CoVis: A Collaborative Framework for Fine-grained Graphic Visual Understanding
作者: Xiaoyu Deng, Zhengjian Kang, Xintao Li, Yongzhe Zhang, Tianmin Guo
分类: cs.CV, cs.AI
发布日期: 2024-11-27
💡 一句话要点
CoVis:用于细粒度图形视觉理解的协同框架,提升信息获取质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图形视觉理解 协同框架 细粒度分割 大型语言模型 视觉分析 特征提取 信息获取
📋 核心要点
- 现有视觉内容理解主要依赖个人知识背景,导致信息获取质量和效率受限,易形成信息茧房。
- CoVis框架通过级联双层分割网络和LLM内容生成器,从图像中提取更多知识,生成视觉分析。
- 实验表明,CoVis在特征提取方面优于现有方法,能生成更全面、详细的视觉描述。
📝 摘要(中文)
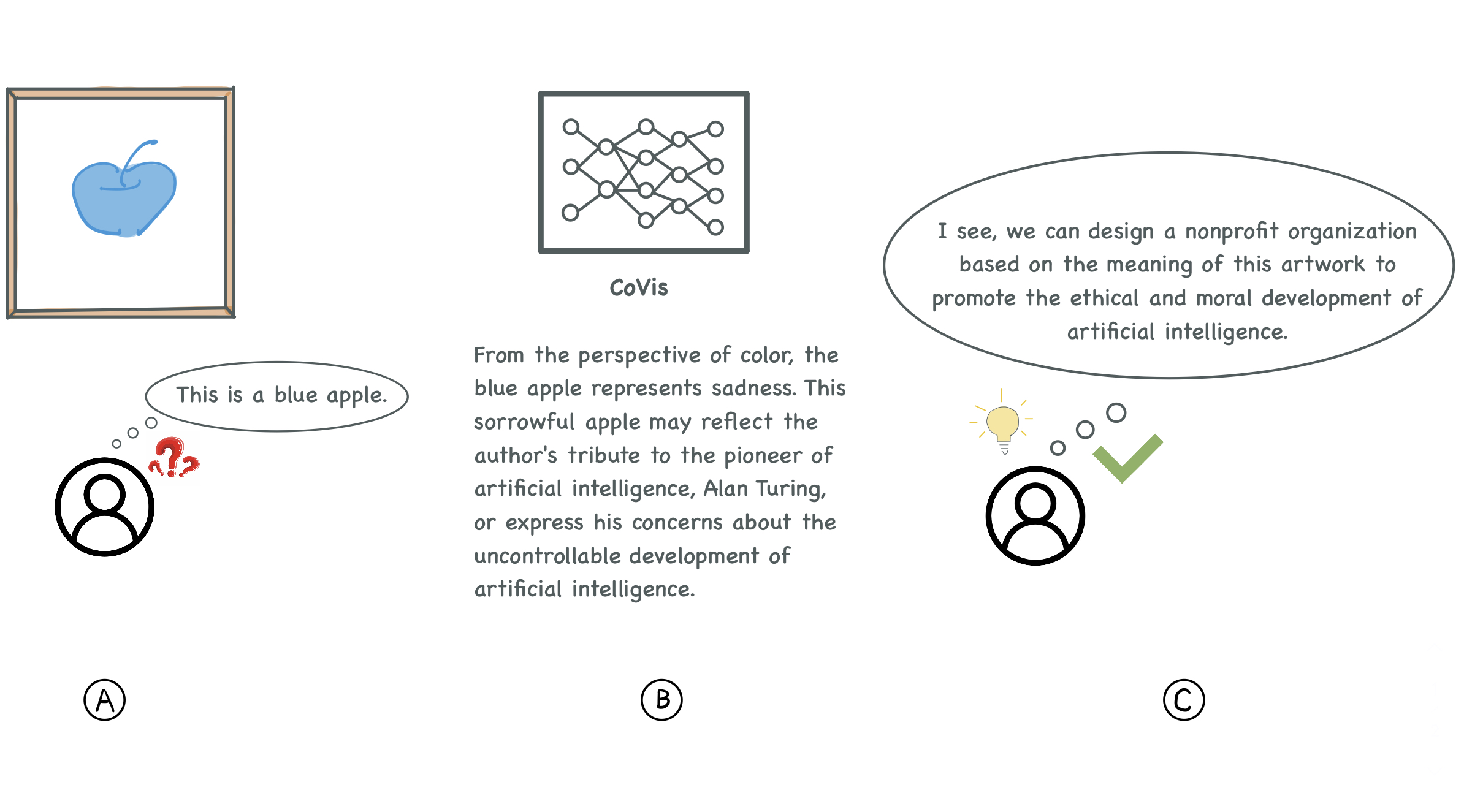
图形视觉内容有助于促进信息交流和激发灵感。然而,目前对视觉内容的解读主要依赖于人类的个人知识背景,从而影响信息获取和理解的质量和效率。为了提高视觉信息传输的质量和效率,并避免观察者因信息茧房而受限,我们提出了CoVis,一个用于细粒度视觉理解的协同框架。通过设计和实现一个级联双层分割网络,并结合基于大型语言模型(LLM)的内容生成器,该框架尽可能多地从图像中提取知识。然后,它为图像生成视觉分析,帮助观察者从更全面的角度理解图像。基于32名人类参与者的定量实验和定性实验表明,CoVis在特征提取方面比当前方法具有更好的性能,并且可以生成比当前通用大型模型更全面和详细的视觉描述。
🔬 方法详解
问题定义:论文旨在解决图形视觉内容理解中,由于依赖个人知识背景而导致的信息获取质量和效率低下的问题。现有方法难以充分挖掘图像中的信息,且容易受到观察者自身知识结构的限制,导致理解偏差。
核心思路:CoVis的核心思路是通过协同的方式,利用计算机视觉技术和自然语言处理技术,从图像中提取尽可能多的知识,并生成全面的视觉分析,从而帮助观察者更客观、更深入地理解图像。这种协同体现在两个方面:一是级联分割网络与LLM的协同,二是机器生成分析与人类观察的协同。
技术框架:CoVis框架主要包含两个阶段:1) 特征提取阶段:采用级联双层分割网络,对图像进行细粒度的分割,提取图像中的各种视觉元素和关系。2) 内容生成阶段:利用大型语言模型(LLM),根据提取的视觉特征,生成图像的视觉分析,包括图像的描述、关键信息、潜在含义等。框架的整体流程是:输入图像 -> 级联分割网络 -> 视觉特征 -> LLM -> 视觉分析。
关键创新:CoVis的关键创新在于:1) 提出了级联双层分割网络,能够更精细地分割图像,提取更丰富的视觉特征。2) 将大型语言模型(LLM)引入到视觉理解中,利用LLM的强大生成能力,生成更全面、更自然的视觉分析。3) 提出了一个协同框架,将计算机视觉和自然语言处理技术相结合,实现了更高效、更客观的视觉理解。
关键设计:级联双层分割网络的设计细节未知,但可以推测其可能包含两个层级的分割:第一层级可能进行粗粒度的语义分割,将图像分割成不同的对象区域;第二层级可能在每个对象区域内进行细粒度的分割,提取更精细的视觉元素。LLM的选择和训练策略未知,但可以推测其需要针对视觉分析任务进行微调,以提高生成视觉描述的准确性和流畅性。损失函数和参数设置等细节信息在摘要中未提及。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoVis在特征提取方面优于现有方法,能够生成比当前通用大型模型更全面和详细的视觉描述。具体的性能数据和对比基线在摘要中未给出,但通过32名人类参与者的定性和定量实验验证了CoVis的有效性。CoVis能够更好地辅助人类理解图形视觉内容。
🎯 应用场景
CoVis可应用于多个领域,例如:教育领域,辅助学生理解复杂的图表和图像;新闻领域,自动生成新闻图片的描述和分析;医疗领域,辅助医生诊断医学影像;工业领域,辅助工程师分析设计图纸。该研究有助于提高信息传播效率,促进知识共享,并为未来的视觉理解系统提供新的思路。
📄 摘要(原文)
Graphic visual content helps in promoting information communication and inspiration divergence. However, the interpretation of visual content currently relies mainly on humans' personal knowledge background, thereby affecting the quality and efficiency of information acquisition and understanding. To improve the quality and efficiency of visual information transmission and avoid the limitation of the observer due to the information cocoon, we propose CoVis, a collaborative framework for fine-grained visual understanding. By designing and implementing a cascaded dual-layer segmentation network coupled with a large-language-model (LLM) based content generator, the framework extracts as much knowledge as possible from an image. Then, it generates visual analytics for images, assisting observers in comprehending imagery from a more holistic perspective. Quantitative experiments and qualitative experiments based on 32 human participants indicate that the CoVis has better performance than current methods in feature extraction and can generate more comprehensive and detailed visual descriptions than current general-purpose large models.