Towards Pixel-Level Prediction for Gaze Following: Benchmark and Approach
作者: Feiyang Liu, Dan Guo, Jingyuan Xu, Zihao He, Shengeng Tang, Kun Li, Meng Wang
分类: cs.CV
发布日期: 2024-11-30 (更新: 2025-02-04)
备注: After discussions among the authors, we believe that some experiments in the paper still require further improvement, and we have decided to withdraw it for the time being
💡 一句话要点
提出GazeSeg模型,用于像素级注视目标预测,并构建大规模数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注视跟踪 目标分割 视觉基础模型 像素级预测 人机交互
📋 核心要点
- 现有注视跟踪方法难以在复杂场景中有效工作,且更关注注视点而非目标对象,缺乏清晰的语义信息。
- GazeSeg利用视觉基础模型和多解码模块,从粗到精预测注视目标,实现分割、识别和方向估计的统一框架。
- 构建了包含72k图像的像素级标注数据集,实验表明GazeSeg在分割、识别和跟踪任务上均优于现有方法。
📝 摘要(中文)
本文提出了一种新的注视目标预测解决方案GazeSeg,旨在解决现有方法在复杂场景中表现不佳,且侧重于注视点而非目标对象的问题。GazeSeg充分利用了人的空间视觉场作为引导信息,实现了由粗到精的注视目标分割和识别过程。该模型采用基于提示的视觉基础模型作为编码器,并结合三个不同的解码模块(FoV感知、热图生成和分割)构成注视目标预测框架。通过头部边界框作为初始提示,GazeSeg逐步获得FoV图、热图和分割图,形成了一个用于多任务(方向估计、注视目标分割和识别)的统一框架。此外,本文构建并发布了一个新的数据集,包含72k张图像,具有像素级标注和270个类别的注视目标,该数据集建立在GazeFollow数据集之上。实验结果表明,GazeSeg在注视目标分割任务中取得了0.325的Dice系数,在Top-5识别中达到了71.7%的准确率,并在注视跟踪任务中取得了0.953的AUC,优于现有方法。
🔬 方法详解
问题定义:现有注视跟踪方法主要关注预测注视点,而忽略了注视目标的语义信息和精确范围。在复杂场景下,由于目标的多样性和遮挡等因素,现有方法的性能显著下降。因此,需要一种能够进行像素级注视目标预测的方法,从而提供更清晰的目标语义和更准确的范围。
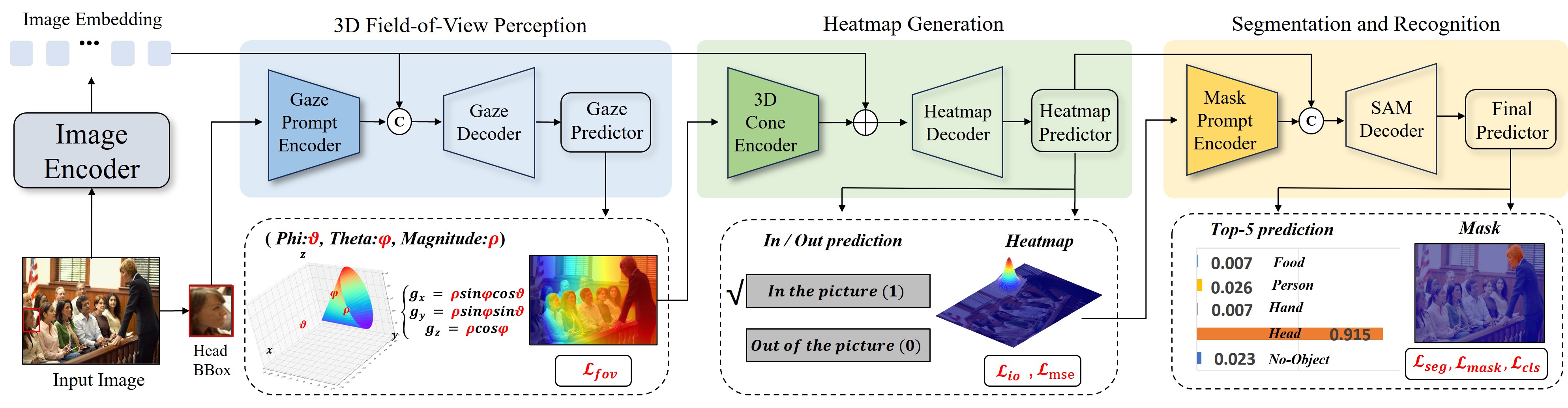
核心思路:GazeSeg的核心思路是利用人的空间视觉场(Field of View, FoV)作为引导信息,通过一个由粗到精的过程来预测注视目标。首先,利用头部边界框作为提示,引导模型关注可能的注视区域。然后,通过FoV感知模块、热图生成模块和分割模块,逐步细化预测结果,最终得到像素级的注视目标分割图。这种由粗到精的设计能够有效地利用上下文信息,提高预测的准确性。
技术框架:GazeSeg的整体框架包括一个基于提示的视觉基础模型编码器和三个解码模块:FoV感知模块、热图生成模块和分割模块。首先,使用头部边界框作为提示,输入到视觉基础模型编码器中,提取图像特征。然后,FoV感知模块预测注视者的视野范围,热图生成模块预测注视热图,分割模块预测注视目标的像素级分割图。这三个模块并行工作,并相互补充,最终得到统一的注视目标预测结果。
关键创新:GazeSeg的关键创新在于将注视目标预测问题转化为一个像素级分割问题,并利用视觉基础模型和多解码模块实现由粗到精的预测。与现有方法相比,GazeSeg能够提供更清晰的目标语义和更准确的范围,并且能够同时进行方向估计、注视目标分割和识别等多项任务。此外,提出的基于提示的视觉基础模型编码器能够有效地利用头部边界框信息,提高预测的准确性。
关键设计:GazeSeg的关键设计包括:1) 使用视觉基础模型作为编码器,能够提取更丰富的图像特征;2) 设计了三个不同的解码模块,分别负责FoV感知、热图生成和分割,能够从不同角度对注视目标进行预测;3) 使用头部边界框作为提示,引导模型关注可能的注视区域;4) 采用了Dice损失函数来优化分割模块,提高分割的准确性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
GazeSeg在自建数据集上取得了显著的性能提升。在注视目标分割任务中,Dice系数达到了0.325,在Top-5识别中达到了71.7%的准确率。此外,在GazeFollow数据集上的注视跟踪任务中,GazeSeg取得了0.953的AUC,优于现有的state-of-the-art方法。这些结果表明,GazeSeg能够有效地进行像素级注视目标预测,并具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于人机交互、机器人导航、辅助驾驶等领域。通过准确预测人的注视目标,可以使机器更好地理解人的意图,从而实现更自然、更智能的交互。例如,在人机交互中,机器可以根据人的注视目标提供相关信息或服务;在机器人导航中,机器人可以根据人的注视方向规划路径;在辅助驾驶中,系统可以根据驾驶员的注视目标判断其注意力是否集中。
📄 摘要(原文)
Following the gaze of other people and analyzing the target they are looking at can help us understand what they are thinking, and doing, and predict the actions that may follow. Existing methods for gaze following struggle to perform well in natural scenes with diverse objects, and focus on gaze points rather than objects, making it difficult to deliver clear semantics and accurate scope of the targets. To address this shortcoming, we propose a novel gaze target prediction solution named GazeSeg, that can fully utilize the spatial visual field of the person as guiding information and lead to a progressively coarse-to-fine gaze target segmentation and recognition process. Specifically, a prompt-based visual foundation model serves as the encoder, working in conjunction with three distinct decoding modules (e.g. FoV perception, heatmap generation, and segmentation) to form the framework for gaze target prediction. Then, with the head bounding box performed as an initial prompt, GazeSeg obtains the FoV map, heatmap, and segmentation map progressively, leading to a unified framework for multiple tasks (e.g. direction estimation, gaze target segmentation, and recognition). In particular, to facilitate this research, we construct and release a new dataset, comprising 72k images with pixel-level annotations and 270 categories of gaze targets, built upon the GazeFollow dataset. The quantitative evaluation shows that our approach achieves the Dice of 0.325 in gaze target segmentation and 71.7% top-5 recognition. Meanwhile, our approach also outperforms previous state-of-the-art methods, achieving 0.953 in AUC on the gaze-following task. The dataset and code will be released.