ChatRex: Taming Multimodal LLM for Joint Perception and Understanding
作者: Qing Jiang, Gen Luo, Yuqin Yang, Yuda Xiong, Yihao Chen, Zhaoyang Zeng, Tianhe Ren, Lei Zhang
分类: cs.CV
发布日期: 2024-11-27 (更新: 2025-03-11)
备注: 35 pages, 19 figures
🔗 代码/项目: GITHUB
💡 一句话要点
ChatRex:驯服多模态LLM,实现联合感知与理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 目标检测 视觉理解 解耦感知 数据引擎
📋 核心要点
- 现有MLLM在视觉理解方面表现出色,但在精确感知能力上存在不足,限制了感知与理解结合的任务。
- ChatRex通过解耦感知设计,将目标检测的回归任务转化为LLM更擅长的检索任务,提升感知精度。
- 构建Rexverse-2M数据集,并采用三阶段训练方法,ChatRex在感知和理解方面均取得了显著提升。
📝 摘要(中文)
感知和理解是计算机视觉的两大支柱。尽管多模态大型语言模型(MLLM)已经展示了卓越的视觉理解能力,但它们在精确感知方面存在不足。例如,最先进的模型Qwen2-VL在COCO数据集上的召回率仅为43.9%,这限制了许多需要感知和理解相结合的任务。本文旨在从模型设计和数据开发两个角度弥合这一感知差距。首先,我们提出了ChatRex,一种具有解耦感知设计的MLLM。它不直接让LLM预测框坐标,而是将通用提议网络输出的框输入到LLM中,允许LLM输出相应的框索引来表示其检测结果,从而将回归任务转化为LLM更擅长的基于检索的任务。在数据方面,我们构建了一个全自动的数据引擎,并构建了Rexverse-2M数据集,该数据集具有多个粒度,以支持感知和理解的联合训练。经过三阶段的训练方法,ChatRex展示了强大的感知和理解性能,并且这两种能力的结合也解锁了许多有吸引力的应用,展示了它们在MLLM中的互补作用。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLM)在视觉理解方面取得了显著进展,但其感知能力,特别是目标检测的精度,仍然不足。这限制了MLLM在需要同时进行感知和理解的任务中的应用,例如视觉问答、图像描述等。现有方法通常直接让LLM回归目标框的坐标,这对于LLM来说是一个挑战。
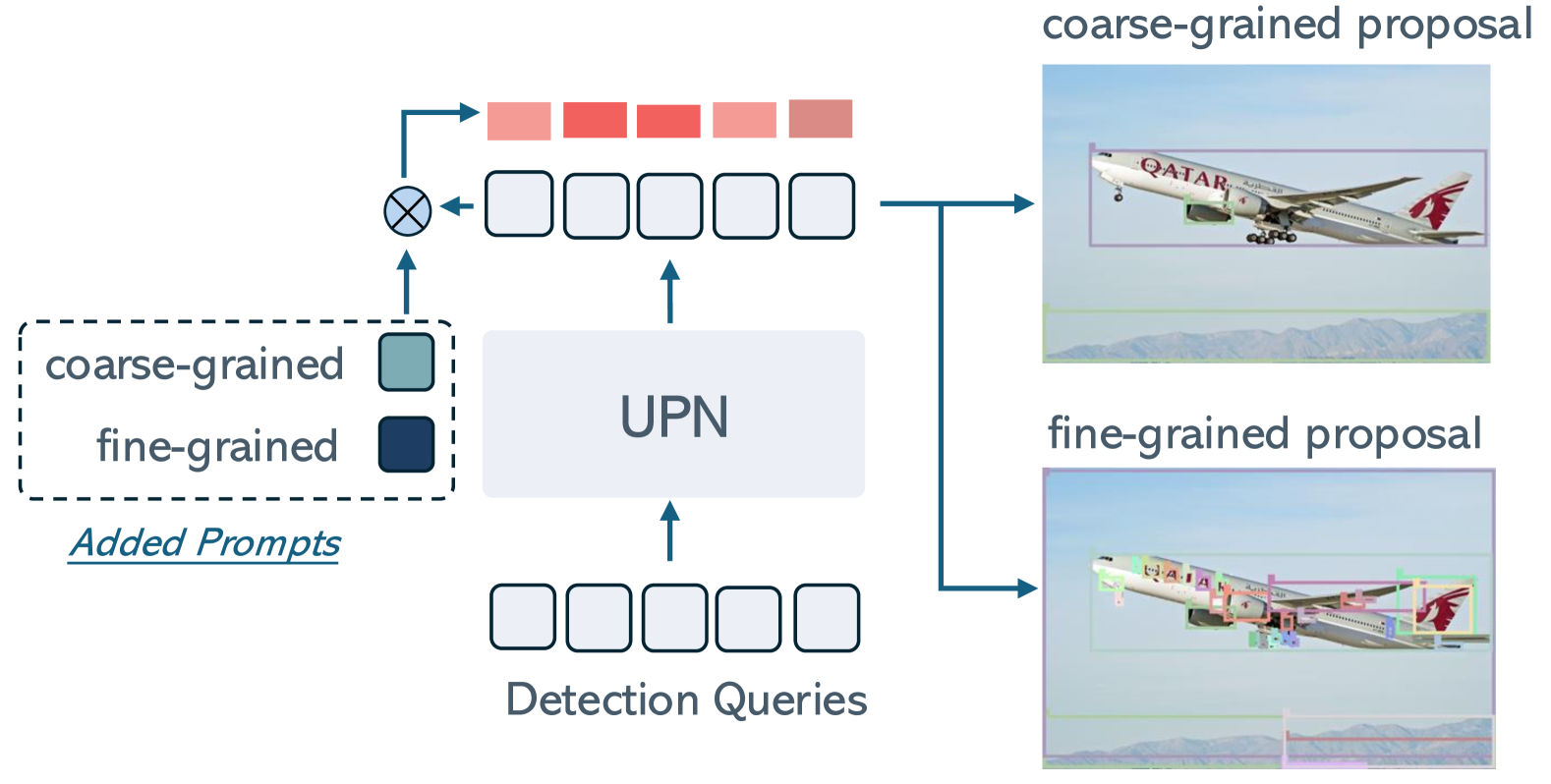
核心思路:ChatRex的核心思路是将目标检测任务从回归问题转化为检索问题。具体来说,首先使用一个独立的通用提议网络生成候选目标框,然后将这些候选框输入到LLM中,让LLM选择最合适的框的索引。这样,LLM只需要进行选择,而不是直接预测坐标,从而降低了任务的难度,提高了感知精度。
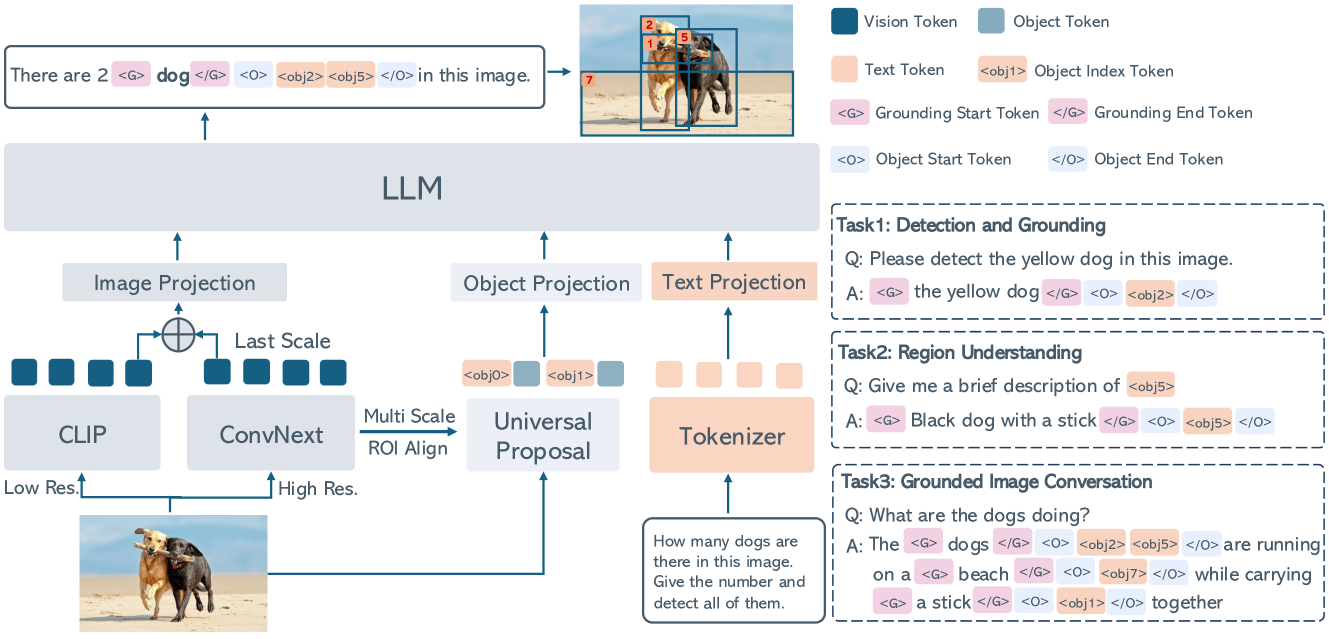
技术框架:ChatRex的整体框架包括三个主要模块:1) 通用提议网络:用于生成候选目标框;2) 多模态LLM:用于接收图像和候选框,并输出框的索引;3) 训练流程:包括三个阶段,分别是预训练、指令调优和对齐。在预训练阶段,使用大规模的图像-文本数据训练LLM的视觉理解能力。在指令调优阶段,使用包含感知和理解指令的数据集训练LLM的感知能力。在对齐阶段,使用人类反馈数据对齐LLM的输出,使其更符合人类的偏好。
关键创新:ChatRex的关键创新在于其解耦的感知设计,即将目标检测任务分解为提议生成和索引选择两个步骤。这种设计使得LLM可以专注于其擅长的任务,即理解和推理,而将目标检测的细节交给专门的提议网络。此外,Rexverse-2M数据集的构建也是一个重要的创新,它为训练MLLM的感知和理解能力提供了高质量的数据。
关键设计:在模型设计方面,ChatRex使用了Qwen2-VL作为其LLM的基础模型。在训练方面,使用了三阶段的训练方法,包括预训练、指令调优和对齐。在数据方面,Rexverse-2M数据集包含了多种粒度的数据,包括目标检测、图像描述、视觉问答等。损失函数方面,使用了交叉熵损失函数来训练LLM选择正确的框的索引。
🖼️ 关键图片

📊 实验亮点
ChatRex在COCO数据集上的目标检测召回率达到了显著提升,超过了Qwen2-VL等现有模型。此外,ChatRex在视觉问答、图像描述等任务上也表现出了强大的性能。实验结果表明,ChatRex的解耦感知设计和Rexverse-2M数据集的有效性,以及感知和理解能力结合带来的优势。
🎯 应用场景
ChatRex的潜在应用领域包括智能零售、自动驾驶、机器人导航、医疗影像分析等。通过结合精确的感知能力和强大的理解能力,ChatRex可以更好地理解周围环境,并做出更合理的决策。例如,在智能零售中,ChatRex可以识别商品并回答顾客的问题。在自动驾驶中,ChatRex可以检测交通标志和行人,并规划行驶路线。在医疗影像分析中,ChatRex可以检测病灶并生成报告。未来,ChatRex有望成为各种智能应用的核心组件。
📄 摘要(原文)
Perception and understanding are two pillars of computer vision. While multimodal large language models (MLLM) have demonstrated remarkable visual understanding capabilities, they arguably lack accurate perception abilities, e.g. the stage-of-the-art model Qwen2-VL only achieves a 43.9 recall rate on the COCO dataset, limiting many tasks requiring the combination of perception and understanding. In this work, we aim to bridge this perception gap from both model designing and data development perspectives. We first introduce ChatRex, an MLLM with a decoupled perception design. Instead of having the LLM directly predict box coordinates, we feed the output boxes from a universal proposal network into the LLM, allowing it to output the corresponding box indices to represent its detection results, turning the regression task into a retrieval-based task that LLM handles more proficiently. From the data perspective, we build a fully automated data engine and construct the Rexverse-2M dataset which possesses multiple granularities to support the joint training of perception and understanding. After a three-stage training approach, ChatRex demonstrates strong perception and understanding performance, and the combination of these two capabilities also unlocks many attractive applications, demonstrating their complementary roles in MLLM. Code is available at https://github.com/IDEA-Research/ChatRex.