Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation
作者: Luca Barsellotti, Lorenzo Bianchi, Nicola Messina, Fabio Carrara, Marcella Cornia, Lorenzo Baraldi, Fabrizio Falchi, Rita Cucchiara
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-11-28 (更新: 2025-09-16)
备注: ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Talk2DINO:融合自监督视觉骨干网络与语言,实现开放词汇分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇分割 自监督学习 视觉语言模型 DINOv2 CLIP 图像分割 跨模态学习
📋 核心要点
- 现有开放词汇分割方法依赖CLIP等模型,但其全局对齐方式导致空间定位精度不足,限制了分割效果。
- Talk2DINO通过学习映射函数,将CLIP的语言理解能力与DINOv2的精细视觉编码相结合,无需微调。
- 实验表明,Talk2DINO在多个无监督OVS基准上达到SOTA,生成更自然、噪声更少的分割结果。
📝 摘要(中文)
开放词汇分割(OVS)旨在根据自由文本概念分割图像,而无需预定义的训练类别。现有的视觉-语言模型(如CLIP)可以通过利用Vision Transformer的粗略空间信息来生成分割掩码,但由于图像和文本特征的全局对齐,它们在空间定位方面面临挑战。相反,像DINO这样的自监督视觉模型擅长细粒度的视觉编码,但缺乏与语言的集成。为了弥合这一差距,我们提出了Talk2DINO,一种新颖的混合方法,它结合了DINOv2的空间精度和CLIP的语言理解能力。我们的方法通过学习到的映射函数将CLIP的文本嵌入与DINOv2的patch级别特征对齐,而无需微调底层骨干网络。在训练时,我们利用DINOv2的注意力图来选择性地将局部视觉patch与文本嵌入对齐。我们表明,Talk2DINO强大的语义和定位能力可以增强分割过程,从而产生更自然和更少噪声的分割,并且我们的方法还可以有效地将前景对象与背景区分开来。实验结果表明,Talk2DINO在多个无监督OVS基准测试中实现了最先进的性能。源代码和模型可在https://lorebianchi98.github.io/Talk2DINO/公开获取。
🔬 方法详解
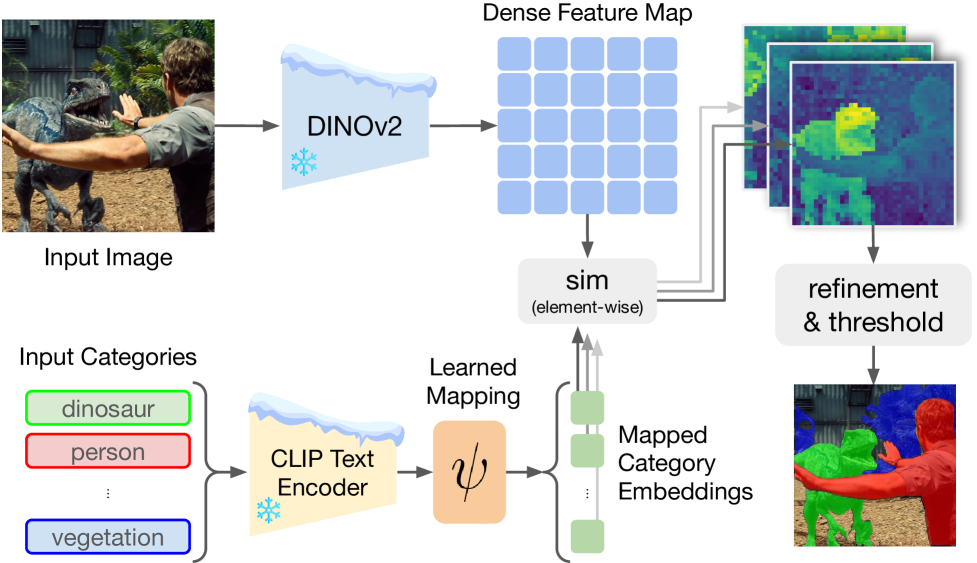
问题定义:开放词汇分割(OVS)旨在根据任意文本描述分割图像,无需预先定义类别。现有方法,如直接使用CLIP,虽然具备一定的分割能力,但由于CLIP的全局图像-文本对齐方式,导致空间定位精度较差,分割结果往往不够精细,存在噪声。
核心思路:Talk2DINO的核心思路是将CLIP的语言理解能力与DINOv2的精细视觉特征相结合。DINOv2擅长学习图像的局部特征,但缺乏语言信息。通过学习一个映射函数,将CLIP的文本嵌入与DINOv2的patch级别特征对齐,从而实现文本引导的精细分割。
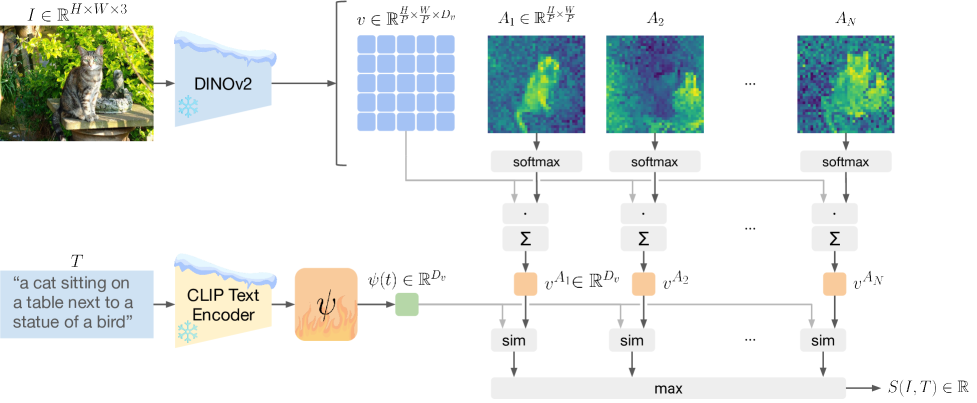
技术框架:Talk2DINO的整体框架包含以下几个主要模块:1) 使用CLIP提取文本嵌入;2) 使用DINOv2提取图像的patch级别特征;3) 学习一个映射函数,将CLIP的文本嵌入映射到DINOv2的特征空间;4) 利用DINOv2的注意力图,选择性地将局部视觉patch与文本嵌入对齐;5) 基于对齐后的特征,生成分割掩码。
关键创新:Talk2DINO的关键创新在于将CLIP的全局语言信息与DINOv2的局部视觉特征进行有效融合。与直接使用CLIP进行分割相比,Talk2DINO能够更好地利用图像的局部信息,从而提高分割精度。此外,该方法无需对CLIP和DINOv2进行微调,降低了训练成本。
关键设计:在训练过程中,使用了DINOv2的注意力图来指导文本嵌入与视觉patch的对齐。具体来说,对于每个文本嵌入,只选择与该文本相关的视觉patch进行对齐,从而减少了噪声。映射函数的具体形式未知,但其目标是最小化文本嵌入和对应视觉patch之间的距离。损失函数的设计也未知,但推测是基于对比学习的损失函数,鼓励相关的patch和文本嵌入靠近,不相关的patch和文本嵌入远离。
🖼️ 关键图片

📊 实验亮点
Talk2DINO在多个无监督开放词汇分割基准测试中取得了最先进的性能。具体的数据提升幅度未知,但论文强调了其分割结果更自然、噪声更少,并且能够有效区分前景对象和背景。这些结果表明,Talk2DINO能够有效地融合语言信息和视觉特征,从而提高分割精度。
🎯 应用场景
Talk2DINO在图像编辑、自动驾驶、机器人视觉等领域具有广泛的应用前景。例如,可以用于根据用户的文本描述自动分割图像中的对象,从而实现智能图像编辑。在自动驾驶中,可以用于识别和分割道路上的各种物体,如车辆、行人、交通标志等。在机器人视觉中,可以用于引导机器人抓取或操作特定的物体。
📄 摘要(原文)
Open-Vocabulary Segmentation (OVS) aims at segmenting images from free-form textual concepts without predefined training classes. While existing vision-language models such as CLIP can generate segmentation masks by leveraging coarse spatial information from Vision Transformers, they face challenges in spatial localization due to their global alignment of image and text features. Conversely, self-supervised visual models like DINO excel in fine-grained visual encoding but lack integration with language. To bridge this gap, we present Talk2DINO, a novel hybrid approach that combines the spatial accuracy of DINOv2 with the language understanding of CLIP. Our approach aligns the textual embeddings of CLIP to the patch-level features of DINOv2 through a learned mapping function without the need to fine-tune the underlying backbones. At training time, we exploit the attention maps of DINOv2 to selectively align local visual patches with textual embeddings. We show that the powerful semantic and localization abilities of Talk2DINO can enhance the segmentation process, resulting in more natural and less noisy segmentations, and that our approach can also effectively distinguish foreground objects from the background. Experimental results demonstrate that Talk2DINO achieves state-of-the-art performance across several unsupervised OVS benchmarks. Source code and models are publicly available at: https://lorebianchi98.github.io/Talk2DINO/.