GaussianSpeech: Audio-Driven Gaussian Avatars
作者: Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner
分类: cs.CV, cs.AI, cs.GR, cs.SD, eess.AS
发布日期: 2024-11-27
备注: Paper Video: https://youtu.be/2VqYoFlYcwQ Project Page: https://shivangi-aneja.github.io/projects/gaussianspeech
💡 一句话要点
GaussianSpeech:提出基于3D高斯溅射的音频驱动高逼真度人头化身
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 音频驱动 人头化身 3D高斯溅射 语音合成 面部动画
📋 核心要点
- 现有方法难以捕捉人头部的精细表情和皮肤细节,尤其是在音频驱动的动画中,缺乏高保真度的模型。
- GaussianSpeech 结合语音信号与 3D 高斯溅射,利用音频条件 Transformer 模型直接从音频中提取特征,驱动高斯溅射的形变和颜色变化。
- 通过新的大规模多视角数据集训练,GaussianSpeech 在生成逼真、实时的音频驱动人头动画方面达到了最先进的水平。
📝 摘要(中文)
GaussianSpeech 提出了一种新颖的方法,用于从语音合成逼真、个性化的 3D 人头化身的高保真动画序列。为了捕捉人头部的富有表现力和细节的特征,包括皮肤纹路和更精细的面部运动,我们将语音信号与 3D 高斯溅射相结合,以创建逼真的、时间上连贯的运动序列。我们提出了一种紧凑而高效的基于 3DGS 的化身表示,该表示生成依赖于表情的颜色,并利用基于皱纹和感知的损失来合成面部细节,包括不同表情下出现的皱纹。为了实现音频驱动的 3D 高斯溅射序列建模,我们设计了一个音频条件 Transformer 模型,能够直接从音频输入中提取嘴唇和表情特征。由于缺乏与音频对应的高质量说话人数据集,我们捕获了一个新的大规模多视角数据集,其中包含具有母语英语口音和多样面部几何形状的说话人的视听序列。GaussianSpeech 始终以实时渲染速率实现最先进的性能和视觉上自然的运动,同时包含多样化的面部表情和风格。
🔬 方法详解
问题定义:现有音频驱动人头动画方法难以生成高保真、个性化的 3D 化身,尤其是在捕捉细微的面部表情(如皱纹)和保持时间连贯性方面存在挑战。缺乏高质量的、包含多样化面部几何和口音的视听数据集也限制了相关研究的进展。
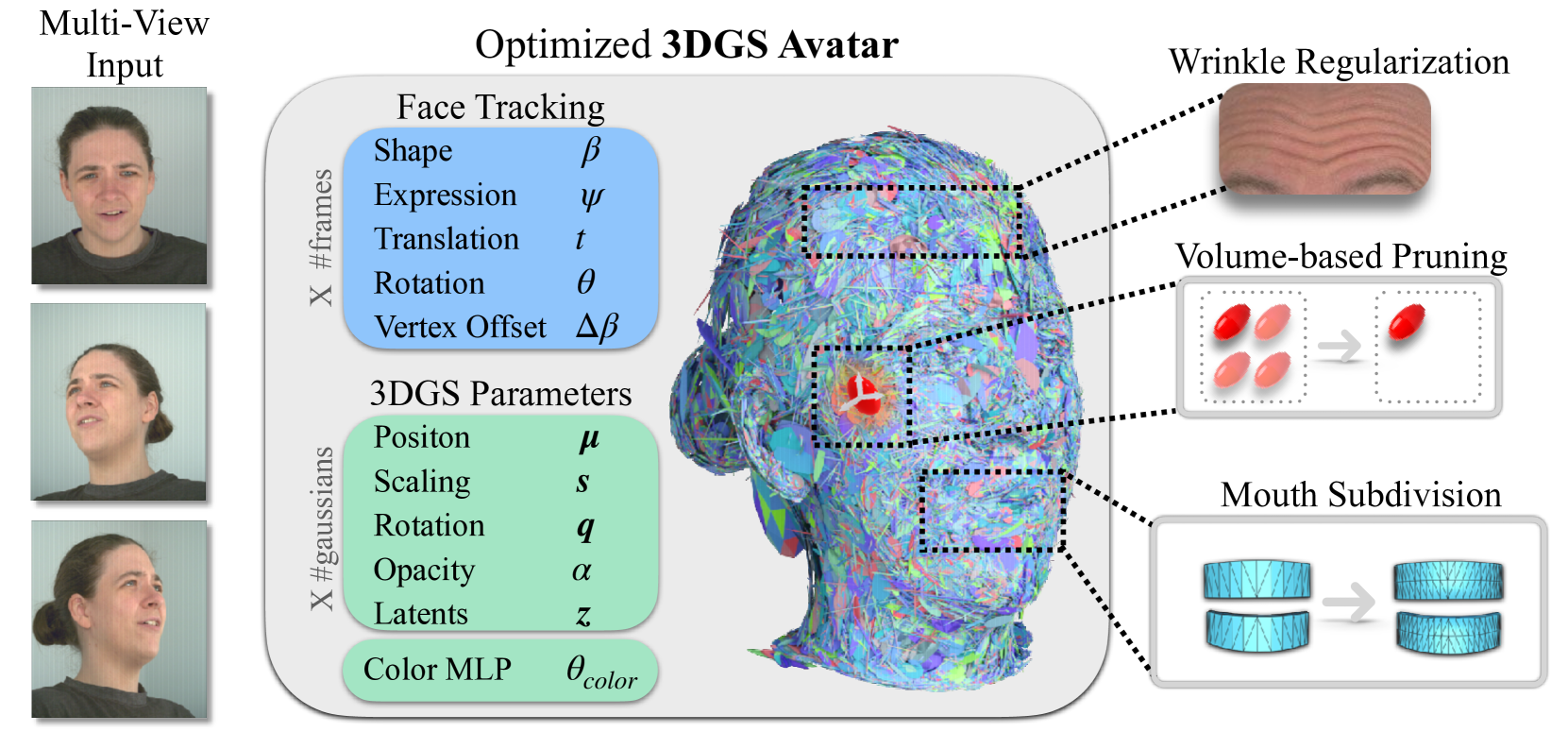
核心思路:GaussianSpeech 的核心思路是将 3D 高斯溅射(3DGS)作为人头化身的表示,并利用音频信息驱动 3DGS 的参数变化,从而实现逼真的面部动画。3DGS 能够高效地渲染和表示复杂的几何细节,而音频信息则提供了表情和口型的驱动信号。
技术框架:GaussianSpeech 的整体框架包含以下几个主要模块:1) 3DGS 化身表示:使用 3DGS 表示人头部的几何形状和外观。每个高斯球都包含位置、缩放、旋转和颜色等参数。2) 音频特征提取:使用音频条件 Transformer 模型从输入的音频信号中提取嘴唇和表情相关的特征。3) 3DGS 参数预测:将提取的音频特征输入到网络中,预测每个高斯球的颜色和位置偏移量,从而实现表情驱动的形变。4) 渲染:使用高效的 3DGS 渲染器将形变后的高斯球渲染成最终的图像。
关键创新:GaussianSpeech 的关键创新在于:1) 基于 3DGS 的化身表示:相比于传统的网格或体素表示,3DGS 能够更高效地表示和渲染复杂的几何细节。2) 音频条件 Transformer 模型:该模型能够有效地从音频中提取与面部表情相关的特征,并驱动 3DGS 的形变。3) 皱纹和感知损失:引入了基于皱纹和感知的损失函数,以提高生成面部细节的真实感。
关键设计:GaussianSpeech 的关键设计包括:1) 音频条件 Transformer 模型的结构:具体网络结构未知,但其作用是从音频中提取特征。2) 损失函数的设计:除了传统的图像重建损失外,还使用了基于皱纹和感知的损失函数,以鼓励生成更逼真的面部细节。3) 数据集的构建:收集了一个大规模多视角数据集,包含具有多样化面部几何和口音的说话人,用于训练模型。
🖼️ 关键图片


📊 实验亮点
GaussianSpeech 在音频驱动人头动画任务上取得了最先进的性能。该方法能够生成具有丰富面部表情和细节的逼真动画,并且能够以实时渲染速率运行。论文中提到,该方法在视觉自然度和运动流畅度方面均优于现有方法,但具体的性能数据和对比基线未知。
🎯 应用场景
GaussianSpeech 有着广泛的应用前景,包括虚拟会议、游戏、虚拟现实/增强现实、个性化教育和数字内容创作等领域。它可以用于创建逼真的虚拟化身,从而增强用户在虚拟环境中的沉浸感和交互体验。此外,该技术还可以用于开发更自然和人性化的语音助手和聊天机器人。
📄 摘要(原文)
We introduce GaussianSpeech, a novel approach that synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. To capture the expressive, detailed nature of human heads, including skin furrowing and finer-scale facial movements, we propose to couple speech signal with 3D Gaussian splatting to create realistic, temporally coherent motion sequences. We propose a compact and efficient 3DGS-based avatar representation that generates expression-dependent color and leverages wrinkle- and perceptually-based losses to synthesize facial details, including wrinkles that occur with different expressions. To enable sequence modeling of 3D Gaussian splats with audio, we devise an audio-conditioned transformer model capable of extracting lip and expression features directly from audio input. Due to the absence of high-quality datasets of talking humans in correspondence with audio, we captured a new large-scale multi-view dataset of audio-visual sequences of talking humans with native English accents and diverse facial geometry. GaussianSpeech consistently achieves state-of-the-art performance with visually natural motion at real time rendering rates, while encompassing diverse facial expressions and styles.