨率图像时,视觉标记数量急剧增加导致的计算成本高昂问题。现有方法在标记选择上缺乏有效的优化策略,导致性能和效率的矛盾。
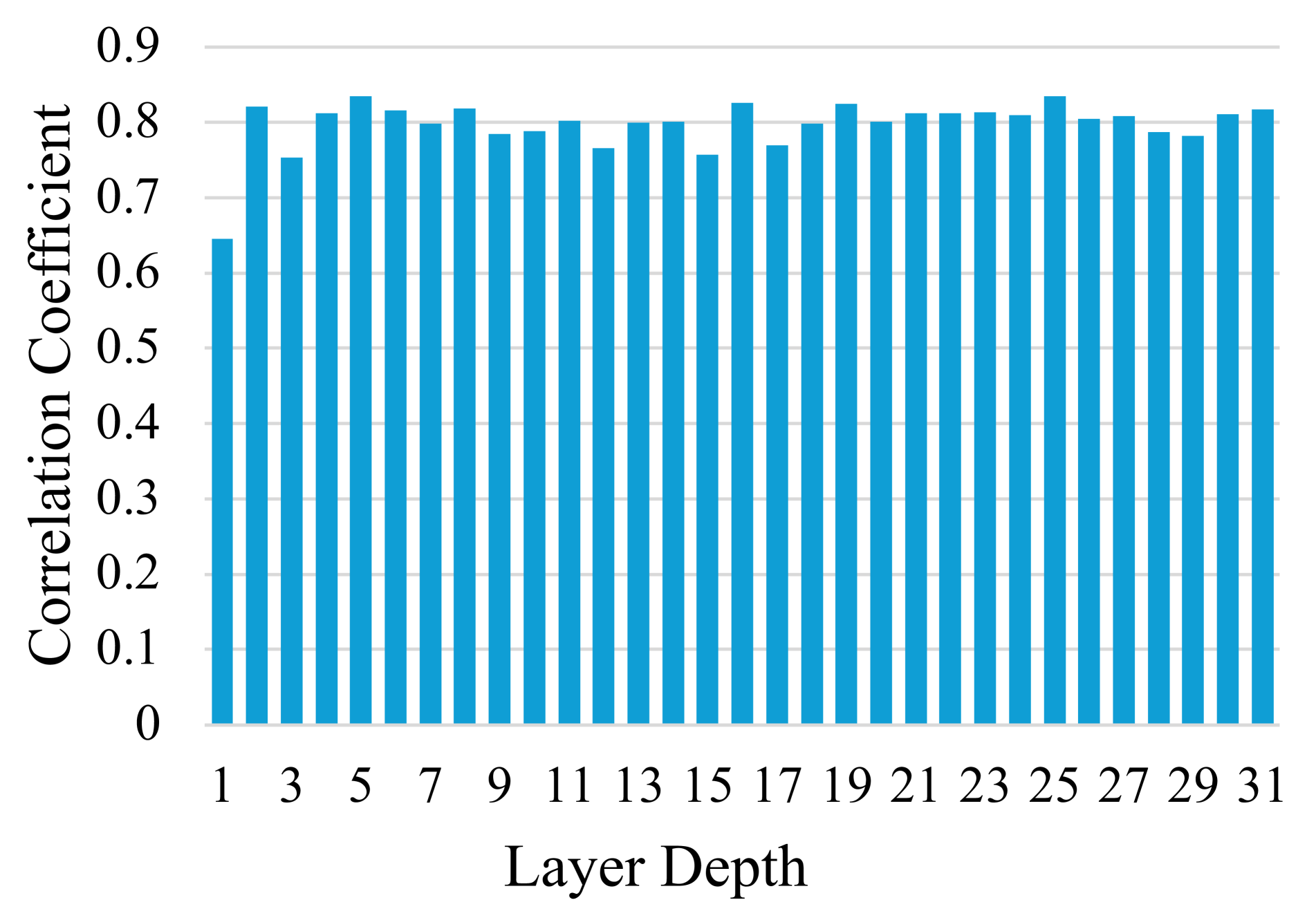
核心思路:论文提出的核心思路是通过贪婪搜索算法(G-Search)确定每层保留的最少视觉标记数量,并利用参数化sigmoid函数(P-Sigmoid)优化标记的减少过程。该方法假设各层的视觉标记重要性排名相似,从而可以有效减少标记数量而不影响性能。
技术框架:整体架构包括两个主要模块:G-Search用于确定每层的视觉标记数量,P-Sigmoid则在此基础上优化标记的选择。G-Search从浅层到深层逐层分析,P-Sigmoid通过贝叶斯优化调整参数,以实现最佳的标记减少策略。
关键创新:最重要的技术创新在于提出了G-Search和P-Sigmoid的结合使用,前者通过贪婪算法实现标记的最优选择,后者通过参数化函数进一步优化选择过程。这一方法显著提高了多模态模型的计算效率。
关键设计:在G-Search中,设定了视觉标记的注意力分数作为排序依据,确保保留最重要的标记;在P-Sigmoid中,设计了参数优化过程,通过贝叶斯优化调整sigmoid函数的参数,以适应不同层次的需求。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提方法在加速流行的多模态大语言模型(如LLaVA和InternVL2)方面表现优异,速度提升超过2倍,同时保持性能不变。此外,在预算有限的情况下,该方法显著优于其他标记减少方法,展现出更好的效率与效果平衡。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉、自然语言处理和机器人等多模态任务。通过提高多模态大语言模型的效率,能够在实时图像理解、智能助手和自动驾驶等场景中实现更快的响应和更高的性能,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Prevailing Multimodal Large Language Models (MLLMs) encode the input image(s) as vision tokens and feed them into the language backbone, similar to how Large Language Models (LLMs) process the text tokens. However, the number of vision tokens increases quadratically as the image resolutions, leading to huge computational costs. In this paper, we consider improving MLLM's efficiency from two scenarios, (I) Reducing computational cost without degrading the performance. (II) Improving the performance with given budgets. We start with our main finding that the ranking of each vision token sorted by attention scores is similar in each layer except the first layer. Based on it, we assume that the number of essential top vision tokens does not increase along layers. Accordingly, for Scenario I, we propose a greedy search algorithm (G-Search) to find the least number of vision tokens to keep at each layer from the shallow to the deep. Interestingly, G-Search is able to reach the optimal reduction strategy based on our assumption. For Scenario II, based on the reduction strategy from G-Search, we design a parametric sigmoid function (P-Sigmoid) to guide the reduction at each layer of the MLLM, whose parameters are optimized by Bayesian Optimization. Extensive experiments demonstrate that our approach can significantly accelerate those popular MLLMs, e.g. LLaVA, and InternVL2 models, by more than $2 \times$ without performance drops. Our approach also far outperforms other token reduction methods when budgets are limited, achieving a better trade-off between efficiency and effectiveness.