Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding
作者: Duo Zheng, Shijia Huang, Liwei Wang
分类: cs.CV, cs.CL
发布日期: 2024-11-30 (更新: 2025-03-27)
备注: Accepted by CVPR 2025
💡 一句话要点
提出Video-3D LLM,通过视频表示和位置编码增强LLM在3D场景理解中的能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 多模态大语言模型 视频表示学习 位置编码 机器人视觉
📋 核心要点
- 现有MLLM在3D场景理解中表现不足,主要原因是其训练数据以2D为主,缺乏对3D空间信息的有效建模。
- Video-3D LLM将3D场景视为动态视频,并引入3D位置编码,从而使模型能够更好地理解和对齐视频表示与真实世界的空间环境。
- 实验结果表明,该模型在ScanRefer等多个3D场景理解基准测试中取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)的快速发展对各种多模态任务产生了重大影响。然而,这些模型在需要3D环境中空间理解的任务中面临挑战。虽然已经尝试通过结合点云特征来增强MLLM,但模型学习到的表示与3D场景的固有复杂性之间仍然存在相当大的差距。这种差异主要源于MLLM主要在2D数据上进行训练,这限制了它们理解3D空间的能力。为了解决这个问题,本文提出了一种新的通用模型,即Video-3D LLM,用于3D场景理解。通过将3D场景视为动态视频,并将3D位置编码融入到这些表示中,我们的Video-3D LLM能够更准确地将视频表示与真实世界的空间环境对齐。此外,我们还实施了一种最大覆盖采样技术,以优化计算成本和性能之间的权衡。大量的实验表明,我们的模型在多个3D场景理解基准测试中实现了最先进的性能,包括ScanRefer、Multi3DRefer、Scan2Cap、ScanQA和SQA3D。
🔬 方法详解
问题定义:现有MLLM在3D场景理解任务中表现不佳,主要原因是它们在很大程度上依赖于2D数据进行训练,缺乏对3D空间信息的有效建模和理解。直接将点云等3D特征输入MLLM虽然有所改进,但仍然无法充分捕捉3D场景的复杂性和空间关系。因此,如何有效地将3D信息融入到MLLM中,使其能够更好地理解和推理3D场景,是一个亟待解决的问题。
核心思路:Video-3D LLM的核心思路是将3D场景视为动态视频,并利用视频表示学习的优势来捕捉3D场景中的空间和时间信息。通过将3D位置编码融入到视频表示中,模型能够更好地理解视频帧之间的空间关系,从而更准确地将视频表示与真实世界的3D空间环境对齐。这种方法避免了直接处理复杂的点云数据,而是利用了现有的视频处理技术和MLLM的强大能力。
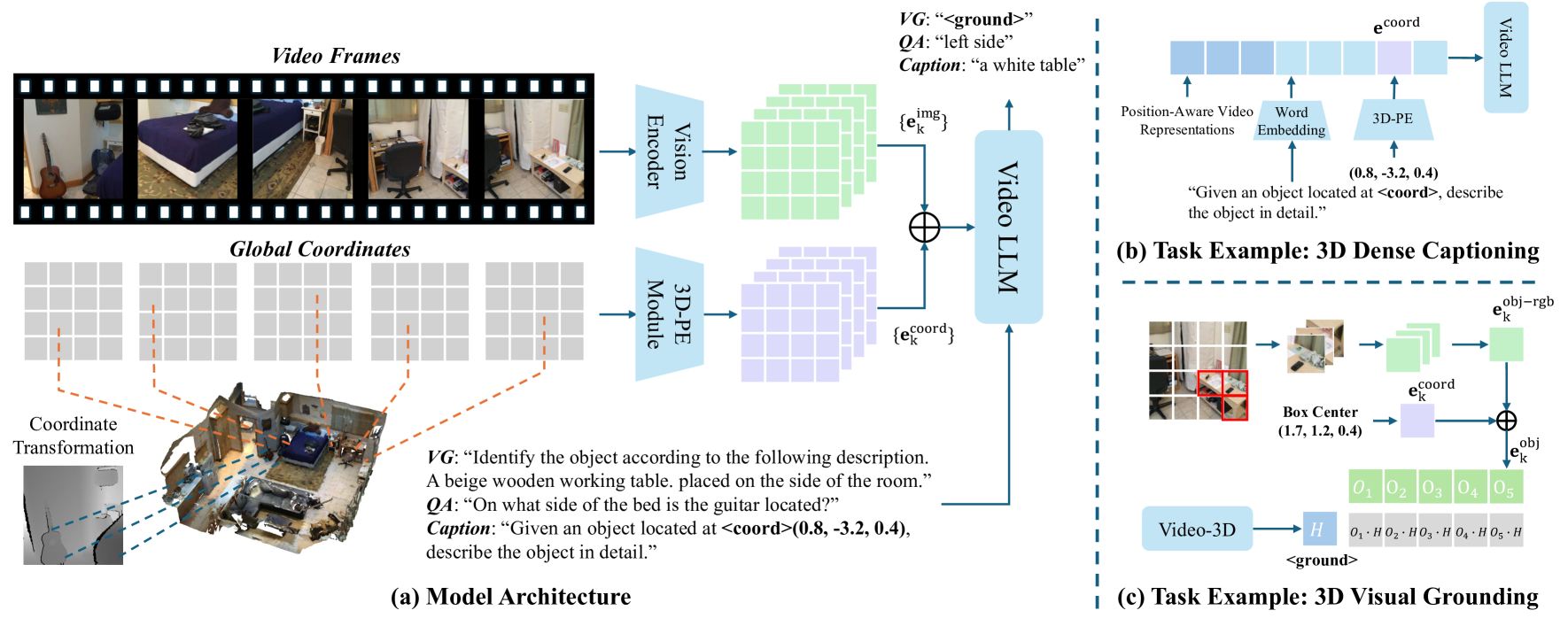
技术框架:Video-3D LLM的整体框架包括以下几个主要模块:1) 视频编码器:用于将3D场景的动态视频帧编码成视频特征表示。2) 3D位置编码器:用于将3D空间位置信息编码成位置特征向量。3) 特征融合模块:用于将视频特征和位置特征进行融合,得到包含空间信息的视频表示。4) MLLM:用于对融合后的特征进行理解和推理,完成各种3D场景理解任务。整个流程是将3D场景转化为视频,提取视频特征,加入位置信息,最后输入MLLM进行处理。
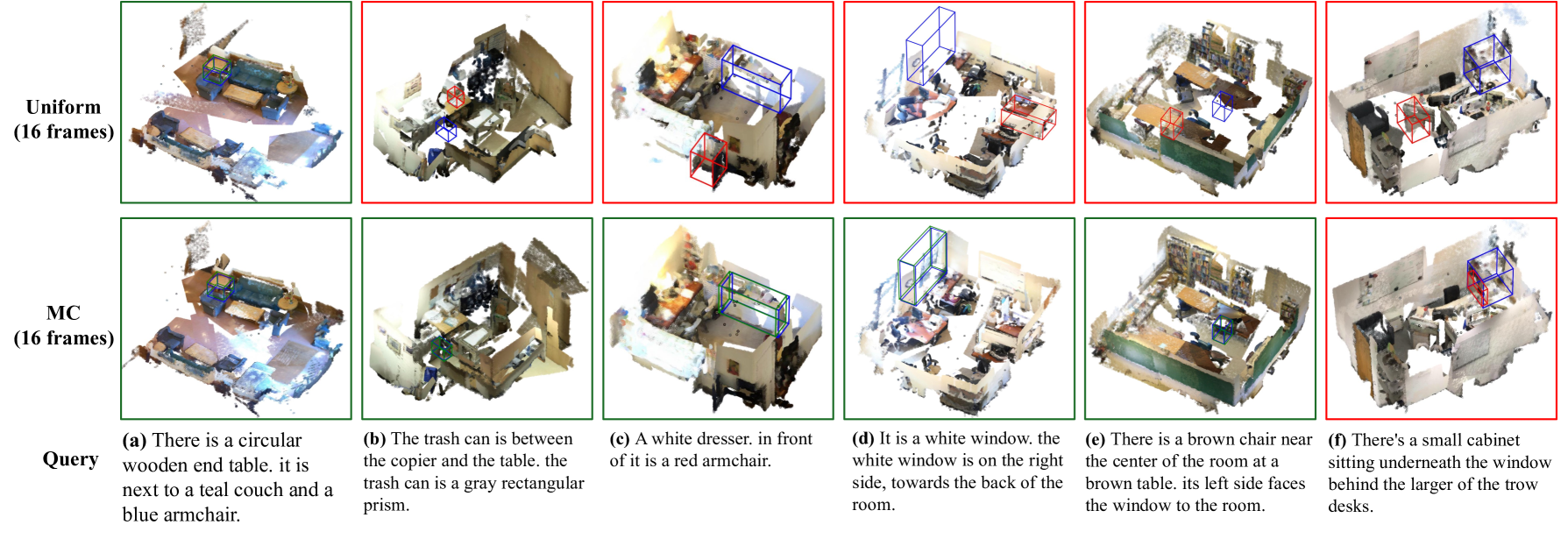
关键创新:Video-3D LLM的关键创新在于将3D场景理解问题转化为视频理解问题,并巧妙地利用3D位置编码将空间信息融入到视频表示中。这种方法避免了直接处理复杂的3D数据,而是利用了现有的视频处理技术和MLLM的强大能力。此外,论文还提出了一种最大覆盖采样技术,用于优化计算成本和性能之间的权衡。
关键设计:在视频编码器方面,可以使用各种现有的视频编码器,例如TimeSformer等。3D位置编码器可以使用例如正余弦位置编码等方法。特征融合模块可以使用例如concat或者attention机制。最大覆盖采样技术旨在选择最具代表性的视频帧,以减少计算量,同时保持模型的性能。具体的参数设置和网络结构需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
Video-3D LLM在ScanRefer、Multi3DRefer、Scan2Cap、ScanQA和SQA3D等多个3D场景理解基准测试中取得了SOTA性能。例如,在ScanRefer数据集上,该模型相对于之前的最佳模型取得了显著的性能提升。这些实验结果表明,Video-3D LLM能够有效地理解和推理3D场景,具有很强的竞争力。
🎯 应用场景
Video-3D LLM在机器人导航、自动驾驶、虚拟现实、增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,它可以提高车辆对3D场景的感知能力,从而提高驾驶安全性。在VR/AR领域,它可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
The rapid advancement of Multimodal Large Language Models (MLLMs) has significantly impacted various multimodal tasks. However, these models face challenges in tasks that require spatial understanding within 3D environments. Efforts to enhance MLLMs, such as incorporating point cloud features, have been made, yet a considerable gap remains between the models' learned representations and the inherent complexity of 3D scenes. This discrepancy largely stems from the training of MLLMs on predominantly 2D data, which restricts their effectiveness in comprehending 3D spaces. To address this issue, in this paper, we propose a novel generalist model, i.e., Video-3D LLM, for 3D scene understanding. By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately. In addition, we have implemented a maximum coverage sampling technique to optimize the trade-off between computational cost and performance. Extensive experiments demonstrate that our model achieves state-of-the-art performance on several 3D scene understanding benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D.