Enhancing Parameter-Efficient Fine-Tuning of Vision Transformers through Frequency-Based Adaptation
作者: Son Thai Ly, Hien V. Nguyen
分类: cs.CV, cs.LG
发布日期: 2024-11-28
备注: 24 pages
🔗 代码/项目: GITHUB
💡 一句话要点
FreqFit:通过频域自适应增强Vision Transformer的参数高效微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision Transformer 参数高效微调 频域分析 高频特征 图像分类
📋 核心要点
- 现有PEFT方法在Vision Transformer微调中,对高频信息的捕捉能力不足,限制了模型对图像细节的识别。
- FreqFit通过在ViT块间引入频域微调模块,增强模型对高频特征的敏感性,从而提升模型性能。
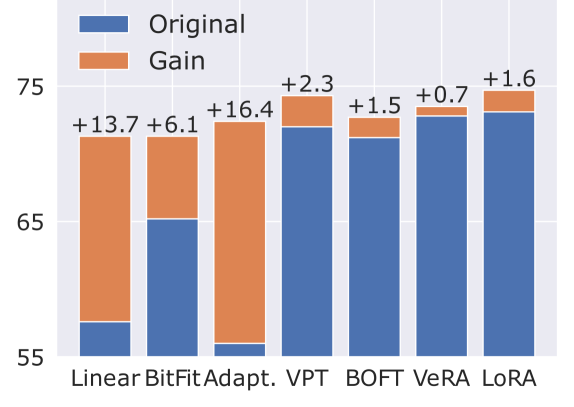
- 实验表明,FreqFit与多种PEFT方法结合,在多个数据集上均有显著提升,最高达16%,且无需额外正则化。
📝 摘要(中文)
参数高效微调(PEFT)方法在Vision Transformer基础模型的适配中日益流行。这些方法优化有限的参数子集,无需微调整个模型即可实现高效适配,同时保持有竞争力的性能。然而,传统的PEFT方法可能限制模型捕获复杂模式的能力,特别是那些与高频频谱相关的模式。由于现有研究表明高频特征对于区分细微图像结构至关重要,这种限制变得尤为突出。为了解决这个问题,我们引入了FreqFit,一个位于ViT块之间的新型频率微调模块,以增强模型的适应性。FreqFit简单但非常有效,可以与所有现有的PEFT方法集成,以提高它们的性能。通过在频域中操作特征,我们的方法使模型能够更有效地捕获细微的模式。在24个数据集上使用监督和自监督基础模型以及各种最先进的PEFT方法进行的大量实验表明,FreqFit始终优于原始PEFT方法,性能提升范围从1%到16%。例如,FreqFit-LoRA在CIFAR100上的表现超过了最先进的基线10%以上,即使没有应用正则化或强数据增强。为了便于复现,源代码可在https://github.com/tsly123/FreqFiT 获取。
🔬 方法详解
问题定义:论文旨在解决Vision Transformer在参数高效微调(PEFT)过程中,对图像高频信息利用不足的问题。现有PEFT方法主要集中在调整模型的部分参数,虽然降低了计算成本,但也可能损失了模型捕捉图像细微结构(高频信息)的能力,影响模型性能。
核心思路:论文的核心思路是在ViT块之间插入一个频率微调模块(FreqFit),该模块在频域上对特征进行操作,从而增强模型对高频信息的敏感性。通过在频域进行特征调整,模型能够更好地捕捉图像的细节和纹理信息,从而提升整体性能。
技术框架:FreqFit的整体框架是在Vision Transformer的每个ViT块之间插入FreqFit模块。该模块首先将ViT块输出的特征图转换到频域,然后在频域上进行参数化的调整,最后将调整后的特征图转换回空间域,作为下一个ViT块的输入。FreqFit可以与现有的各种PEFT方法(如LoRA、Adapter等)结合使用。
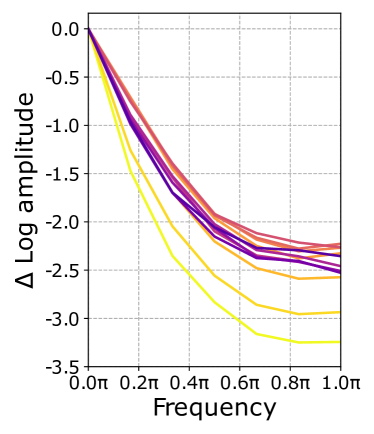
关键创新:FreqFit的关键创新在于将频域操作引入到Vision Transformer的参数高效微调中。与传统的PEFT方法直接在空间域调整参数不同,FreqFit通过在频域调整特征,能够更有效地控制模型对不同频率信息的敏感度,从而更好地捕捉图像的细节信息。
关键设计:FreqFit模块的关键设计包括:1) 使用离散余弦变换(DCT)将特征图转换到频域;2) 在频域上使用可学习的参数对不同频率分量进行加权;3) 使用逆离散余弦变换(IDCT)将调整后的频域特征转换回空间域。具体参数设置包括DCT和IDCT的尺寸、可学习权重的初始化方式等。论文中没有明确指出损失函数的设计,推测是沿用原PEFT方法的损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FreqFit能够显著提升现有PEFT方法的性能。例如,FreqFit-LoRA在CIFAR100数据集上超过了最先进的基线10%以上,且无需额外的正则化或数据增强。在其他23个数据集上的实验也表明,FreqFit能够稳定地提升各种PEFT方法的性能,提升幅度在1%到16%之间。
🎯 应用场景
FreqFit可应用于各种需要对Vision Transformer进行参数高效微调的场景,例如图像分类、目标检测、图像分割等。该方法尤其适用于需要关注图像细节信息的任务,如医学图像分析、遥感图像分析等。通过增强模型对高频信息的捕捉能力,FreqFit有望提升这些应用场景下的模型性能。
📄 摘要(原文)
Adapting vision transformer foundation models through parameter-efficient fine-tuning (PEFT) methods has become increasingly popular. These methods optimize a limited subset of parameters, enabling efficient adaptation without the need to fine-tune the entire model while still achieving competitive performance. However, traditional PEFT methods may limit the model's capacity to capture complex patterns, especially those associated with high-frequency spectra. This limitation becomes particularly problematic as existing research indicates that high-frequency features are crucial for distinguishing subtle image structures. To address this issue, we introduce FreqFit, a novel Frequency Fine-tuning module between ViT blocks to enhance model adaptability. FreqFit is simple yet surprisingly effective, and can be integrated with all existing PEFT methods to boost their performance. By manipulating features in the frequency domain, our approach allows models to capture subtle patterns more effectively. Extensive experiments on 24 datasets, using both supervised and self-supervised foundational models with various state-of-the-art PEFT methods, reveal that FreqFit consistently improves performance over the original PEFT methods with performance gains ranging from 1% to 16%. For instance, FreqFit-LoRA surpasses the performances of state-of-the-art baselines on CIFAR100 by more than 10% even without applying regularization or strong augmentation. For reproducibility purposes, the source code is available at https://github.com/tsly123/FreqFiT.