HyperGLM: HyperGraph for Video Scene Graph Generation and Anticipation
作者: Trong-Thuan Nguyen, Pha Nguyen, Jackson Cothren, Alper Yilmaz, Khoa Luu
分类: cs.CV
发布日期: 2024-11-27 (更新: 2025-03-31)
💡 一句话要点
HyperGLM:利用超图增强多模态LLM,实现视频场景图生成与预测
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频场景图生成 视频场景图预测 超图 多模态LLM 视频理解
📋 核心要点
- 现有视频场景图生成方法依赖于成对连接,难以处理复杂的多对象交互和推理。
- HyperGLM通过构建统一的超图,整合实体场景图和过程图,从而促进对多路交互和高阶关系的推理。
- HyperGLM在五个视频理解任务上超越了现有最佳方法,证明了其有效建模复杂视频场景关系的能力。
📝 摘要(中文)
多模态大型语言模型(LLM)在视觉-语言任务中取得了显著进展,但仍然难以理解视频场景。为了弥合这一差距,视频场景图生成(VidSGG)应运而生,旨在捕捉视频帧中的多对象关系。然而,现有方法依赖于成对连接,限制了它们处理复杂的多对象交互和推理的能力。为此,我们提出了基于场景超图的多模态LLM(HyperGLM),以促进对多路交互和高阶关系的推理。我们的方法独特地将实体场景图(捕捉对象之间的空间关系)与过程图(建模其因果转换)集成在一起,形成统一的超图。重要的是,HyperGLM通过将这个统一的超图注入LLM来实现推理。此外,我们引入了一个新的视频场景图推理(VSGR)数据集,包含来自第三人称、自我中心和无人机视角的190万帧,并支持五个任务:场景图生成、场景图预测、视频问答、视频字幕和关系推理。实验结果表明,HyperGLM在五个任务中始终优于最先进的方法,有效地建模和推理了各种视频场景中的复杂关系。
🔬 方法详解
问题定义:论文旨在解决视频场景图生成和预测任务中,现有方法无法有效建模复杂多对象交互和高阶关系的问题。现有方法主要依赖于对象之间的成对连接,忽略了多个对象之间的协同作用和因果关系,导致对视频场景的理解不够深入。
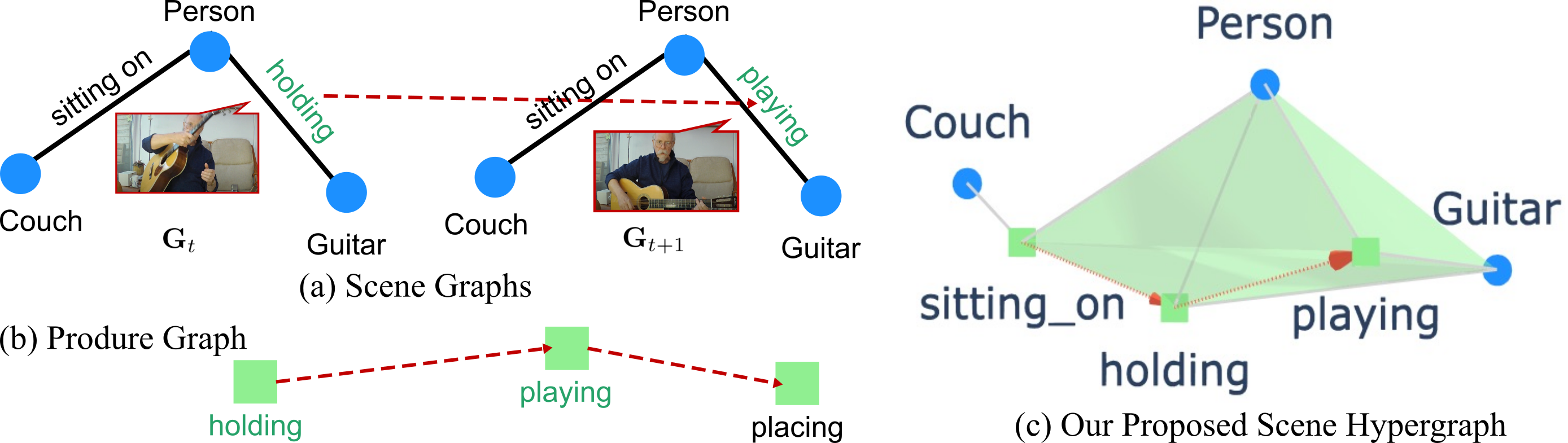
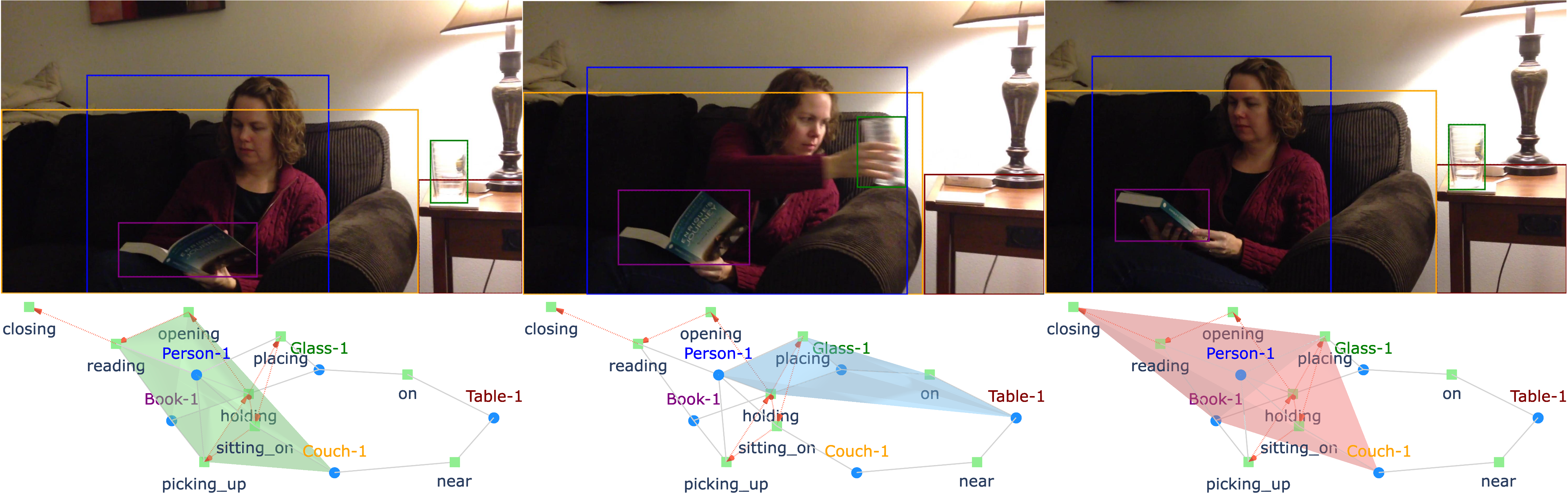
核心思路:论文的核心思路是利用超图(HyperGraph)来表示视频场景中的多对象关系。超图允许一条边连接多个节点,从而能够自然地建模多对象之间的交互。通过将实体场景图(空间关系)和过程图(因果关系)融合到超图中,可以更全面地捕捉视频场景的复杂关系。
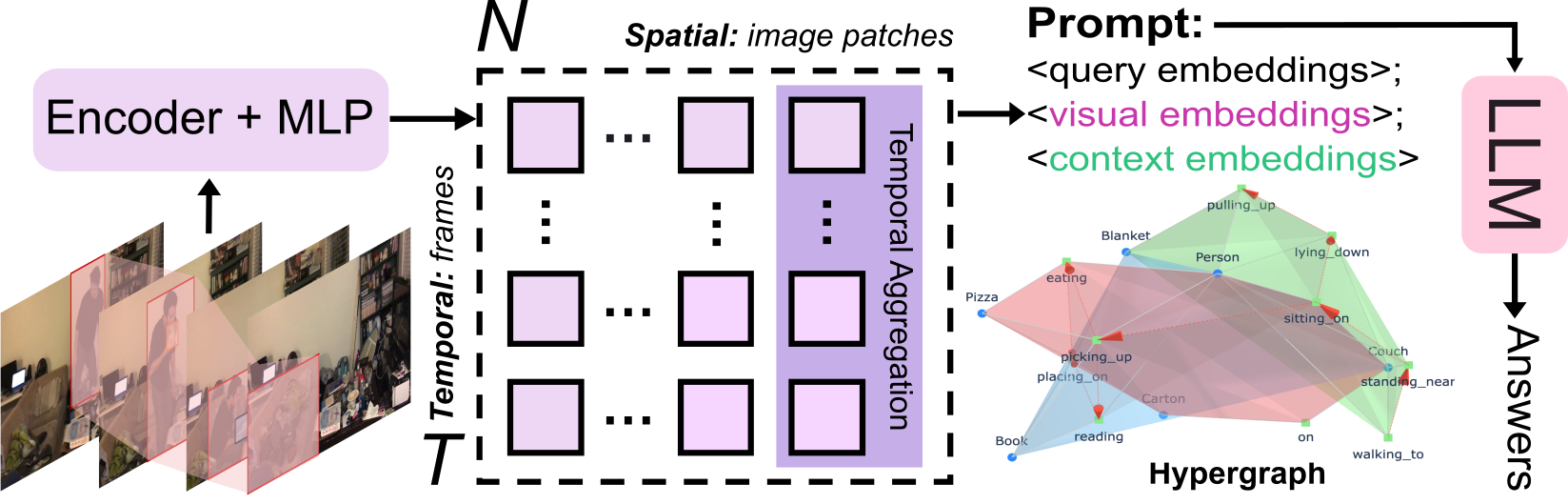
技术框架:HyperGLM的整体框架包括以下几个主要模块:1) 实体场景图构建模块,用于提取视频帧中的对象及其空间关系;2) 过程图构建模块,用于建模对象之间的因果转换关系;3) 超图构建模块,将实体场景图和过程图融合为统一的超图;4) 多模态LLM推理模块,将超图信息注入LLM,进行视频场景图生成、预测等任务。
关键创新:该论文的关键创新在于提出了基于超图的视频场景表示方法,能够有效地建模多对象之间的复杂交互和高阶关系。与现有方法相比,HyperGLM不再局限于成对连接,而是能够捕捉多个对象之间的协同作用和因果关系,从而更全面地理解视频场景。此外,将超图信息注入LLM,实现了更有效的视频理解和推理。
关键设计:论文的关键设计包括:1) 超图的构建方式,如何有效地融合实体场景图和过程图;2) 超图信息的编码方式,如何将超图信息有效地注入LLM;3) 损失函数的设计,如何优化模型以更好地学习视频场景中的复杂关系。具体的网络结构和参数设置在论文中有详细描述,但摘要中未提供。
🖼️ 关键图片
📊 实验亮点
HyperGLM在五个视频理解任务(场景图生成、场景图预测、视频问答、视频字幕和关系推理)上均取得了显著的性能提升,超越了现有最先进的方法。论文中提到使用了包含190万帧的VSGR数据集进行实验,但具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于视频监控、自动驾驶、机器人导航、智能家居等领域。通过更准确地理解视频场景,可以提升视频分析的智能化水平,例如,在视频监控中自动识别异常行为,在自动驾驶中预测行人的意图,在机器人导航中规划更合理的路径。
📄 摘要(原文)
Multimodal LLMs have advanced vision-language tasks but still struggle with understanding video scenes. To bridge this gap, Video Scene Graph Generation (VidSGG) has emerged to capture multi-object relationships across video frames. However, prior methods rely on pairwise connections, limiting their ability to handle complex multi-object interactions and reasoning. To this end, we propose Multimodal LLMs on a Scene HyperGraph (HyperGLM), promoting reasoning about multi-way interactions and higher-order relationships. Our approach uniquely integrates entity scene graphs, which capture spatial relationships between objects, with a procedural graph that models their causal transitions, forming a unified HyperGraph. Significantly, HyperGLM enables reasoning by injecting this unified HyperGraph into LLMs. Additionally, we introduce a new Video Scene Graph Reasoning (VSGR) dataset featuring 1.9M frames from third-person, egocentric, and drone views and supports five tasks: Scene Graph Generation, Scene Graph Anticipation, Video Question Answering, Video Captioning, and Relation Reasoning. Empirically, HyperGLM consistently outperforms state-of-the-art methods across five tasks, effectively modeling and reasoning complex relationships in diverse video scenes.