Bootstraping Clustering of Gaussians for View-consistent 3D Scene Understanding
作者: Wenbo Zhang, Lu Zhang, Ping Hu, Liqian Ma, Yunzhi Zhuge, Huchuan Lu
分类: cs.CV, cs.LG
发布日期: 2024-11-29 (更新: 2025-05-18)
备注: Accepted to AAAI25
🔗 代码/项目: GITHUB
💡 一句话要点
提出FreeGS以解决无监督3D场景理解中的语义一致性问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 无监督学习 语义嵌入 高斯点云 跨视图一致性 深度学习 计算机视觉
📋 核心要点
- 现有方法依赖于2D监督,导致跨视图语义一致性不足,影响3D场景理解的效果。
- 提出FreeGS框架,通过引入身份耦合语义场(IDSF)实现无监督的3D场景理解,避免2D标签依赖。
- 在多个数据集上进行的实验表明,FreeGS在性能上与最先进的方法相当,同时简化了数据处理流程。
📝 摘要(中文)
将语义注入到3D高斯点云(3DGS)中最近引起了广泛关注。现有方法通常依赖于2D基础模型(如CLIP和SAM)提取3D语义特征,这种重度依赖2D监督的方式可能会削弱跨视图的语义一致性,并需要复杂的数据准备过程,从而阻碍了视图一致的场景理解。本文提出了FreeGS,一个无监督的语义嵌入3DGS框架,能够在无需2D标签的情况下实现视图一致的3D场景理解。我们引入了身份耦合语义场(IDSF),为每个高斯捕获语义表示和视图一致的实例索引。通过两步交替优化策略,IDSF能够提取3D空间中的一致实例,同时稳定地注入2D空间的语义。实验结果表明,FreeGS在多个数据集上表现出色,且避免了复杂的数据预处理工作。
🔬 方法详解
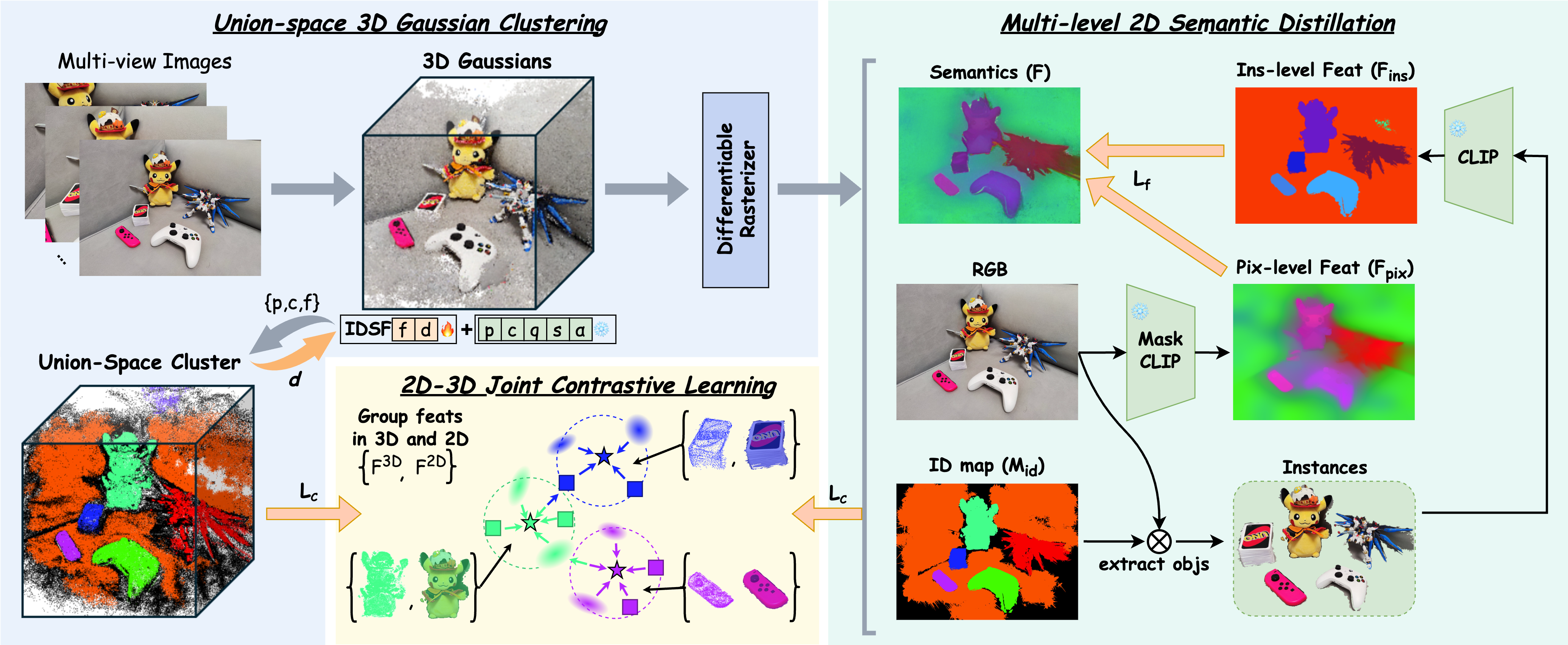
问题定义:本文旨在解决现有3D场景理解方法中由于依赖2D标签而导致的语义一致性不足问题。现有方法在跨视图理解中存在复杂的数据准备和处理流程,限制了其应用。
核心思路:提出FreeGS框架,通过引入身份耦合语义场(IDSF),实现无监督的3D场景理解。IDSF同时捕获语义表示和视图一致的实例索引,减少对2D标签的依赖。
技术框架:FreeGS的整体架构包括两个主要模块:首先,通过IDSF提取3D空间中的一致实例;其次,利用2D-3D联合对比损失增强语义与几何信息的互补性。
关键创新:最重要的创新点在于引入IDSF,使得语义和实例索引的捕获相互促进,形成闭环优化。与现有方法相比,FreeGS在无监督条件下实现了更好的语义一致性。
关键设计:在损失函数设计上,采用2D-3D联合对比损失,以增强3D几何与语义信息的互补性。此外,优化过程采用两步交替策略,确保语义和实例的稳定性。
🖼️ 关键图片


📊 实验亮点
在多个数据集(如LERF-Mask、3D-OVS和ScanNet)上的实验结果显示,FreeGS在语义分割、物体选择和3D物体检测等任务中表现出色,性能与最先进的方法相当,同时避免了复杂的数据预处理,提升了效率。
🎯 应用场景
该研究具有广泛的应用潜力,尤其在自动驾驶、机器人导航和虚拟现实等领域。通过实现无监督的3D场景理解,FreeGS能够降低数据标注成本,提高系统的灵活性和适应性,推动智能系统的进一步发展。
📄 摘要(原文)
Injecting semantics into 3D Gaussian Splatting (3DGS) has recently garnered significant attention. While current approaches typically distill 3D semantic features from 2D foundational models (e.g., CLIP and SAM) to facilitate novel view segmentation and semantic understanding, their heavy reliance on 2D supervision can undermine cross-view semantic consistency and necessitate complex data preparation processes, therefore hindering view-consistent scene understanding. In this work, we present FreeGS, an unsupervised semantic-embedded 3DGS framework that achieves view-consistent 3D scene understanding without the need for 2D labels. Instead of directly learning semantic features, we introduce the IDentity-coupled Semantic Field (IDSF) into 3DGS, which captures both semantic representations and view-consistent instance indices for each Gaussian. We optimize IDSF with a two-step alternating strategy: semantics help to extract coherent instances in 3D space, while the resulting instances regularize the injection of stable semantics from 2D space. Additionally, we adopt a 2D-3D joint contrastive loss to enhance the complementarity between view-consistent 3D geometry and rich semantics during the bootstrapping process, enabling FreeGS to uniformly perform tasks such as novel-view semantic segmentation, object selection, and 3D object detection. Extensive experiments on LERF-Mask, 3D-OVS, and ScanNet datasets demonstrate that FreeGS performs comparably to state-of-the-art methods while avoiding the complex data preprocessing workload. Our code is publicly available at https://github.com/wb014/FreeGS.