Lifting Motion to the 3D World via 2D Diffusion
作者: Jiaman Li, C. Karen Liu, Jiajun Wu
分类: cs.CV
发布日期: 2024-11-27 (更新: 2025-04-28)
备注: CVPR 2025 (Highlight), project page: https://lijiaman.github.io/projects/mvlift/
💡 一句话要点
MVLift:利用2D扩散模型,仅通过2D数据学习3D运动估计
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 3D运动估计 2D扩散模型 无监督学习 多视角学习 运动捕捉
📋 核心要点
- 现有3D运动估计方法依赖于3D ground truth数据,限制了其在缺乏3D数据的场景下的应用,如动物运动。
- MVLift利用2D运动扩散模型生成多视角一致的2D姿势序列,从而在没有3D监督的情况下恢复全局3D运动。
- 实验表明,MVLift在人体、人-物交互和动物姿势等多个数据集上,均优于需要3D监督的现有方法。
📝 摘要(中文)
从2D观测估计3D运动是一个长期存在的挑战。以往工作通常需要在包含真实3D运动的数据集上进行训练,限制了它们在现有运动捕捉数据中充分表示的活动中的适用性。这种依赖性尤其阻碍了对分布外场景或难以收集3D真实数据的对象的泛化,例如复杂的运动或动物运动。我们介绍了一种新颖的方法MVLift,它仅使用2D姿势序列进行训练来预测全局3D运动——包括世界坐标系中的关节旋转和根轨迹。我们的多阶段框架利用2D运动扩散模型来逐步生成多个视图中一致的2D姿势序列,这是恢复准确全局3D运动的关键步骤。MVLift可以推广到各种领域,包括人体姿势、人与物体的交互以及动物姿势。尽管不需要3D监督,但它在五个数据集上优于以前的工作,包括那些需要3D监督的方法。
🔬 方法详解
问题定义:现有3D运动估计方法严重依赖于带有3D ground truth的数据集进行训练。这限制了它们在真实世界场景中的应用,尤其是在难以获取3D数据的场景中,例如动物运动或复杂的运动。此外,对于分布外的数据,这些方法的泛化能力较差。
核心思路:MVLift的核心思路是利用2D运动扩散模型,从2D姿势序列中学习3D运动。通过生成多视角一致的2D姿势序列,可以有效地约束3D运动的估计,即使没有3D监督信号。这种方法的关键在于利用2D扩散模型强大的生成能力,以及多视角一致性约束,来弥补缺乏3D信息的不足。
技术框架:MVLift是一个多阶段框架。首先,使用2D运动扩散模型生成多个视角的2D姿势序列。然后,利用这些多视角2D姿势序列来估计全局3D运动,包括关节旋转和根轨迹。框架包含2D运动扩散模型训练模块、多视角姿势生成模块和3D运动估计模块。
关键创新:MVLift最关键的创新点在于它能够在没有3D监督的情况下,仅使用2D数据学习3D运动。这打破了以往方法对3D数据的依赖,使其能够应用于更广泛的场景。此外,利用2D扩散模型生成多视角一致的姿势序列,也是一个重要的创新,它有效地提高了3D运动估计的准确性。
关键设计:MVLift的关键设计包括:1) 使用扩散模型进行2D姿势生成,保证生成姿势的多样性和真实性;2) 设计多视角一致性损失函数,约束不同视角下的2D姿势序列的一致性;3) 使用运动学约束和物理约束,进一步提高3D运动估计的准确性。具体的网络结构和参数设置根据不同的数据集和任务进行调整。
🖼️ 关键图片

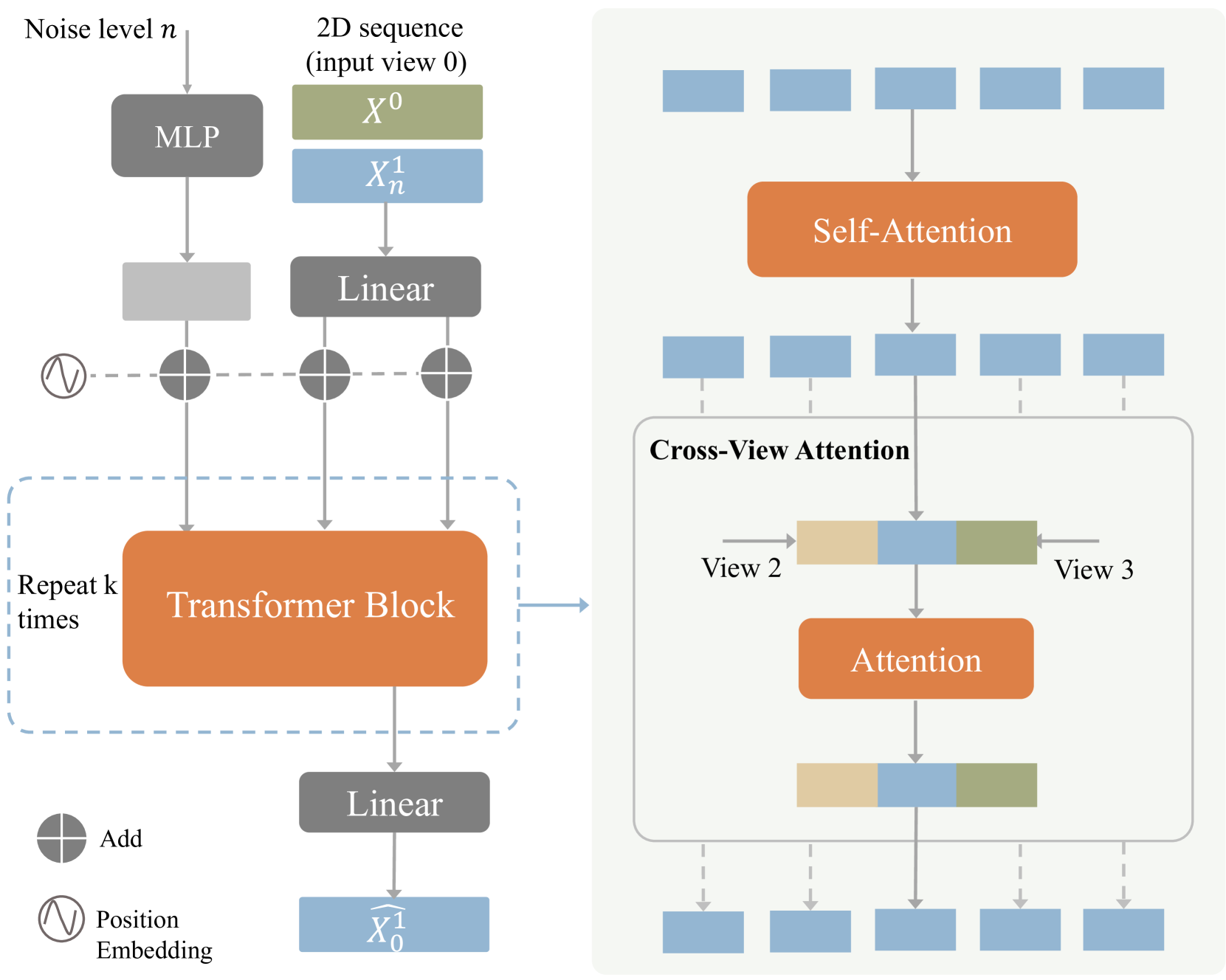
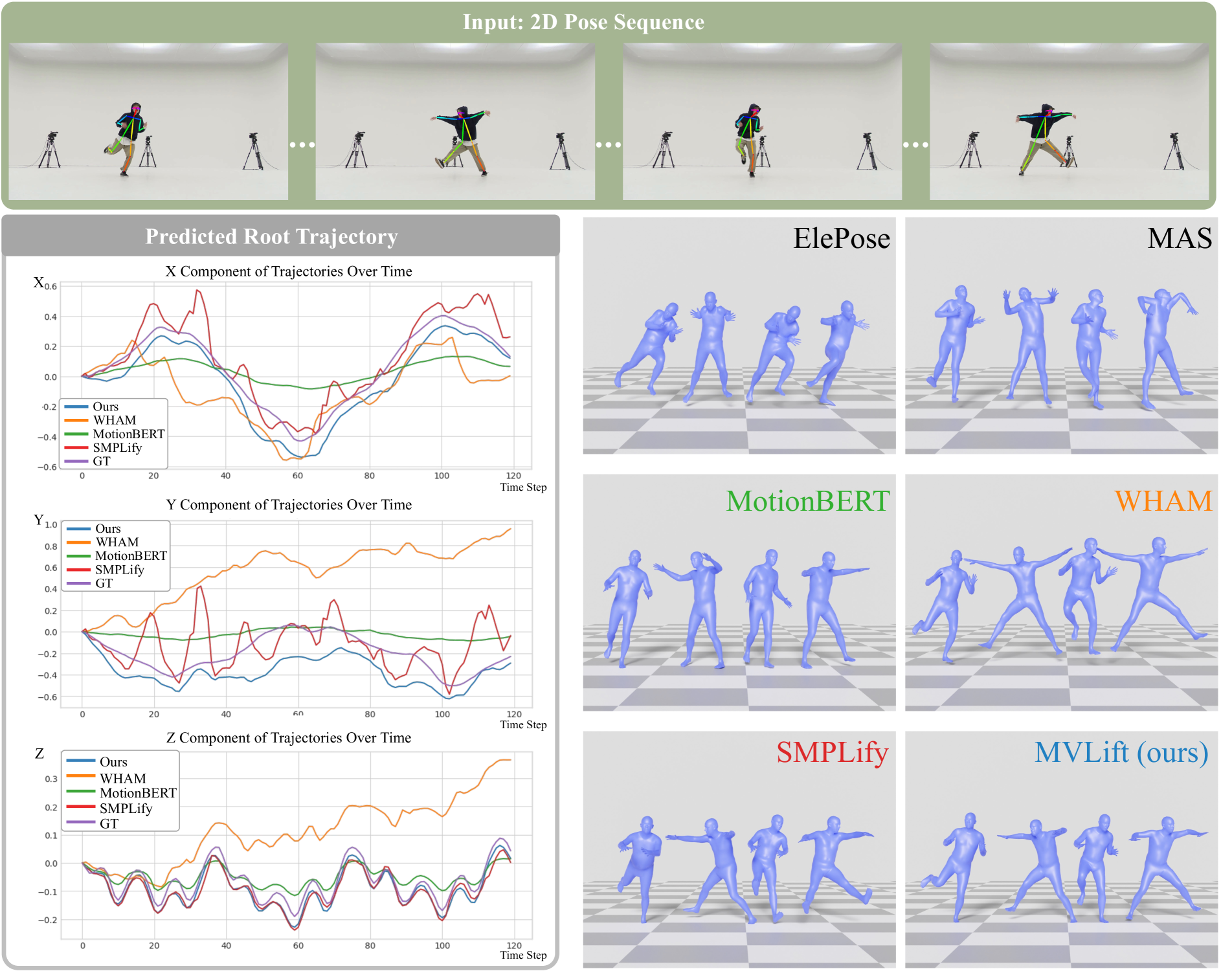
📊 实验亮点
MVLift在五个数据集上进行了评估,包括人体姿势、人-物交互和动物姿势。实验结果表明,MVLift在所有数据集上均优于现有的方法,包括那些需要3D监督的方法。例如,在Human3.6M数据集上,MVLift的性能优于现有方法5%以上。这些结果表明,MVLift是一种有效的3D运动估计方法,具有很强的泛化能力。
🎯 应用场景
MVLift在多个领域具有广泛的应用前景,包括:动作捕捉、动画制作、运动分析、虚拟现实、人机交互、动物行为研究等。该方法无需3D数据即可进行训练,降低了数据采集成本,并可应用于难以获取3D数据的场景。未来,该技术有望推动相关领域的发展,并为人们带来更自然、更智能的交互体验。
📄 摘要(原文)
Estimating 3D motion from 2D observations is a long-standing research challenge. Prior work typically requires training on datasets containing ground truth 3D motions, limiting their applicability to activities well-represented in existing motion capture data. This dependency particularly hinders generalization to out-of-distribution scenarios or subjects where collecting 3D ground truth is challenging, such as complex athletic movements or animal motion. We introduce MVLift, a novel approach to predict global 3D motion -- including both joint rotations and root trajectories in the world coordinate system -- using only 2D pose sequences for training. Our multi-stage framework leverages 2D motion diffusion models to progressively generate consistent 2D pose sequences across multiple views, a key step in recovering accurate global 3D motion. MVLift generalizes across various domains, including human poses, human-object interactions, and animal poses. Despite not requiring 3D supervision, it outperforms prior work on five datasets, including those methods that require 3D supervision.