Verbalized Representation Learning for Interpretable Few-Shot Generalization
作者: Cheng-Fu Yang, Da Yin, Wenbo Hu, Heng Ji, Nanyun Peng, Bolei Zhou, Kai-Wei Chang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-11-27 (更新: 2025-08-06)
备注: Accepted to ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出VRL:利用自然语言特征提升小样本泛化能力和可解释性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 小样本学习 视觉-语言模型 可解释性 自然语言特征 目标识别
📋 核心要点
- 现有方法在小样本学习中泛化能力不足,缺乏对现实世界环境的语言理解能力。
- VRL方法利用视觉-语言模型提取可解释的自然语言特征,从而区分不同类别并捕捉同一类别的共性。
- 实验表明,VRL在小样本学习中显著优于现有方法,并超越了人工标注特征的性能。
📝 摘要(中文)
本文提出了一种名为Verbalized Representation Learning (VRL) 的新方法,旨在利用少量样本数据自动提取人类可解释的特征,从而提升目标识别的泛化能力。VRL方法通过视觉-语言模型 (VLM) 识别不同类别之间的关键判别特征以及同一类别内的共享特征,以自然语言的形式捕获类间差异和类内共性。这些口头化的特征随后通过VLM映射到数值向量,生成的特征向量可用于训练和推理下游分类器。实验结果表明,在相同模型规模下,VRL在数据量减少95%的情况下,性能比现有最佳方法提高了24%。此外,VRL学习到的特征在下游分类任务中比人工标注的属性提高了20%。
🔬 方法详解
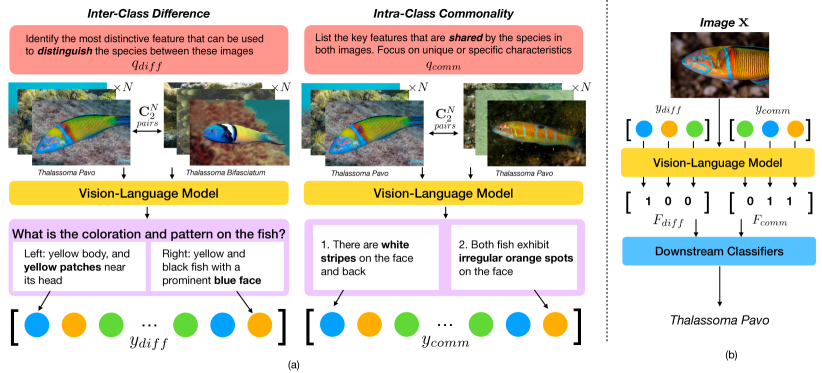
问题定义:论文旨在解决小样本学习中模型泛化能力差的问题。现有方法难以有效利用少量样本数据学习到具有区分性的特征,并且缺乏对学习到的特征的解释性,导致模型在面对新类别时表现不佳。
核心思路:论文的核心思路是利用视觉-语言模型 (VLM) 的强大能力,将图像信息转化为人类可理解的自然语言描述,从而提取具有语义信息的特征。通过学习类间差异和类内共性,VRL能够获得更具判别性和泛化能力的特征表示。
技术框架:VRL方法主要包含以下几个阶段:1) 特征提取:使用预训练的视觉-语言模型(如CLIP)提取图像的视觉特征。2) 语言生成:利用VLM生成描述图像特征的自然语言文本,这些文本旨在区分不同类别并捕捉同一类别的共性。3) 特征映射:将生成的自然语言文本通过VLM映射回数值向量空间,得到可用于下游分类任务的特征表示。4) 分类器训练:使用生成的特征向量训练下游分类器,进行目标识别。
关键创新:VRL的关键创新在于利用VLM自动提取人类可解释的自然语言特征,从而将视觉信息与语言信息相结合,提升了小样本学习的泛化能力和可解释性。与传统方法相比,VRL无需人工标注属性,并且能够学习到更具判别性的特征。
关键设计:VRL的关键设计包括:1) 使用预训练的VLM作为特征提取器和语言生成器,充分利用了VLM的强大能力。2) 设计合适的prompt,引导VLM生成描述类间差异和类内共性的自然语言文本。3) 使用对比学习等技术,优化VLM的训练过程,提升特征表示的质量。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
VRL在小样本学习任务中取得了显著的性能提升。实验结果表明,在相同模型规模下,VRL比现有最佳方法提高了24%,同时使用的数据量减少了95%。此外,VRL学习到的特征在下游分类任务中比人工标注的属性提高了20%,证明了VRL的有效性和优越性。
🎯 应用场景
VRL方法可应用于各种小样本学习场景,例如:新产品识别、罕见疾病诊断、图像检索等。该方法通过提取可解释的特征,有助于提高模型的透明度和可信度,并为用户提供更直观的决策依据。未来,VRL有望在医疗、金融、安防等领域发挥重要作用。
📄 摘要(原文)
Humans recognize objects after observing only a few examples, a remarkable capability enabled by their inherent language understanding of the real-world environment. Developing verbalized and interpretable representation can significantly improve model generalization in low-data settings. In this work, we propose Verbalized Representation Learning (VRL), a novel approach for automatically extracting human-interpretable features for object recognition using few-shot data. Our method uniquely captures inter-class differences and intra-class commonalities in the form of natural language by employing a Vision-Language Model (VLM) to identify key discriminative features between different classes and shared characteristics within the same class. These verbalized features are then mapped to numeric vectors through the VLM. The resulting feature vectors can be further utilized to train and infer with downstream classifiers. Experimental results show that, at the same model scale, VRL achieves a 24% absolute improvement over prior state-of-the-art methods while using 95% less data and a smaller mode. Furthermore, compared to human-labeled attributes, the features learned by VRL exhibit a 20% absolute gain when used for downstream classification tasks. Code is available at: https://github.com/joeyy5588/VRL/tree/main.