DHCP: Detecting Hallucinations by Cross-modal Attention Pattern in Large Vision-Language Models
作者: Yudong Zhang, Ruobing Xie, Xingwu Sun, Yiqing Huang, Jiansheng Chen, Zhanhui Kang, Di Wang, Yu Wang
分类: cs.CV, cs.AI
发布日期: 2024-11-27 (更新: 2025-07-31)
备注: Accepted by ACM Multimedia 2025
🔗 代码/项目: GITHUB
💡 一句话要点
DHCP:通过跨模态注意力模式检测大型视觉-语言模型中的幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 幻觉检测 跨模态注意力 可信AI 多模态学习
📋 核心要点
- 大型视觉-语言模型存在对象、属性和关系幻觉等问题,降低了模型的可靠性和可信度。
- DHCP通过分析幻觉和非幻觉状态下跨模态注意力模式的差异,实现幻觉检测,无需额外训练或推理。
- 实验结果表明,DHCP在幻觉检测方面表现出色,为提升LVLMs的可靠性提供了新的思路。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)在复杂的多模态任务中表现出了卓越的性能。然而,它们仍然存在显著的幻觉问题,包括对象、属性和关系幻觉。为了准确地检测这些幻觉,我们研究了幻觉和非幻觉状态之间跨模态注意力模式的变化。利用这些区别,我们开发了一种轻量级的检测器,能够识别幻觉。我们提出的方法,即通过跨模态注意力模式检测幻觉(DHCP),简单直接,不需要额外的LVLM训练或额外的LVLM推理步骤。实验结果表明,DHCP在幻觉检测方面取得了显著的性能。通过为LVLMs中幻觉的识别和分析提供新的见解,DHCP有助于提高这些模型的可靠性和可信度。代码可在https://github.com/btzyd/DHCP获取。
🔬 方法详解
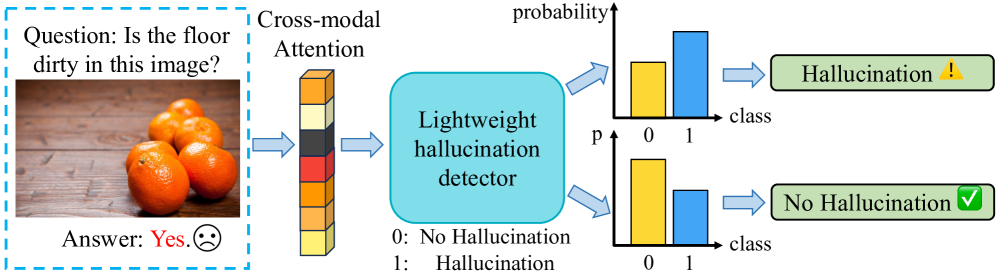
问题定义:大型视觉-语言模型(LVLMs)在多模态任务中表现出色,但容易产生幻觉,即生成与图像内容不符的信息,包括错误的对象、属性或关系。现有方法通常需要额外的训练或推理步骤,计算成本高昂,且可能影响模型的原始性能。因此,如何高效、准确地检测LVLMs中的幻觉是一个关键问题。
核心思路:DHCP的核心思路是,LVLMs在生成幻觉时,其跨模态注意力模式会发生变化。具体来说,模型在生成幻觉时,图像和文本之间的注意力分布会偏离正常状态。通过分析这种注意力模式的差异,可以判断模型是否产生了幻觉。这种方法无需额外的训练或推理,具有轻量级的特点。
技术框架:DHCP主要包含以下几个步骤:1) 输入图像和文本描述到LVLM中;2) 提取LVLM中跨模态注意力层的注意力权重;3) 计算注意力模式的统计特征,例如注意力权重的均值、方差等;4) 使用一个轻量级的分类器(例如线性分类器或支持向量机)对注意力模式的统计特征进行分类,判断是否存在幻觉。
关键创新:DHCP的关键创新在于利用跨模态注意力模式的变化来检测幻觉。与现有方法相比,DHCP不需要额外的LVLM训练或额外的LVLM推理步骤,因此更加高效和轻量级。此外,DHCP通过分析注意力模式,可以提供关于幻觉产生原因的 insights。
关键设计:DHCP的关键设计包括:1) 选择合适的跨模态注意力层进行分析;2) 设计有效的注意力模式统计特征;3) 选择合适的分类器进行幻觉检测。具体来说,可以选择LVLM中多个跨模态注意力层的输出,并计算每个注意力头的注意力权重。然后,可以计算注意力权重的均值、方差、熵等统计特征。最后,可以使用一个线性分类器或支持向量机对这些特征进行分类,判断是否存在幻觉。
🖼️ 关键图片
📊 实验亮点
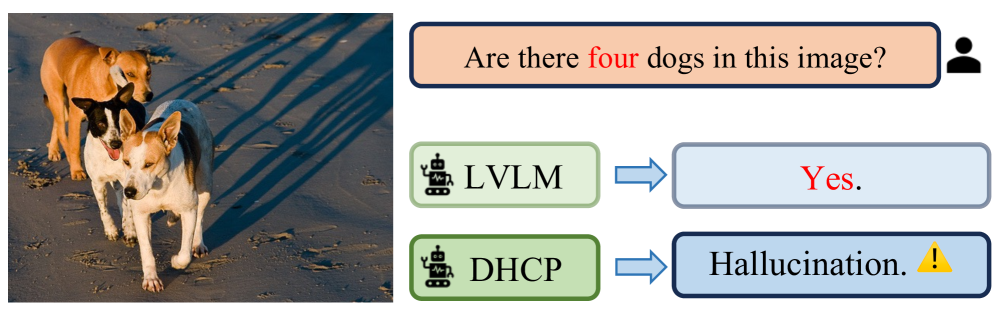
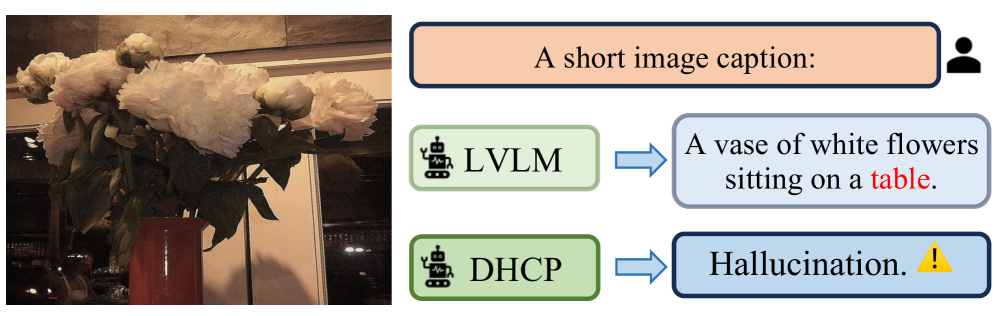
DHCP在幻觉检测方面取得了显著的性能,无需额外的LVLM训练或推理步骤。实验结果表明,DHCP能够有效地检测对象、属性和关系幻觉,并且在多个数据集上优于现有的幻觉检测方法。具体的性能数据和对比基线可以在论文中找到。
🎯 应用场景
DHCP可应用于各种需要可靠视觉-语言交互的场景,例如自动驾驶、医疗诊断、智能客服等。通过检测和纠正LVLMs中的幻觉,可以提高这些应用的安全性和可靠性。此外,DHCP还可以用于评估和改进LVLMs的性能,促进视觉-语言模型的发展。
📄 摘要(原文)
Large vision-language models (LVLMs) have demonstrated exceptional performance on complex multimodal tasks. However, they continue to suffer from significant hallucination issues, including object, attribute, and relational hallucinations. To accurately detect these hallucinations, we investigated the variations in cross-modal attention patterns between hallucination and non-hallucination states. Leveraging these distinctions, we developed a lightweight detector capable of identifying hallucinations. Our proposed method, Detecting Hallucinations by Cross-modal Attention Patterns (DHCP), is straightforward and does not require additional LVLM training or extra LVLM inference steps. Experimental results show that DHCP achieves remarkable performance in hallucination detection. By offering novel insights into the identification and analysis of hallucinations in LVLMs, DHCP contributes to advancing the reliability and trustworthiness of these models. The code is available at https://github.com/btzyd/DHCP.