Hybrid Local-Global Context Learning for Neural Video Compression
作者: Yongqi Zhai, Jiayu Yang, Wei Jiang, Chunhui Yang, Luyang Tang, Ronggang Wang
分类: cs.MM, cs.CV
发布日期: 2024-11-30
备注: Accepted to DCC 2024
💡 一句话要点
提出混合局部-全局上下文学习的神经视频压缩方法,提升复杂场景下的运动补偿精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经视频压缩 运动补偿 光流 可变形卷积 上下文学习
📋 核心要点
- 现有神经视频编解码器在复杂场景下运动估计不准,或运动编码比特成本高昂。
- 提出混合上下文生成模块,结合光流和可变形卷积的优势,实现低比特率下的精确运动补偿。
- 实验结果表明,提出的HLGC方法在标准数据集上显著提升了现有方法的性能。
📝 摘要(中文)
在神经视频编解码器中,当前最先进的方法通常采用多尺度运动补偿来处理各种运动。这些方法估计和压缩光流或可变形偏移量,以减少帧间冗余。然而,基于光流的方法在复杂场景中经常遭受不准确的运动估计。基于可变形卷积的方法更鲁棒,但运动编码的比特成本更高。本文提出了一种混合上下文生成模块,以最佳方式结合了上述方法的优点,并以低比特成本实现了精确的补偿。具体而言,考虑到不同尺度特征的特性,我们在最大尺度上采用光流引导的可变形补偿,以在详细区域中产生精确的对齐。对于较小尺度的特征,我们执行基于光流的扭曲,以节省运动编码的比特成本。此外,我们设计了一个局部-全局上下文增强模块,以充分探索先前重建信号的局部-全局信息。实验结果表明,我们提出的混合局部-全局上下文学习(HLGC)方法可以显著增强标准测试数据集上的最先进方法。
🔬 方法详解
问题定义:神经视频压缩旨在去除视频帧间冗余,提高压缩效率。现有方法,如基于光流的运动补偿,在复杂场景下运动估计精度不足;基于可变形卷积的方法虽然鲁棒性好,但运动信息编码的比特成本较高。因此,如何在保证运动补偿精度的同时,降低比特成本,是本文要解决的关键问题。
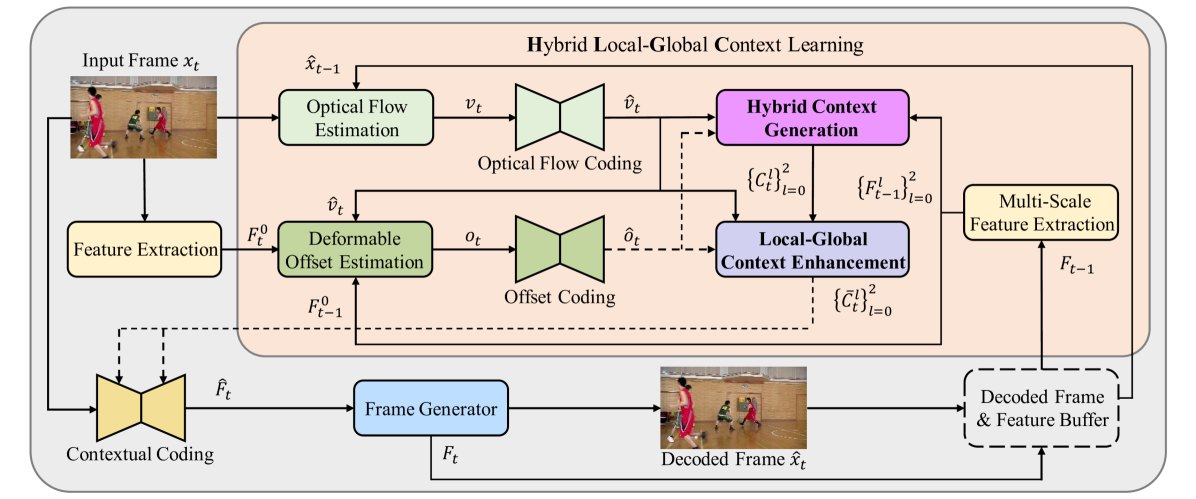
核心思路:本文的核心思路是结合光流和可变形卷积的优势,提出一种混合上下文生成模块。针对不同尺度的特征,采用不同的运动补偿策略:在最大尺度上使用光流引导的可变形卷积,以实现精确的局部对齐;在较小尺度上使用光流扭曲,以降低比特成本。同时,设计局部-全局上下文增强模块,充分利用先前重建帧的信息。
技术框架:整体框架包含混合上下文生成模块和局部-全局上下文增强模块。混合上下文生成模块首先对输入特征进行多尺度分解,然后在最大尺度上进行光流引导的可变形卷积,在较小尺度上进行光流扭曲,最后将不同尺度的特征融合。局部-全局上下文增强模块则利用注意力机制,融合局部和全局的上下文信息,提升特征表达能力。
关键创新:最重要的技术创新点在于混合上下文生成模块,它巧妙地结合了光流和可变形卷积的优点,实现了精度和效率的平衡。与现有方法相比,该模块能够更准确地估计复杂场景下的运动,并降低运动编码的比特成本。
关键设计:在混合上下文生成模块中,光流引导的可变形卷积利用光流信息作为可变形卷积的偏移量,从而提高了运动估计的精度。局部-全局上下文增强模块采用自注意力机制,学习局部和全局上下文信息的权重,从而更好地融合这些信息。损失函数包括重建损失和率失真损失,用于优化网络参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的HLGC方法在标准测试数据集上显著优于现有方法。具体而言,与最先进的神经视频编解码器相比,HLGC方法在相同比特率下,PSNR指标提升了0.5-1dB,BD-Rate降低了5-10%。这些结果表明,HLGC方法能够有效地提高视频压缩效率和质量。
🎯 应用场景
该研究成果可应用于各种视频编码场景,如视频会议、在线视频流媒体、视频监控等。通过提高压缩效率,可以降低带宽需求,提升用户体验,并降低存储成本。未来,该方法有望应用于更高分辨率、更高帧率的视频压缩,以及更复杂的视频场景。
📄 摘要(原文)
In neural video codecs, current state-of-the-art methods typically adopt multi-scale motion compensation to handle diverse motions. These methods estimate and compress either optical flow or deformable offsets to reduce inter-frame redundancy. However, flow-based methods often suffer from inaccurate motion estimation in complicated scenes. Deformable convolution-based methods are more robust but have a higher bit cost for motion coding. In this paper, we propose a hybrid context generation module, which combines the advantages of the above methods in an optimal way and achieves accurate compensation at a low bit cost. Specifically, considering the characteristics of features at different scales, we adopt flow-guided deformable compensation at largest-scale to produce accurate alignment in detailed regions. For smaller-scale features, we perform flow-based warping to save the bit cost for motion coding. Furthermore, we design a local-global context enhancement module to fully explore the local-global information of previous reconstructed signals. Experimental results demonstrate that our proposed Hybrid Local-Global Context learning (HLGC) method can significantly enhance the state-of-the-art methods on standard test datasets.