Detailed Object Description with Controllable Dimensions
作者: Xinran Wang, Haiwen Zhang, Baoteng Li, Kongming Liang, Hao Sun, Zhongjiang He, Zhanyu Ma, Jun Guo
分类: cs.CV
发布日期: 2024-11-28 (更新: 2025-01-08)
备注: 11 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出Dimension Tailor,提升多模态大语言模型在可控维度上的物体描述能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物体描述 多模态大语言模型 可控维度 免训练 维度提取
📋 核心要点
- 现有的多模态大语言模型在生成物体描述时,可能包含与用户意图无关的内容,或遗漏重要的维度细节。
- Dimension Tailor通过维度提取、擦除和补充三个步骤,实现对物体描述中特定维度的可控增强。
- 实验结果表明,Dimension Tailor能够有效提升多模态大语言模型在可控物体描述方面的性能。
📝 摘要(中文)
本文提出了一种免训练的物体描述优化流程Dimension Tailor,旨在增强用户指定的物体维度细节。该流程包含维度提取、擦除和补充三个步骤,将描述分解为用户指定的维度。Dimension Tailor不仅可以提高物体细节的质量,还可以根据用户偏好灵活地包含或排除特定维度。大量实验表明,Dimension Tailor在可控物体描述方面是有效的,并且能够持续提升现有多模态大语言模型的性能。
🔬 方法详解
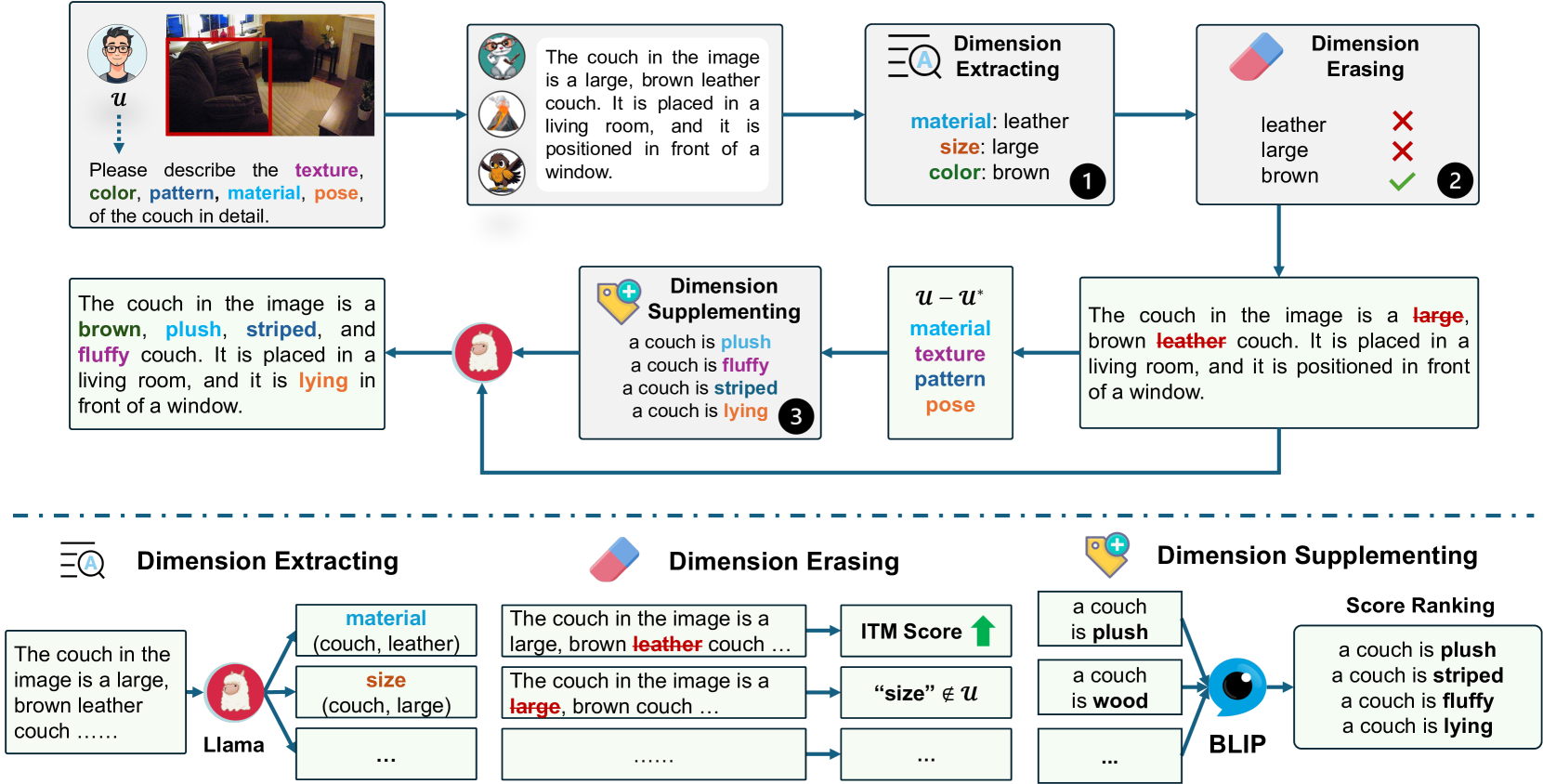
问题定义:现有的多模态大语言模型(MLLMs)在生成物体描述时,存在两个主要问题。一是生成的描述可能包含大量与用户意图无关的信息,导致信息冗余。二是可能忽略某些重要的物体维度细节,使得描述不够全面。这些问题限制了MLLMs在辅助视觉障碍人士理解物体差异方面的应用。
核心思路:Dimension Tailor的核心思路是将物体描述分解为用户指定的维度,然后针对这些维度进行选择性的增强或删除。通过这种方式,可以生成更符合用户需求的、更加精细和可控的物体描述。该方法无需重新训练模型,而是通过后处理的方式来优化现有MLLMs的输出。
技术框架:Dimension Tailor流程包含三个主要步骤: 1. 维度提取:从原始的物体描述中提取出与用户指定维度相关的信息。 2. 擦除:根据用户需求,选择性地从描述中移除某些维度的信息。 3. 补充:针对用户关心的维度,补充更详细的信息,以增强描述的质量。 整个流程旨在实现对物体描述的精细化控制,使其更符合用户的特定需求。
关键创新:Dimension Tailor的关键创新在于其免训练的特性和对物体描述维度的精细化控制。与需要重新训练模型的方法不同,Dimension Tailor可以直接应用于现有的MLLMs,无需额外的训练成本。通过维度提取、擦除和补充三个步骤,实现了对物体描述内容的高度可定制化。
关键设计:Dimension Tailor的具体实现细节(例如,维度提取的具体算法、擦除策略、补充信息的来源等)在论文中未详细说明,属于未知内容。但整体流程的设计思路清晰,易于理解和实现。代码已开源,方便研究者进行进一步的探索和改进。
🖼️ 关键图片


📊 实验亮点
Dimension Tailor能够持续提升现有多模态大语言模型的性能,在可控物体描述方面表现出色。具体性能数据和对比基线在摘要中有所提及,但未提供详细的数值结果。该方法无需训练,可直接应用于现有模型,具有很高的实用价值。
🎯 应用场景
Dimension Tailor在辅助视觉障碍人士理解物体差异方面具有重要的应用价值。通过提供可控维度的物体描述,可以帮助他们更好地理解周围环境,提高生活质量。此外,该技术还可以应用于电商领域的商品描述生成,根据用户需求定制商品信息,提升购物体验。未来,该技术有望在更多人机交互场景中发挥作用。
📄 摘要(原文)
Object description plays an important role for visually impaired individuals to understand and compare the differences between objects. Recent multimodal large language models(MLLMs) exhibit powerful perceptual abilities and demonstrate impressive potential for generating object-centric descriptions. However, the descriptions generated by such models may still usually contain a lot of content that is not relevant to the user intent or miss some important object dimension details. Under special scenarios, users may only need the details of certain dimensions of an object. In this paper, we propose a training-free object description refinement pipeline, Dimension Tailor, designed to enhance user-specified details in object descriptions. This pipeline includes three steps: dimension extracting, erasing, and supplementing, which decompose the description into user-specified dimensions. Dimension Tailor can not only improve the quality of object details but also offer flexibility in including or excluding specific dimensions based on user preferences. We conducted extensive experiments to demonstrate the effectiveness of Dimension Tailor on controllable object descriptions. Notably, the proposed pipeline can consistently improve the performance of the recent MLLMs. The code is currently accessible at https://github.com/xin-ran-w/ControllableObjectDescription.