Automatic Prompt Generation and Grounding Object Detection for Zero-Shot Image Anomaly Detection
作者: Tsun-Hin Cheung, Ka-Chun Fung, Songjiang Lai, Kwan-Ho Lin, Vincent Ng, Kin-Man Lam
分类: cs.CV, cs.MM
发布日期: 2024-11-28
备注: Accepted to APSIPA ASC 2024
💡 一句话要点
提出一种基于多模态零样本学习的工业图像异常检测方法,无需训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 异常检测 工业图像 多模态融合 大型语言模型 对象检测 图像-文本匹配
📋 核心要点
- 传统人工检测工业产品缺陷的方法效率低、主观性强且容易出错,亟需自动化解决方案。
- 该方法利用GPT-3生成文本提示,Grounding DINO定位产品,CLIP进行图像-文本匹配,实现零样本异常检测。
- 在MVTec-AD和VisA数据集上的实验表明,该方法无需训练即可有效检测各种缺陷和异常。
📝 摘要(中文)
本文提出了一种新颖的零样本、免训练的工业图像异常检测方法,该方法利用多模态机器学习流程,包含三个基础模型。首先,使用大型语言模型GPT-3生成描述正常和异常产品外观的文本提示。然后,使用名为Grounding DINO的 grounding 对象检测模型来定位图像中的产品。最后,使用零样本图像-文本匹配模型CLIP将裁剪后的产品图像块与生成的提示进行比较,以识别任何异常。在MVTec-AD和VisA两个工业产品图像数据集上的实验表明,该方法在检测各种类型的缺陷和异常方面具有很高的准确性,且无需模型训练。该模型实现了工业制造环境中高效、可扩展和客观的质量控制。
🔬 方法详解
问题定义:工业产品质量控制中,缺陷和异常检测至关重要。传统方法依赖人工检测,效率低下且主观性强,容易出错。现有基于深度学习的异常检测方法通常需要大量正常样本进行训练,难以适应新型产品或缺陷类型。因此,如何在缺乏训练数据的情况下,实现高效准确的工业图像异常检测是一个关键问题。
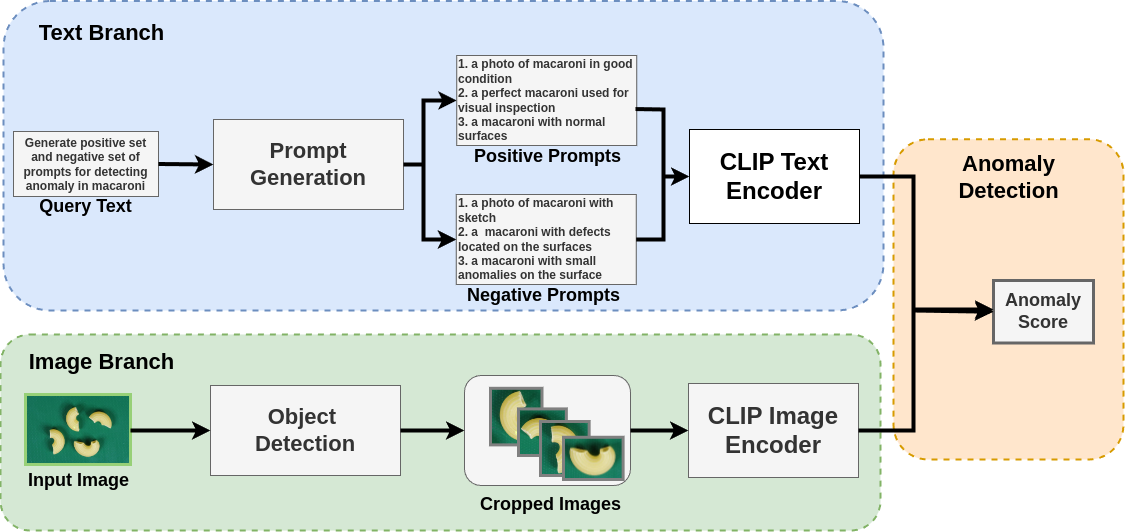
核心思路:本文的核心思路是利用大型语言模型(LLM)的知识和多模态匹配能力,将图像异常检测问题转化为图像-文本匹配问题。通过LLM生成描述正常和异常产品外观的文本提示,然后将图像中的产品区域与这些提示进行比较,从而判断是否存在异常。这种方法无需训练,可以快速适应新的产品和缺陷类型。
技术框架:该方法包含三个主要模块:1) 提示生成模块:使用GPT-3等大型语言模型,根据产品类型和可能的缺陷类型,自动生成描述正常和异常产品外观的文本提示。2) 对象检测模块:使用Grounding DINO等 grounding 对象检测模型,在图像中定位目标产品区域,并将其裁剪出来。3) 图像-文本匹配模块:使用CLIP等零样本图像-文本匹配模型,计算裁剪后的产品图像与生成的文本提示之间的相似度,根据相似度判断是否存在异常。
关键创新:该方法最重要的创新点在于将大型语言模型和 grounding 对象检测模型引入到零样本异常检测任务中。通过LLM生成文本提示,弥补了传统方法中缺乏先验知识的不足。 grounding 对象检测模型能够精确定位产品区域,提高检测精度。这种多模态融合的方法,使得模型能够在没有训练数据的情况下,有效地检测各种类型的缺陷和异常。
关键设计:在提示生成模块中,需要设计合适的提示模板,引导LLM生成高质量的文本描述。在对象检测模块中,需要选择合适的 grounding 对象检测模型,并进行必要的微调,以提高检测精度。在图像-文本匹配模块中,需要选择合适的相似度度量方法,并设置合适的阈值,以区分正常和异常产品。
🖼️ 关键图片
📊 实验亮点
该方法在MVTec-AD和VisA数据集上取得了显著的成果,无需任何训练即可达到较高的检测精度。实验结果表明,该方法能够有效地检测各种类型的缺陷和异常,例如划痕、污渍、变形等。与传统的基于深度学习的异常检测方法相比,该方法具有更高的灵活性和可扩展性。
🎯 应用场景
该研究成果可广泛应用于工业制造领域的质量控制环节,例如汽车零部件、电子产品、纺织品等产品的缺陷检测。该方法能够降低人工检测成本,提高检测效率和准确性,实现生产过程的自动化和智能化。未来,该方法还可以扩展到其他领域的异常检测任务,例如医疗图像分析、安全监控等。
📄 摘要(原文)
Identifying defects and anomalies in industrial products is a critical quality control task. Traditional manual inspection methods are slow, subjective, and error-prone. In this work, we propose a novel zero-shot training-free approach for automated industrial image anomaly detection using a multimodal machine learning pipeline, consisting of three foundation models. Our method first uses a large language model, i.e., GPT-3. generate text prompts describing the expected appearances of normal and abnormal products. We then use a grounding object detection model, called Grounding DINO, to locate the product in the image. Finally, we compare the cropped product image patches to the generated prompts using a zero-shot image-text matching model, called CLIP, to identify any anomalies. Our experiments on two datasets of industrial product images, namely MVTec-AD and VisA, demonstrate the effectiveness of this method, achieving high accuracy in detecting various types of defects and anomalies without the need for model training. Our proposed model enables efficient, scalable, and objective quality control in industrial manufacturing settings.