RIGI: Rectifying Image-to-3D Generation Inconsistency via Uncertainty-aware Learning
作者: Jiacheng Wang, Zhedong Zheng, Wei Xu, Ping Liu
分类: cs.CV
发布日期: 2024-11-28
备注: Project Page: https://rigi3d.github.io/
💡 一句话要点
RIIGI:通过不确定性感知学习校正图像到3D生成的不一致性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 图像到3D生成 3D重建 不确定性感知学习 多视角一致性 3D高斯溅射
📋 核心要点
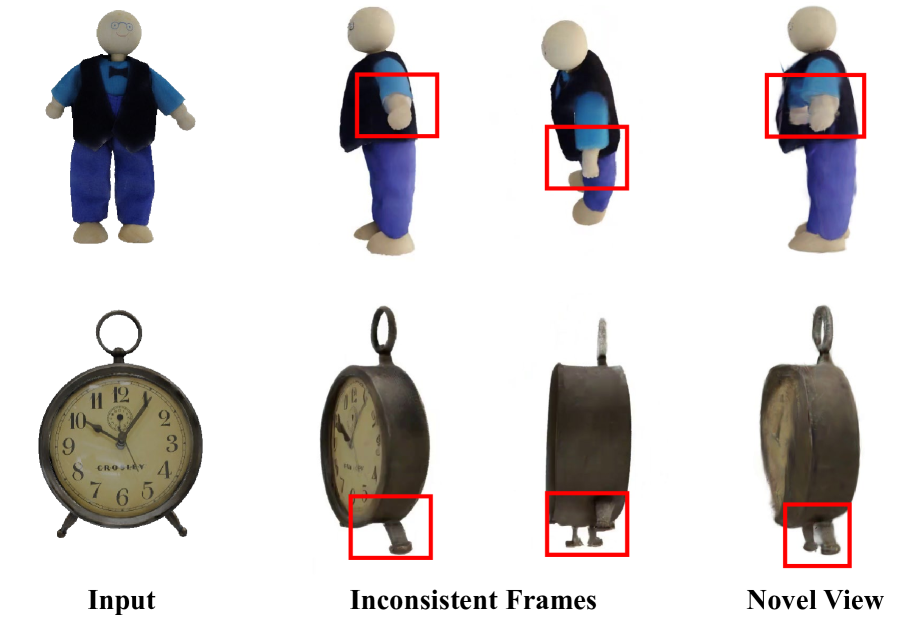
- 现有图像到3D生成方法依赖多视角图像作为中间媒介,但生成的多视角图像存在不一致性,导致3D重建出现噪声和伪影。
- 论文提出一种不确定性感知学习方法,通过估计多视角图像间的不确定性,并利用该不确定性进行正则化,从而减少不一致性的影响。
- 实验结果表明,该方法能够有效减少3D重建中的不一致性和伪影,显著提升3D生成质量。
📝 摘要(中文)
给定目标对象的单张图像,图像到3D生成旨在重建其纹理和几何形状。现有方法通常利用中间媒介,如多视角图像或视频,来弥合输入图像和3D目标之间的差距,从而指导形状和纹理的生成。然而,生成的多视角快照中的不一致性经常引入噪声和沿对象边界的伪影,从而破坏3D重建过程。为了解决这个挑战,我们利用3D高斯溅射(3DGS)进行3D重建,并将不确定性感知学习显式地集成到重建过程中。通过捕获两个高斯模型之间的随机性,我们估计一个不确定性图,该图随后用于不确定性感知正则化,以校正不一致性的影响。具体来说,我们同时优化两个高斯模型,通过评估来自相同视点的渲染图像之间的差异来计算不确定性图。基于不确定性图,我们应用自适应像素级损失权重来正则化模型,降低高不确定性区域的重建强度。这种方法动态地检测和减轻多视角标签中的冲突,从而产生更平滑的结果并有效地减少伪影。大量实验表明,我们的方法通过减少不一致性和伪影,有效地提高了3D生成质量。
🔬 方法详解
问题定义:图像到3D生成任务旨在从单张图像重建3D模型。现有方法依赖生成多视角图像作为中间表示,但由于生成过程的不完美,多视角图像之间存在不一致性,导致最终3D重建结果出现伪影和噪声,尤其是在物体边界处。现有方法缺乏有效处理这些不一致性的机制。
核心思路:论文的核心思路是利用不确定性感知学习来解决多视角图像不一致性问题。通过估计不同视角下生成图像之间的差异,得到一个不确定性图,该图反映了图像区域的不一致程度。然后,利用该不确定性图对重建过程进行正则化,降低高不确定性区域的重建强度,从而减少不一致性带来的影响。
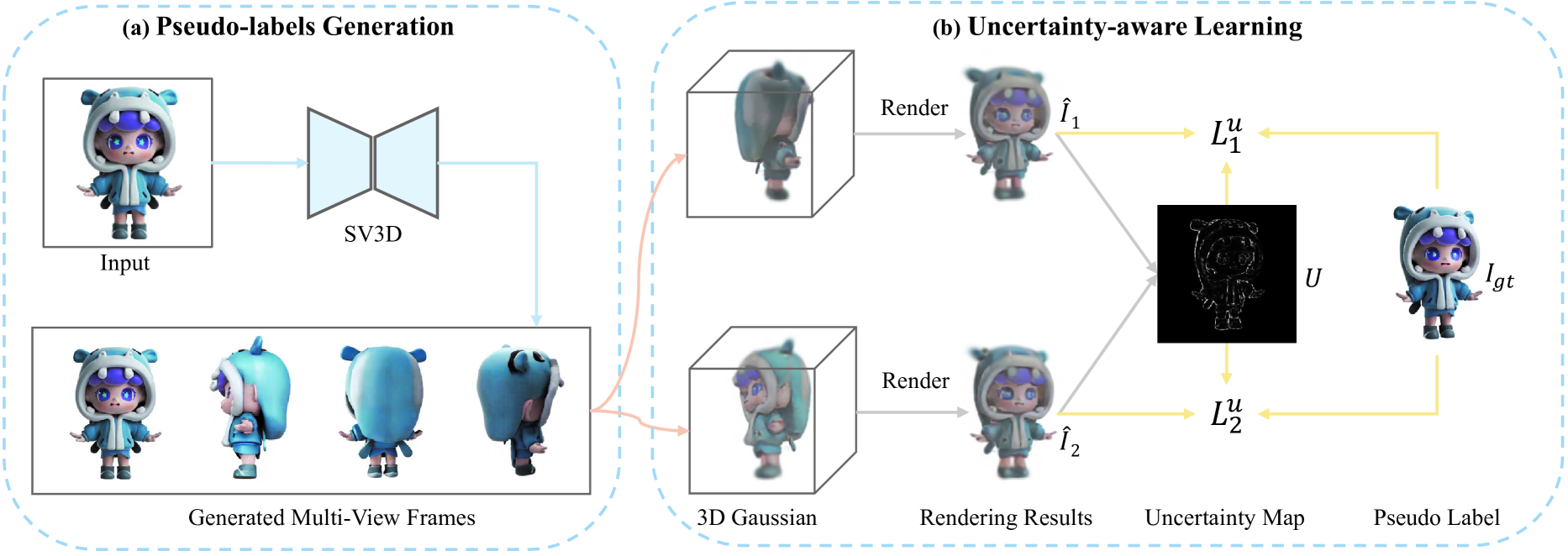
技术框架:整体框架包含两个主要部分:多视角图像生成和3D高斯溅射(3DGS)重建。首先,从单张输入图像生成多视角图像。然后,利用3DGS进行3D重建,同时优化两个高斯模型。在优化过程中,计算不同视角下渲染图像之间的差异,得到不确定性图。最后,利用不确定性图对3DGS的损失函数进行加权,降低高不确定性区域的重建强度。
关键创新:最重要的创新点在于将不确定性感知学习引入到图像到3D生成任务中。通过显式地估计多视角图像之间的不确定性,并利用该不确定性进行正则化,能够有效地减少不一致性带来的影响,从而提升3D重建质量。与现有方法相比,该方法能够动态地检测和减轻多视角标签中的冲突。
关键设计:关键设计包括:1) 使用3DGS作为3D重建方法,因为它具有高效和高质量的特点;2) 通过计算不同视角下渲染图像之间的差异来估计不确定性图;3) 使用自适应像素级损失权重,根据不确定性图对3DGS的损失函数进行加权。具体来说,损失函数被设计为:L = Σ w_i * L_i,其中w_i是根据不确定性图计算得到的像素级权重,L_i是3DGS的原始损失函数。
🖼️ 关键图片

📊 实验亮点
论文通过大量实验验证了所提出方法的有效性。实验结果表明,该方法能够显著减少3D重建中的不一致性和伪影,提升3D生成质量。相较于现有方法,该方法在多个指标上取得了显著提升,例如在PSNR、SSIM等指标上均有明显改善。实验结果还表明,该方法能够有效地处理具有挑战性的场景,例如具有复杂几何形状和纹理的物体。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、机器人导航等领域。通过单张图像快速生成高质量的3D模型,可以降低3D内容制作的成本和门槛,加速相关应用的发展。未来,该技术有望应用于自动驾驶、三维地图构建等更广泛的领域。
📄 摘要(原文)
Given a single image of a target object, image-to-3D generation aims to reconstruct its texture and geometric shape. Recent methods often utilize intermediate media, such as multi-view images or videos, to bridge the gap between input image and the 3D target, thereby guiding the generation of both shape and texture. However, inconsistencies in the generated multi-view snapshots frequently introduce noise and artifacts along object boundaries, undermining the 3D reconstruction process. To address this challenge, we leverage 3D Gaussian Splatting (3DGS) for 3D reconstruction, and explicitly integrate uncertainty-aware learning into the reconstruction process. By capturing the stochasticity between two Gaussian models, we estimate an uncertainty map, which is subsequently used for uncertainty-aware regularization to rectify the impact of inconsistencies. Specifically, we optimize both Gaussian models simultaneously, calculating the uncertainty map by evaluating the discrepancies between rendered images from identical viewpoints. Based on the uncertainty map, we apply adaptive pixel-wise loss weighting to regularize the models, reducing reconstruction intensity in high-uncertainty regions. This approach dynamically detects and mitigates conflicts in multi-view labels, leading to smoother results and effectively reducing artifacts. Extensive experiments show the effectiveness of our method in improving 3D generation quality by reducing inconsistencies and artifacts.