ATP-LLaVA: Adaptive Token Pruning for Large Vision Language Models
作者: Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-Ping Zhang, Yansong Tang
分类: cs.CV
发布日期: 2024-11-30
备注: 11 pages, 4 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出ATP-LLaVA以解决大规模视觉语言模型的计算成本问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 自适应修剪 多模态任务 计算效率 空间建模
📋 核心要点
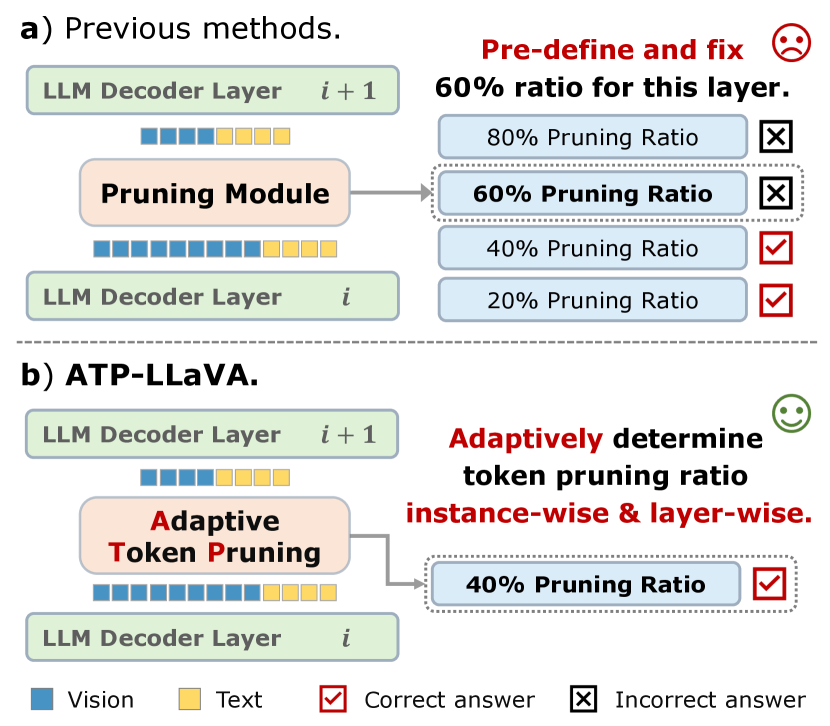
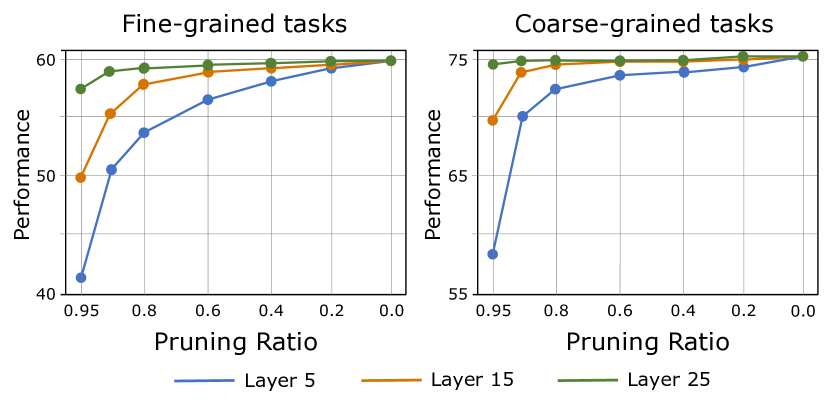
- 现有方法通过固定比例修剪视觉标记,未能有效应对不同层和实例的修剪需求,导致计算资源浪费。
- 本文提出ATP-LLaVA,采用自适应标记修剪模块,根据输入实例动态计算修剪比例,优化计算效率。
- 实验结果表明,ATP-LLaVA在保持性能的同时,平均标记数量减少了75%,在七个基准测试中仅有1.9%的性能下降。
📝 摘要(中文)
大规模视觉语言模型(LVLMs)在多模态任务中取得了显著成功。然而,处理长视觉标记的计算成本在资源有限的设备上可能过于昂贵。以往的方法通过预定义或固定比例的方式修剪标记,降低了计算开销,但未能考虑不同层和实例的修剪比例差异。为此,本文提出了一种层级和实例特定的视觉标记修剪策略ATP-LLaVA,能够自适应地为每个LLM层确定实例特定的修剪比例。通过引入自适应标记修剪模块(ATP),该方法在保持性能的同时将平均标记数量减少了75%,在七个广泛使用的基准测试中仅有1.9%的性能下降。
🔬 方法详解
问题定义:本文旨在解决大规模视觉语言模型在处理长视觉标记时的高计算成本问题。现有方法通过固定比例修剪标记,未能考虑不同层和实例的特性,导致计算资源的浪费。
核心思路:论文提出了一种自适应的标记修剪策略,能够根据输入实例动态调整每个LLM层的修剪比例,从而在保证模型性能的同时有效降低计算开销。
技术框架:整体架构包括自适应标记修剪模块(ATP)和空间增强修剪策略(SAP)。ATP模块在任意两个LLM层之间无缝集成,计算输入实例的标记重要性分数和修剪阈值。SAP策略则从标记冗余和空间建模的角度进行视觉标记的修剪。
关键创新:最重要的创新在于引入了自适应标记修剪模块,能够根据具体实例动态调整修剪比例,与传统的固定比例修剪方法本质上不同,显著提升了模型的灵活性和效率。
关键设计:在设计中,ATP模块的计算开销极小,能够在不显著增加计算负担的情况下实现高效的标记修剪。此外,SAP策略结合了标记冗余和空间信息,进一步优化了修剪效果。
🖼️ 关键图片

📊 实验亮点
实验结果显示,ATP-LLaVA在七个广泛使用的基准测试中,平均标记数量减少了75%,仅有1.9%的性能下降,显著优于传统的固定比例修剪方法,展示了其在多模态任务中的有效性和高效性。
🎯 应用场景
该研究的潜在应用领域包括图像识别、视频分析和自然语言处理等多模态任务。通过降低计算成本,ATP-LLaVA能够在资源有限的设备上实现高效的视觉语言模型应用,具有重要的实际价值和广泛的未来影响。
📄 摘要(原文)
Large Vision Language Models (LVLMs) have achieved significant success across multi-modal tasks. However, the computational cost of processing long visual tokens can be prohibitively expensive on resource-limited devices. Previous methods have identified redundancy in visual tokens within the Large Language Model (LLM) decoder layers and have mitigated this by pruning tokens using a pre-defined or fixed ratio, thereby reducing computational overhead. Nonetheless, we observe that the impact of pruning ratio varies across different LLM layers and instances (image-prompt pairs). Therefore, it is essential to develop a layer-wise and instance-wise vision token pruning strategy to balance computational cost and model performance effectively. We propose ATP-LLaVA, a novel approach that adaptively determines instance-specific token pruning ratios for each LLM layer. Specifically, we introduce an Adaptive Token Pruning (ATP) module, which computes the importance score and pruning threshold based on input instance adaptively. The ATP module can be seamlessly integrated between any two LLM layers with negligible computational overhead. Additionally, we develop a Spatial Augmented Pruning (SAP) strategy that prunes visual tokens with both token redundancy and spatial modeling perspectives. Our approach reduces the average token count by 75% while maintaining performance, with only a minimal 1.9% degradation across seven widely used benchmarks. The project page can be accessed via https://yxxxb.github.io/ATP-LLaVA-page/.