FreeCloth: Free-form Generation Enhances Challenging Clothed Human Modeling
作者: Hang Ye, Xiaoxuan Ma, Hai Ci, Wentao Zhu, Yizhou Wang
分类: cs.CV, cs.GR, cs.LG
发布日期: 2024-11-29 (更新: 2025-04-09)
备注: 23 pages, 26 figures
💡 一句话要点
FreeCloth:提出自由形态生成方法,增强复杂服装人体建模效果
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 服装建模 人体建模 自由形态生成 线性混合蒙皮 深度学习
📋 核心要点
- 现有方法在处理宽松服装人体建模时,由于服装远离身体导致规范化过程不明确,容易产生不连续和碎片化的结果。
- FreeCloth提出了一种混合框架,根据区域与身体的距离,分别采用LBS和自由形态生成器进行建模,增强了灵活性和表现力。
- 实验结果表明,FreeCloth在宽松服装人体建模方面达到了最先进的性能,具有卓越的视觉保真度和真实感。
📝 摘要(中文)
为了实现逼真的动画人体化身,需要精确地对依赖于姿势的服装变形进行建模。现有的基于学习的方法严重依赖于SMPL等最小服装人体模型的线性混合蒙皮(LBS)来建模变形。然而,它们难以处理宽松的服装,如长裙,当服装远离身体时,规范化过程变得不明确,导致不连续和碎片化的结果。为了克服这个限制,我们提出了FreeCloth,一种新颖的混合框架来建模具有挑战性的服装人体。我们的核心思想是使用专门的策略来建模不同的区域,这取决于它们是靠近身体还是远离身体。具体来说,我们将人体分割成三类:未穿衣服的、变形的和生成的。我们简单地复制不需要变形的未穿衣服的区域。对于靠近身体的变形区域,我们利用LBS来处理变形。至于生成的区域,对应于宽松的服装区域,我们引入了一种新颖的自由形态、部分感知生成器来建模它们,因为它们较少受到运动的影响。这种自由形态生成范式为我们的混合框架带来了增强的灵活性和表现力,使其能够捕捉具有挑战性的宽松服装(如裙子和连衣裙)的复杂几何细节。在具有宽松服装的基准数据集上的实验结果表明,FreeCloth实现了最先进的性能,具有卓越的视觉保真度和真实感,尤其是在最具挑战性的情况下。
🔬 方法详解
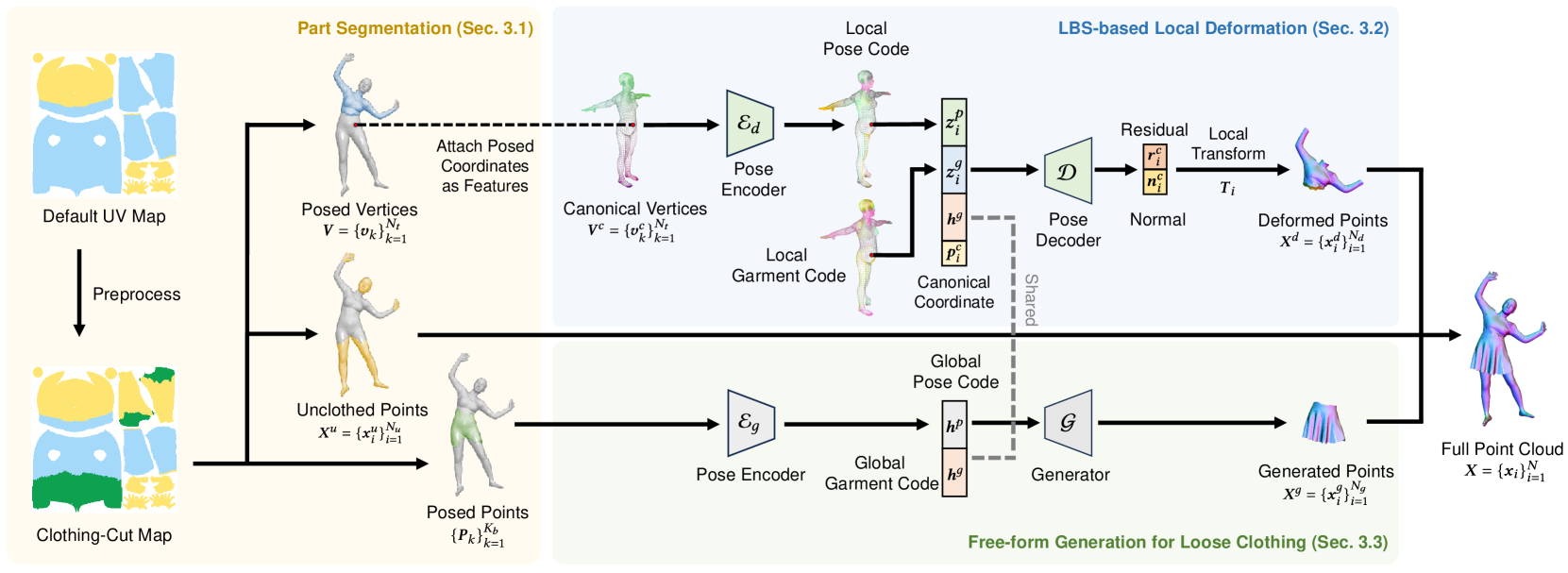
问题定义:论文旨在解决现有方法在处理宽松服装人体建模时,由于服装远离身体导致规范化过程不明确,容易产生不连续和碎片化的结果的问题。现有方法通常依赖于LBS,对于紧身衣物效果较好,但对于宽松衣物则表现不佳。
核心思路:论文的核心思路是根据人体不同区域的特点,采用不同的建模策略。对于靠近身体的区域,继续使用LBS进行建模;对于远离身体的宽松服装区域,则采用一种新的自由形态生成器进行建模。这样可以充分利用LBS在处理紧身衣物方面的优势,同时避免其在处理宽松衣物方面的不足。
技术框架:FreeCloth框架首先将人体分割成三个区域:未穿衣服的区域、变形的区域和生成的区域。对于未穿衣服的区域,直接复制;对于变形的区域,使用LBS进行建模;对于生成的区域,使用自由形态生成器进行建模。然后,将这三个区域的结果进行融合,得到最终的服装人体模型。
关键创新:论文最重要的技术创新点是提出了自由形态生成器,用于建模宽松服装区域。该生成器能够学习服装的形状和结构,并根据人体的姿势生成逼真的服装变形。与传统的LBS方法相比,自由形态生成器具有更强的灵活性和表现力,能够更好地处理宽松服装的建模。
关键设计:自由形态生成器采用了一种部分感知的网络结构,能够学习服装不同部分的特征。损失函数包括几何损失、平滑损失等,用于保证生成服装的形状和结构的合理性。具体的网络结构和参数设置在论文中有详细描述,但具体数值未知。
🖼️ 关键图片
📊 实验亮点
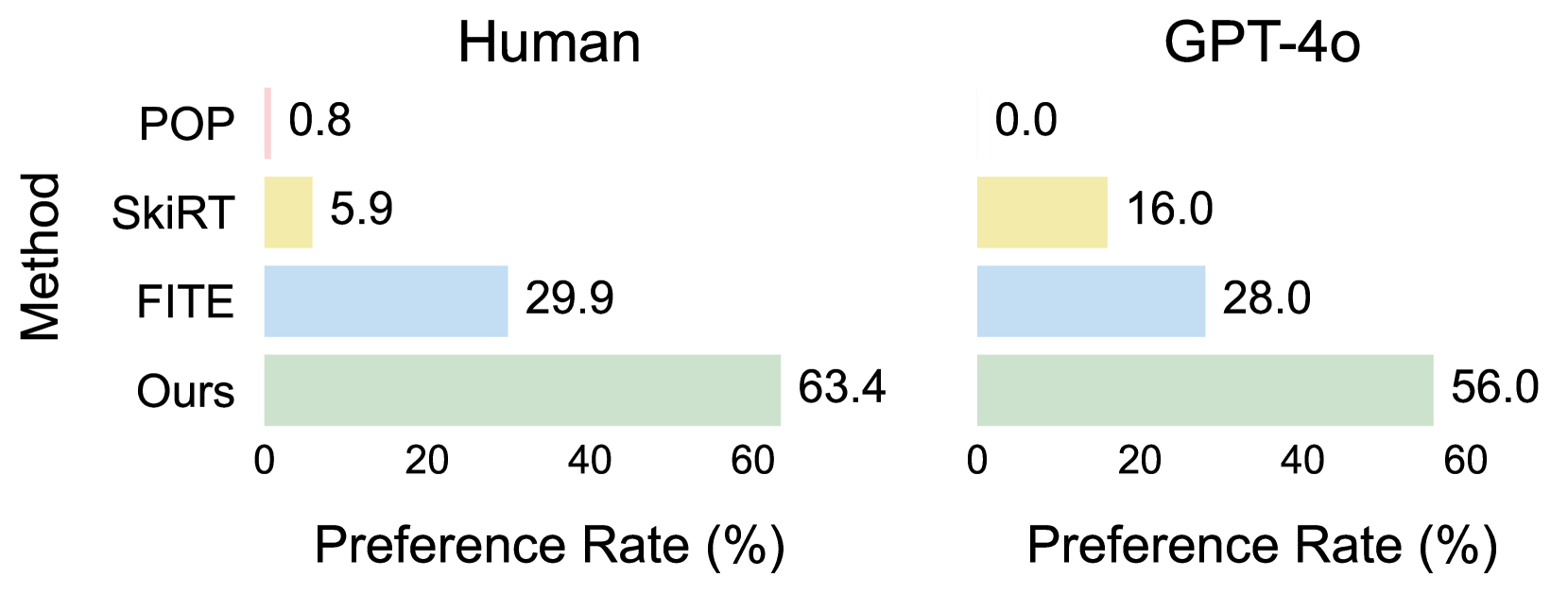
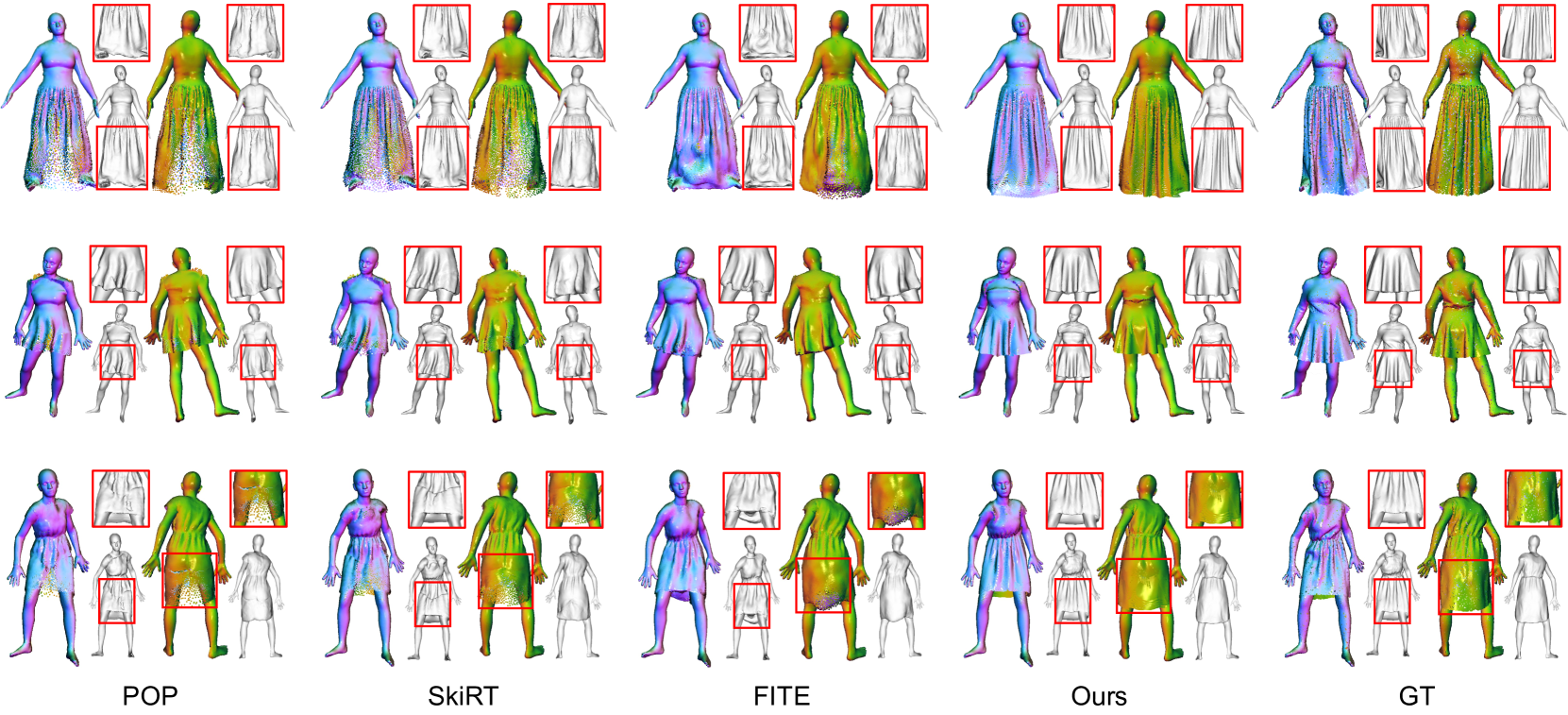
实验结果表明,FreeCloth在宽松服装人体建模方面达到了最先进的性能,尤其是在处理长裙等复杂服装时,能够生成更加逼真和自然的服装变形。与现有方法相比,FreeCloth在视觉保真度和真实感方面都有显著提升,有效解决了现有方法在处理宽松服装时容易出现的不连续和碎片化问题。具体性能数据未知。
🎯 应用场景
FreeCloth的研究成果可以应用于虚拟现实、增强现实、游戏、电影等领域,用于创建更加逼真和自然的虚拟人物。该技术可以提升用户在虚拟环境中的沉浸感和交互体验,并为服装设计和动画制作提供新的工具和方法。未来,该技术有望进一步扩展到更复杂的服装类型和人体姿势,实现更加精细和个性化的虚拟人物定制。
📄 摘要(原文)
Achieving realistic animated human avatars requires accurate modeling of pose-dependent clothing deformations. Existing learning-based methods heavily rely on the Linear Blend Skinning (LBS) of minimally-clothed human models like SMPL to model deformation. However, they struggle to handle loose clothing, such as long dresses, where the canonicalization process becomes ill-defined when the clothing is far from the body, leading to disjointed and fragmented results. To overcome this limitation, we propose FreeCloth, a novel hybrid framework to model challenging clothed humans. Our core idea is to use dedicated strategies to model different regions, depending on whether they are close to or distant from the body. Specifically, we segment the human body into three categories: unclothed, deformed, and generated. We simply replicate unclothed regions that require no deformation. For deformed regions close to the body, we leverage LBS to handle the deformation. As for the generated regions, which correspond to loose clothing areas, we introduce a novel free-form, part-aware generator to model them, as they are less affected by movements. This free-form generation paradigm brings enhanced flexibility and expressiveness to our hybrid framework, enabling it to capture the intricate geometric details of challenging loose clothing, such as skirts and dresses. Experimental results on the benchmark dataset featuring loose clothing demonstrate that FreeCloth achieves state-of-the-art performance with superior visual fidelity and realism, particularly in the most challenging cases.