LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
作者: Tiantian Geng, Jinrui Zhang, Qingni Wang, Teng Wang, Jinming Duan, Feng Zheng
分类: cs.CV, cs.CL, cs.LG, cs.MM
发布日期: 2024-11-29 (更新: 2025-03-20)
备注: Accepted by CVPR2025
💡 一句话要点
提出LongVALE基准,用于长视频时序感知的全模态理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态学习 事件检测 视频标注 视频大语言模型
📋 核心要点
- 现有视频理解方法缺乏对长视频中细粒度事件和多模态信息的综合理解能力。
- 论文提出自动标注流程,构建包含视觉、音频、语言和事件信息的LongVALE基准。
- 实验表明,LongVALE能够有效提升视频大语言模型在全模态时序视频理解方面的性能。
📝 摘要(中文)
本文提出了一种针对长视频时序感知的视觉-音频-语言-事件(LongVALE)基准。现有视频理解研究大多局限于粗粒度或仅视觉模态的任务。为了解决缺乏细粒度事件标注的多模态视频数据以及人工标注成本高昂的问题,本文设计了一个自动流程,包括高质量多模态视频过滤、语义连贯的全模态事件边界检测以及跨模态相关感知的事件描述。由此构建了LongVALE,这是首个包含105K全模态事件、精确时间边界和详细关系感知描述的视觉-音频-语言事件理解基准,涵盖8.4K高质量长视频。此外,本文还构建了一个基线模型,首次利用LongVALE使视频大语言模型(LLMs)能够进行全模态细粒度时序视频理解。大量实验证明了LongVALE在推进全面多模态视频理解方面的有效性和巨大潜力。
🔬 方法详解
问题定义:现有视频理解方法主要集中在粗粒度或仅视觉模态的任务上,忽略了长视频中蕴含的丰富多模态信息(视觉、音频、语言)以及事件之间的时间关系。人工标注细粒度的多模态长视频数据成本高昂,阻碍了全面多模态视频理解的发展。
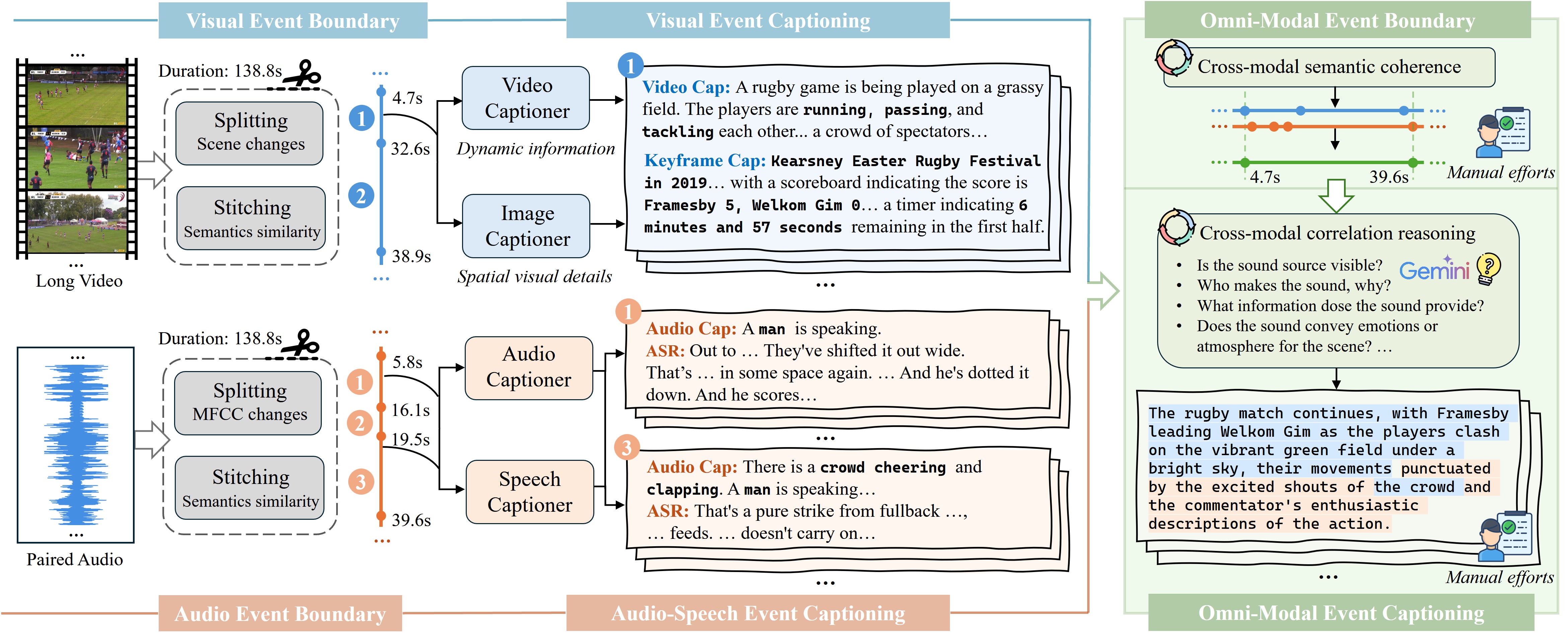
核心思路:论文的核心思路是设计一个自动化的流程,从大规模视频数据中筛选出高质量的多模态长视频,并自动标注细粒度的事件边界和事件描述。通过构建大规模的LongVALE基准,为训练和评估多模态长视频理解模型提供数据支撑。
技术框架:LongVALE的构建流程主要包括三个阶段:1) 高质量多模态视频过滤:从海量视频数据中筛选出包含清晰视觉信息、丰富音频信息和连贯故事情节的视频。2) 语义连贯的全模态事件边界检测:利用多模态信息检测视频中事件的起始和结束时间点,确保事件边界的语义连贯性。3) 跨模态相关感知的事件描述:为每个事件生成详细的描述,捕捉事件中不同模态之间的关联关系。
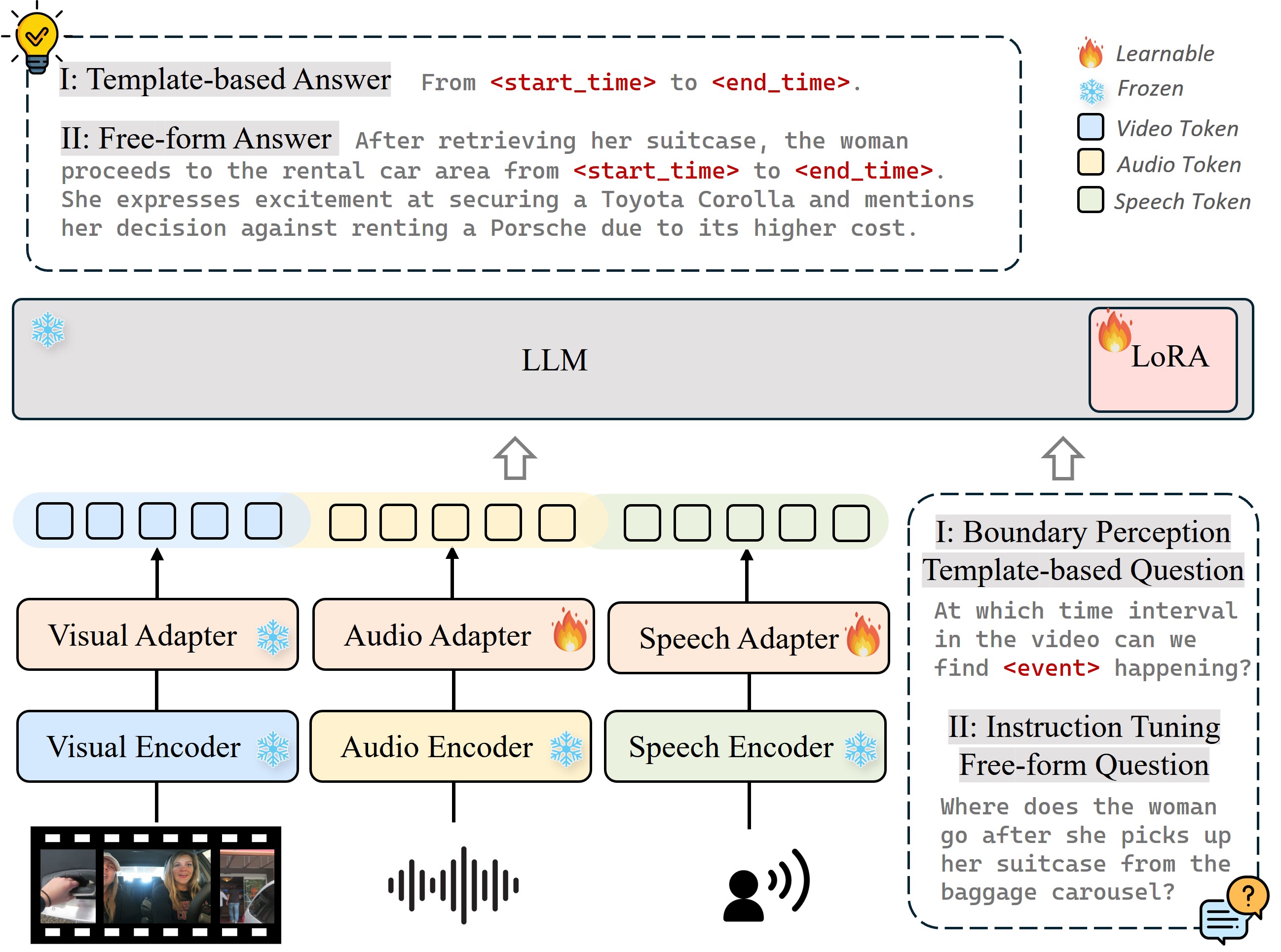
关键创新:LongVALE基准的创新之处在于:1) 首次提出了一个包含视觉、音频、语言和事件信息的综合性长视频理解基准。2) 设计了一个自动化的标注流程,降低了标注成本,实现了大规模数据的构建。3) 强调了事件之间的时间关系和跨模态关联,更贴近真实场景。
关键设计:在多模态视频过滤阶段,可能使用了基于规则和机器学习的方法,例如音频清晰度检测、视频质量评估等。在事件边界检测阶段,可能使用了时序模型(如Transformer)来捕捉事件之间的时间依赖关系。在事件描述阶段,可能使用了跨模态注意力机制来融合不同模态的信息。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述。
🖼️ 关键图片
📊 实验亮点
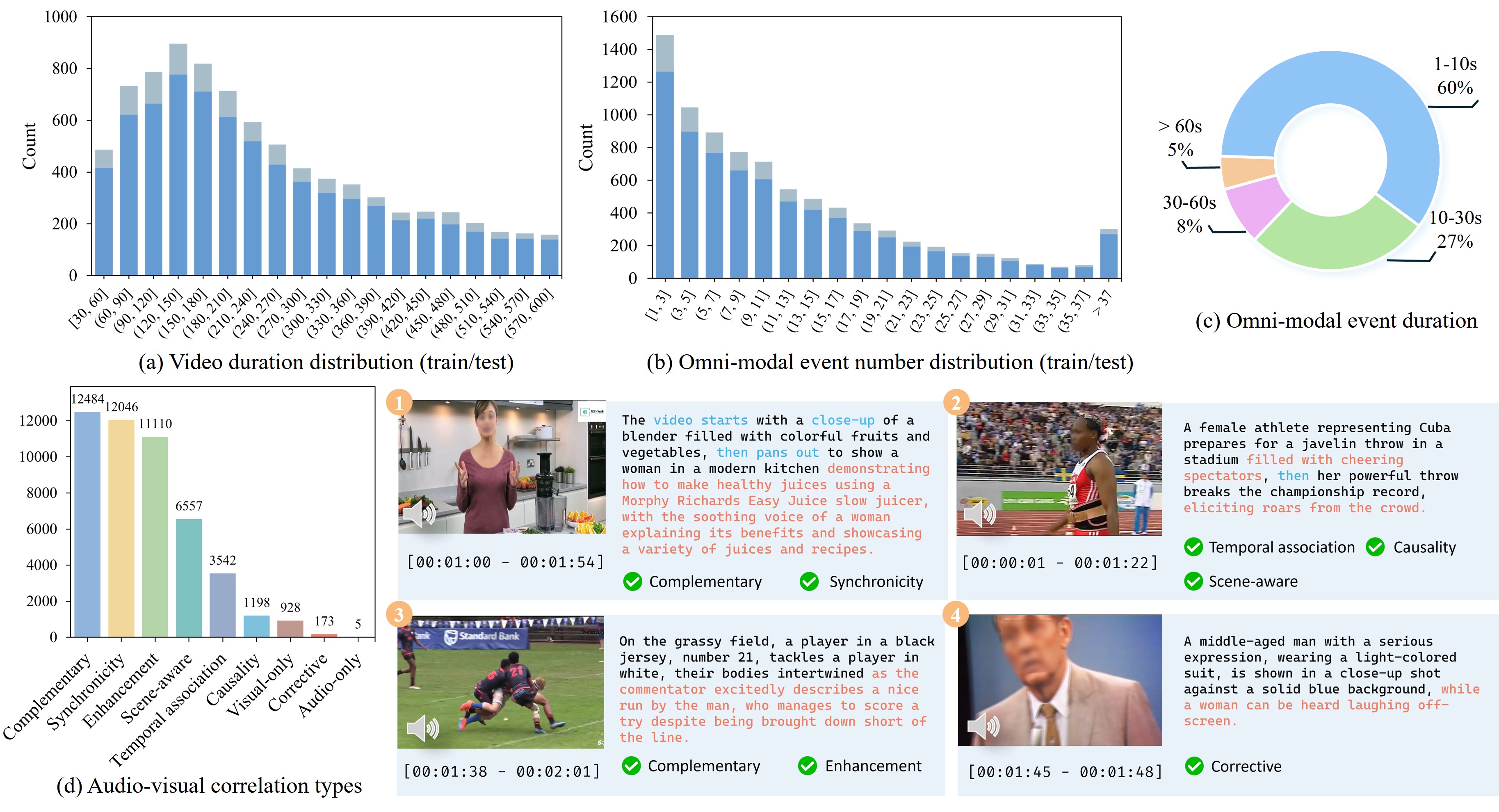
论文构建了包含8.4K长视频和105K事件的LongVALE基准,并基于此训练了一个视频大语言模型基线。实验结果表明,该基线模型在全模态细粒度时序视频理解方面取得了显著的性能提升,验证了LongVALE基准的有效性和潜力。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能视频分析、视频搜索、智能监控、人机交互等领域。例如,可以利用LongVALE训练的模型来理解长视频的内容,从而实现更精准的视频搜索和推荐。在智能监控领域,可以自动检测异常事件并生成报警信息。在人机交互领域,可以实现更自然、更智能的视频对话。
📄 摘要(原文)
Despite impressive advancements in video understanding, most efforts remain limited to coarse-grained or visual-only video tasks. However, real-world videos encompass omni-modal information (vision, audio, and speech) with a series of events forming a cohesive storyline. The lack of multi-modal video data with fine-grained event annotations and the high cost of manual labeling are major obstacles to comprehensive omni-modality video perception. To address this gap, we propose an automatic pipeline consisting of high-quality multi-modal video filtering, semantically coherent omni-modal event boundary detection, and cross-modal correlation-aware event captioning. In this way, we present LongVALE, the first-ever Vision-Audio-Language Event understanding benchmark comprising 105K omni-modal events with precise temporal boundaries and detailed relation-aware captions within 8.4K high-quality long videos. Further, we build a baseline that leverages LongVALE to enable video large language models (LLMs) for omni-modality fine-grained temporal video understanding for the first time. Extensive experiments demonstrate the effectiveness and great potential of LongVALE in advancing comprehensive multi-modal video understanding.