OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
作者: Pengfei Zhou, Xiaopeng Peng, Jiajun Song, Chuanhao Li, Zhaopan Xu, Yue Yang, Ziyao Guo, Hao Zhang, Yuqi Lin, Yefei He, Lirui Zhao, Shuo Liu, Tianhua Li, Yuxuan Xie, Xiaojun Chang, Yu Qiao, Wenqi Shao, Kaipeng Zhang
分类: cs.CV
发布日期: 2024-11-27 (更新: 2025-03-30)
备注: 53 pages, 19 figures, accepted by CVPR 2025
💡 一句话要点
提出OpenING基准测试集,用于评估开放式交错图像-文本生成模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图像文本生成 基准测试 大型语言模型 开放式生成
📋 核心要点
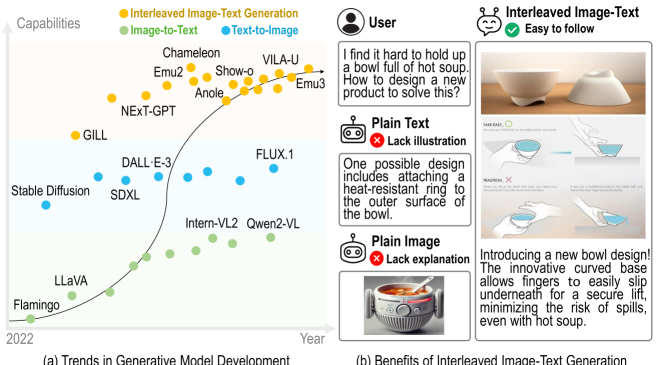
- 现有基准测试集在数据规模和多样性上存在局限性,无法充分评估多模态大型语言模型在交错图像-文本生成方面的能力。
- 提出OpenING基准测试集,包含5400个高质量人工标注实例,覆盖56个真实世界任务,旨在提供更全面的评估平台。
- 设计IntJudge评判模型,通过新数据管道训练,与人类判断的协议率达82.42%,优于GPT评估器,提升了评估的准确性。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉理解和生成任务中取得了显著进展。然而,生成交错的图像-文本内容仍然是一个挑战,这需要综合的多模态理解和生成能力。虽然统一模型的进步提供了新的解决方案,但由于数据规模和多样性的限制,现有的基准不足以评估这些方法。为了弥补这一差距,我们引入了OpenING,这是一个全面的基准,包含5400个高质量的人工标注实例,涵盖56个真实世界的任务。OpenING涵盖了多样化的日常场景,如旅游指南、设计和头脑风暴,为挑战交错生成方法提供了一个强大的平台。此外,我们提出了IntJudge,一个用于评估开放式多模态生成方法的评判模型。通过一种新的数据管道训练,我们的IntJudge与人类判断的协议率达到了82.42%,比基于GPT的评估器高出11.34%。在OpenING上进行的大量实验表明,当前的交错生成方法仍有很大的改进空间。进一步提出了关于交错图像-文本生成的关键发现,以指导下一代模型的发展。
🔬 方法详解
问题定义:现有方法在评估多模态大型语言模型(MLLMs)生成交错图像-文本内容的能力时,面临数据规模小、任务类型单一的挑战。这使得我们难以准确评估模型在复杂、开放场景下的多模态理解和生成能力。现有基准测试集无法充分反映真实世界的多样性,限制了模型性能的提升。
核心思路:OpenING的核心思路是构建一个大规模、多样化的交错图像-文本生成基准测试集,涵盖各种真实世界的任务和场景。通过提供更具挑战性的评估环境,促进MLLMs在多模态理解和生成方面的进一步发展。同时,设计IntJudge评判模型,以更准确地评估生成内容的质量。
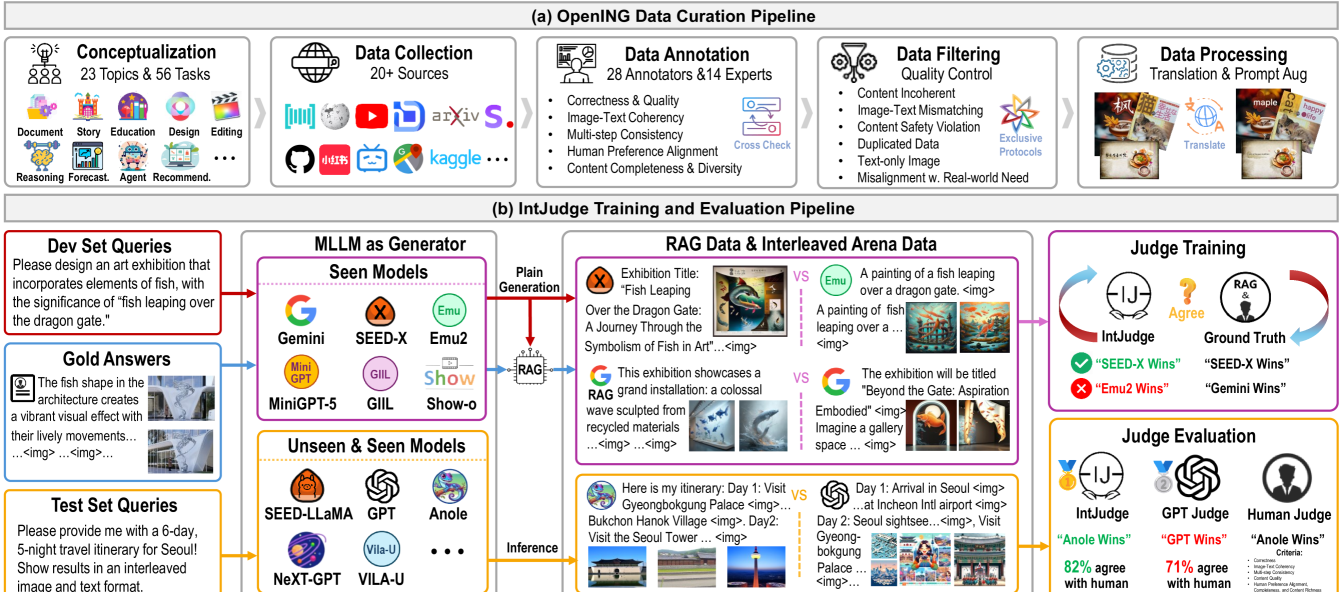
技术框架:OpenING基准测试集包含5400个高质量的人工标注实例,涵盖56个真实世界的任务,如旅游指南、设计和头脑风暴。IntJudge评判模型通过一种新的数据管道进行训练,该管道旨在提高模型与人类判断的一致性。整体流程包括数据收集、数据标注、模型训练和评估。
关键创新:OpenING基准测试集在数据规模和任务多样性方面超越了现有基准。IntJudge评判模型通过专门的数据管道训练,显著提高了评估的准确性,与人类判断的协议率达到了82.42%,优于传统的基于GPT的评估器。
关键设计:OpenING基准测试集中的每个实例都包含一个或多个图像和相应的文本描述,这些描述是人工标注的,以确保高质量。IntJudge评判模型使用Transformer架构,并采用对比学习目标进行训练,以区分高质量和低质量的生成内容。具体参数设置和损失函数细节未知。
🖼️ 关键图片

📊 实验亮点
OpenING基准测试集包含5400个高质量人工标注实例,覆盖56个真实世界任务。IntJudge评判模型与人类判断的协议率达到了82.42%,比基于GPT的评估器高出11.34%。在OpenING上进行的大量实验表明,当前的交错生成方法仍有很大的改进空间。
🎯 应用场景
OpenING基准测试集可用于评估和改进多模态大型语言模型在各种实际应用中的性能,例如智能助手、内容创作、教育和设计等领域。通过提高模型生成交错图像-文本内容的能力,可以提升用户体验,并为用户提供更丰富、更具吸引力的信息。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding and generation tasks. However, generating interleaved image-text content remains a challenge, which requires integrated multimodal understanding and generation abilities. While the progress in unified models offers new solutions, existing benchmarks are insufficient for evaluating these methods due to limitations in data size and diversity. To bridge this gap, we introduce OpenING, a comprehensive benchmark comprising 5,400 high-quality human-annotated instances across 56 real-world tasks. OpenING covers diverse daily scenarios such as travel guide, design, and brainstorming, offering a robust platform for challenging interleaved generation methods. In addition, we present IntJudge, a judge model for evaluating open-ended multimodal generation methods. Trained with a novel data pipeline, our IntJudge achieves an agreement rate of 82.42% with human judgments, outperforming GPT-based evaluators by 11.34%. Extensive experiments on OpenING reveal that current interleaved generation methods still have substantial room for improvement. Key findings on interleaved image-text generation are further presented to guide the development of next-generation models.