ObjectRelator: Enabling Cross-View Object Relation Understanding Across Ego-Centric and Exo-Centric Perspectives
作者: Yuqian Fu, Runze Wang, Bin Ren, Guolei Sun, Biao Gong, Yanwei Fu, Danda Pani Paudel, Xuanjing Huang, Luc Van Gool
分类: cs.CV, cs.AI
发布日期: 2024-11-28 (更新: 2025-07-25)
备注: Accepted by ICCV25 (Highlight)
💡 一句话要点
ObjectRelator:通过多模态融合与跨视角对齐实现自中心和以外中心视角的物体关系理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨视角物体关系理解 自中心视角 以外中心视角 多模态融合 自监督学习
📋 核心要点
- 现有方法难以应对自中心和以外中心视角之间剧烈的视点变化,导致物体定位和分割精度下降,尤其是在复杂背景和外观变化大的情况下。
- ObjectRelator通过多模态条件融合(MCFuse)整合视觉和语言信息,并利用自监督学习进行跨视角物体对齐(XObjAlign),增强模型鲁棒性。
- 实验结果表明,ObjectRelator在Ego-Exo4D和HANDAL-X数据集上取得了state-of-the-art的性能,验证了其有效性。
📝 摘要(中文)
本文致力于解决计算机视觉中长期存在的自中心视角和以外中心视角之间的鸿沟问题。具体而言,我们关注新兴的自-外物体对应任务,该任务旨在通过分割理解自-外视角下的物体关系。虽然已经提出了许多分割模型,但大多数模型仅在单个图像(视角)上运行,这使得它们在跨视角场景中不实用。PSALM是一种最近提出的分割方法,它在此任务上表现出零样本能力,是一个值得注意的例外。然而,由于自视角和外视角之间剧烈的视点变化,PSALM无法准确定位和分割物体,尤其是在复杂的背景中或当物体外观发生显著变化时。为了解决这些问题,我们提出了一种名为ObjectRelator的新方法,该方法具有两个关键模块:多模态条件融合(MCFuse)和基于SSL的跨视角物体对齐(XObjAlign)。MCFuse引入了语言作为额外的线索,整合了视觉掩码和文本描述,以提高物体定位的准确性并防止错误的关联。XObjAlign通过自监督对齐来加强跨视角一致性,从而增强了对物体外观变化的鲁棒性。大量的实验表明,ObjectRelator在大型Ego-Exo4D基准和HANDAL-X(一个为跨视角分割而改编的数据集)上具有有效性,并取得了最先进的性能。代码已在http://yuqianfu.com/ObjectRelator上提供。
🔬 方法详解
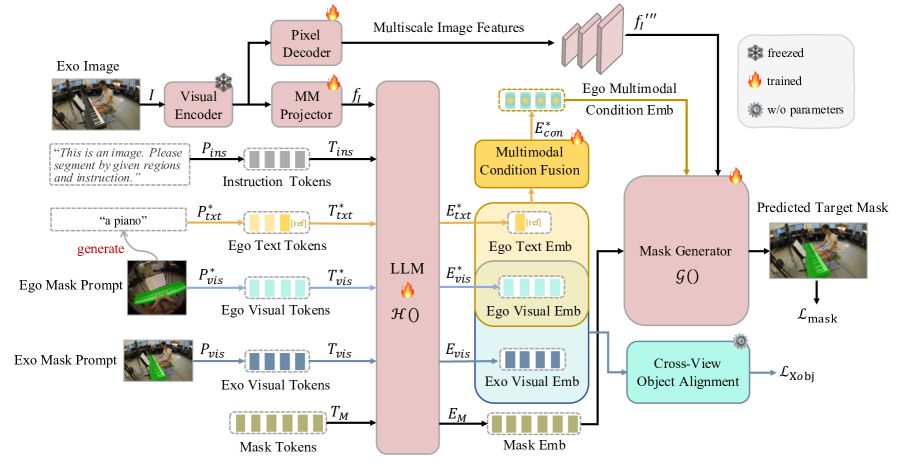
问题定义:论文旨在解决自中心视角(ego-centric)和以外中心视角(exo-centric)下物体关系理解的问题,即给定不同视角的图像,如何准确地定位和分割同一物体。现有方法,如PSALM,在视角变化剧烈、背景复杂或物体外观变化大的情况下,分割精度显著下降,无法有效建立跨视角物体对应关系。
核心思路:论文的核心思路是利用多模态信息融合和跨视角对齐来增强模型的鲁棒性和准确性。通过引入语言描述作为辅助信息,可以更准确地定位物体并避免错误关联。同时,通过自监督学习进行跨视角对齐,可以使模型更好地适应物体外观的变化。
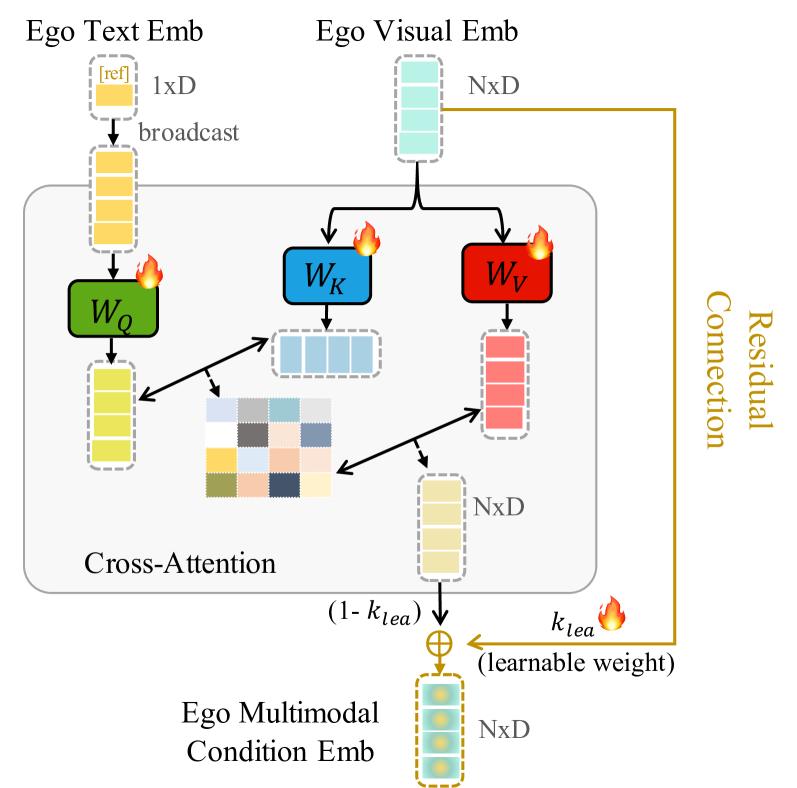
技术框架:ObjectRelator包含两个主要模块:多模态条件融合(MCFuse)和基于SSL的跨视角物体对齐(XObjAlign)。MCfuse模块将视觉掩码和文本描述融合,用于提升物体定位精度。XObjAlign模块则通过自监督学习,强制跨视角的一致性,增强模型对物体外观变化的适应性。整体流程是,首先利用MCfuse模块融合视觉和语言信息进行初步的物体定位和分割,然后利用XObjAlign模块进行跨视角对齐,进一步提升分割精度。
关键创新:论文的关键创新在于提出了多模态条件融合(MCFuse)和基于SSL的跨视角物体对齐(XObjAlign)两个模块。MCFuse模块通过引入语言信息,有效解决了视角变化带来的物体定位困难问题。XObjAlign模块则通过自监督学习,实现了跨视角特征对齐,增强了模型对物体外观变化的鲁棒性。与现有方法相比,ObjectRelator能够更准确地建立跨视角物体对应关系。
关键设计:MCFuse模块的具体实现细节未知,但可以推测其可能采用了某种注意力机制或融合策略,将视觉特征和文本特征进行有效融合。XObjAlign模块可能采用了对比学习或类似的技术,通过最小化跨视角相同物体的特征距离,最大化不同物体的特征距离,从而实现跨视角特征对齐。具体的损失函数和网络结构细节在摘要中未提及,需要查阅论文全文。
🖼️ 关键图片

📊 实验亮点
ObjectRelator在Ego-Exo4D和HANDAL-X数据集上取得了state-of-the-art的性能,表明其在跨视角物体关系理解方面具有显著优势。具体的性能数据和提升幅度需要在论文全文中查找。该方法通过多模态融合和跨视角对齐,有效解决了现有方法在视角变化、背景复杂和物体外观变化等方面的局限性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。例如,在机器人导航中,机器人可以通过自中心视角感知周围环境,并结合以外中心视角的地图信息,更准确地定位自身位置和规划路径。在自动驾驶中,车辆可以通过融合车载摄像头和路侧摄像头的信息,提高对周围环境的感知能力,从而提升驾驶安全性。在增强现实中,用户可以通过自中心视角与虚拟物体进行交互,并结合以外中心视角的场景信息,获得更沉浸式的体验。
📄 摘要(原文)
Bridging the gap between ego-centric and exo-centric views has been a long-standing question in computer vision. In this paper, we focus on the emerging Ego-Exo object correspondence task, which aims to understand object relations across ego-exo perspectives through segmentation. While numerous segmentation models have been proposed, most operate on a single image (view), making them impractical for cross-view scenarios. PSALM, a recently proposed segmentation method, stands out as a notable exception with its demonstrated zero-shot ability on this task. However, due to the drastic viewpoint change between ego and exo, PSALM fails to accurately locate and segment objects, especially in complex backgrounds or when object appearances change significantly. To address these issues, we propose ObjectRelator, a novel approach featuring two key modules: Multimodal Condition Fusion (MCFuse) and SSL-based Cross-View Object Alignment (XObjAlign). MCFuse introduces language as an additional cue, integrating both visual masks and textual descriptions to improve object localization and prevent incorrect associations. XObjAlign enforces cross-view consistency through self-supervised alignment, enhancing robustness to object appearance variations. Extensive experiments demonstrate ObjectRelator's effectiveness on the large-scale Ego-Exo4D benchmark and HANDAL-X (an adapted dataset for cross-view segmentation) with state-of-the-art performance. Code is made available at: http://yuqianfu.com/ObjectRelator.