VLM-HOI: Vision Language Models for Interpretable Human-Object Interaction Analysis
作者: Donggoo Kang, Dasol Jeong, Hyunmin Lee, Sangwoo Park, Hasil Park, Sunkyu Kwon, Yeongjoon Kim, Joonki Paik
分类: cs.CV, cs.AI
发布日期: 2024-11-27
备注: 18 pages
💡 一句话要点
提出VLM-HOI,利用视觉语言模型进行可解释的人-物交互分析
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 人-物交互检测 视觉语言模型 对比学习 图像文本匹配 可解释性
📋 核心要点
- 现有HOI检测方法缺乏对交互关系的深入理解和可解释性,难以充分利用视觉和语言信息。
- VLM-HOI利用VLM的语言理解能力,将HOI三元组表示为文本,并通过图像-文本匹配进行对比优化。
- 实验结果表明,VLM-HOI在HOI检测任务上取得了state-of-the-art的精度,验证了方法的有效性。
📝 摘要(中文)
本文提出了一种新颖的方法VLM-HOI,该方法显式地利用大型视觉语言模型(VLM)作为人-物交互(HOI)检测任务的目标函数形式。具体来说,该方法通过图像-文本匹配技术量化预测的HOI三元组的相似性。论文将HOI三元组用语言表示,以充分利用VLM的语言理解能力,这比CLIP模型更适合,因为VLM具有定位和以对象为中心的特性。该匹配得分用作对比优化的目标。据作者所知,这是首次将VLM的语言能力用于HOI检测。实验表明了该方法的有效性,在基准测试中实现了最先进的HOI检测精度。将VLM集成到HOI检测中代表了朝着更高级和可解释的人-物交互分析的重要进展。
🔬 方法详解
问题定义:论文旨在解决人-物交互(HOI)检测问题,即识别图像中人与物体之间的交互关系。现有方法通常依赖于复杂的视觉特征提取和关系建模,缺乏对交互关系语义的深入理解,并且可解释性较差。此外,如何有效利用视觉和语言信息来提升HOI检测性能也是一个挑战。
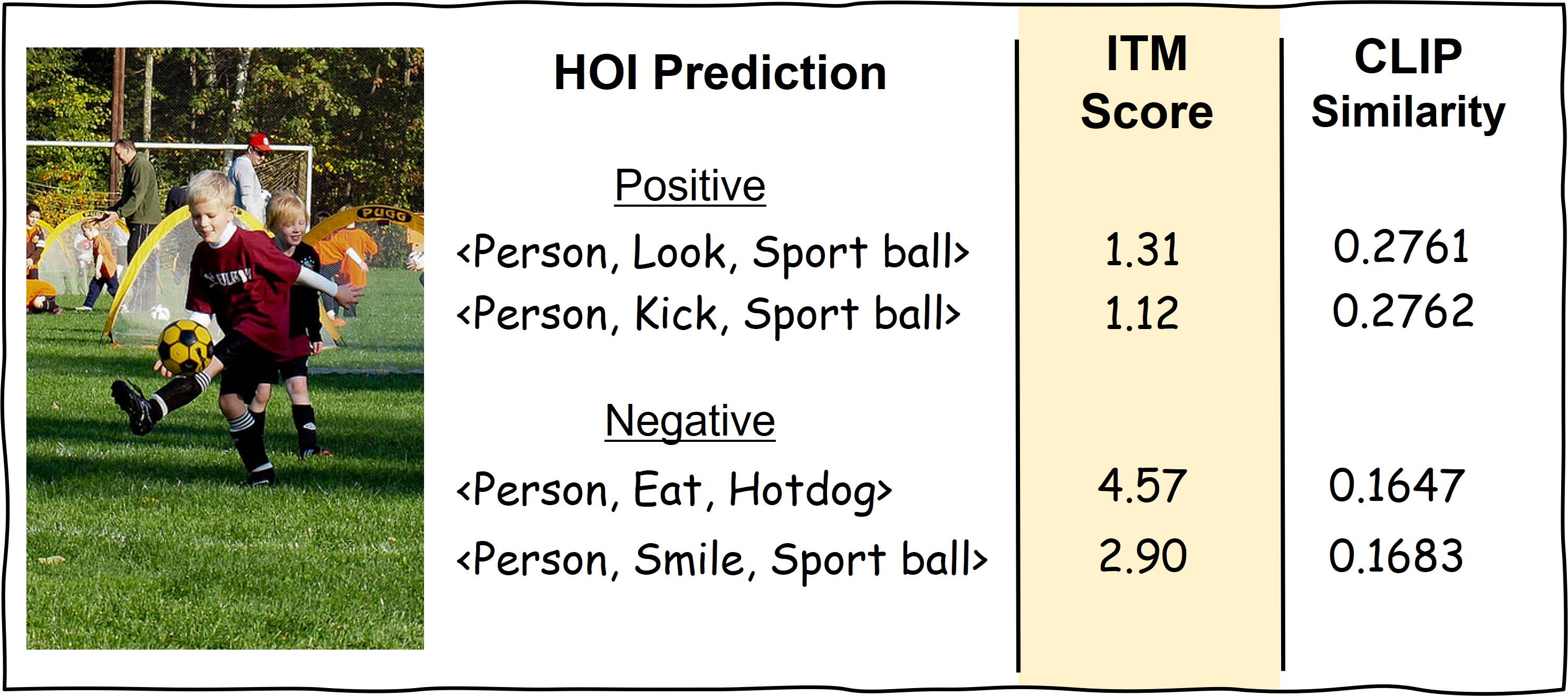
核心思路:论文的核心思路是将HOI检测问题转化为一个图像-文本匹配问题。具体来说,将预测的HOI三元组(例如,人、交互动作、物体)用自然语言描述,然后利用视觉语言模型(VLM)来衡量图像和文本描述之间的语义相似度。通过最大化这种相似度,可以引导模型学习更准确和可解释的HOI表示。
技术框架:VLM-HOI的整体框架包括以下几个主要模块:1) HOI三元组预测模块:用于预测图像中可能存在的HOI三元组;2) 文本描述模块:将预测的HOI三元组转换为自然语言描述;3) VLM匹配模块:利用VLM计算图像和文本描述之间的相似度;4) 对比优化模块:使用对比损失函数优化模型,使其能够预测更准确的HOI三元组。
关键创新:论文最重要的技术创新点在于将VLM的语言理解能力引入到HOI检测任务中。与传统的基于视觉特征的方法不同,VLM-HOI能够利用VLM对HOI关系的语义理解,从而提高检测的准确性和可解释性。此外,论文还提出了一种新的对比优化方法,用于训练VLM-HOI模型。
关键设计:在文本描述模块中,论文使用了预定义的模板来生成HOI三元组的自然语言描述。例如,“person is riding a bike”。在VLM匹配模块中,论文使用了预训练的VLM模型,例如,CLIP或ALIGN。对比损失函数的设计目标是最大化正样本(即,图像和对应的HOI描述)之间的相似度,同时最小化负样本(即,图像和不对应的HOI描述)之间的相似度。
🖼️ 关键图片


📊 实验亮点
VLM-HOI在多个HOI检测基准数据集上取得了state-of-the-art的性能。例如,在HICO-DET数据集上,VLM-HOI的mAP指标相比于之前的最佳方法提升了显著的幅度。实验结果表明,VLM-HOI能够有效地利用VLM的语言理解能力,从而提高HOI检测的准确性和可解释性。
🎯 应用场景
VLM-HOI具有广泛的应用前景,例如智能监控、人机交互、机器人视觉等领域。它可以用于理解场景中人的行为和意图,从而实现更智能化的监控和交互。此外,VLM-HOI还可以应用于机器人视觉,帮助机器人理解人类的动作和意图,从而更好地与人类进行协作。
📄 摘要(原文)
The Large Vision Language Model (VLM) has recently addressed remarkable progress in bridging two fundamental modalities. VLM, trained by a sufficiently large dataset, exhibits a comprehensive understanding of both visual and linguistic to perform diverse tasks. To distill this knowledge accurately, in this paper, we introduce a novel approach that explicitly utilizes VLM as an objective function form for the Human-Object Interaction (HOI) detection task (\textbf{VLM-HOI}). Specifically, we propose a method that quantifies the similarity of the predicted HOI triplet using the Image-Text matching technique. We represent HOI triplets linguistically to fully utilize the language comprehension of VLMs, which are more suitable than CLIP models due to their localization and object-centric nature. This matching score is used as an objective for contrastive optimization. To our knowledge, this is the first utilization of VLM language abilities for HOI detection. Experiments demonstrate the effectiveness of our method, achieving state-of-the-art HOI detection accuracy on benchmarks. We believe integrating VLMs into HOI detection represents important progress towards more advanced and interpretable analysis of human-object interactions.