Self-supervised Monocular Depth and Pose Estimation for Endoscopy with Generative Latent Priors
作者: Ziang Xu, Bin Li, Yang Hu, Chenyu Zhang, James East, Sharib Ali, Jens Rittscher
分类: cs.CV, cs.AI
发布日期: 2024-11-26 (更新: 2024-12-09)
💡 一句话要点
提出基于生成隐变量先验的内窥镜自监督单目深度与姿态估计方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 单目深度估计 姿态估计 内窥镜 生成模型
📋 核心要点
- 内窥镜系统的单目特性和现有方法对合成数据集的依赖,导致深度和姿态估计在内窥镜复杂环境中泛化性不足。
- 论文提出利用生成隐变量库和变分自编码器,分别增强深度预测的真实性和姿态估计的稳定性,从而提升整体性能。
- 在SimCol和EndoSLAM数据集上的实验表明,该框架在内窥镜深度和姿态估计方面优于现有的自监督方法。
📝 摘要(中文)
本文提出了一种鲁棒的自监督单目深度和姿态估计框架,用于内窥镜应用。该框架结合了生成隐变量库和变分自编码器(VAE)。生成隐变量库利用来自自然图像的大量深度场景来调节深度网络,通过隐特征先验增强深度预测的真实性和鲁棒性。对于姿态估计,将其重新构建在VAE框架内,将姿态转换视为隐变量,以规范尺度,稳定z轴突出性,并提高x-y敏感性。这种双重优化流程能够实现准确的深度和姿态预测,有效应对胃肠道复杂纹理和光照条件。在SimCol和EndoSLAM数据集上的大量评估证实,我们的框架在内窥镜深度和姿态估计方面优于已发表的自监督方法。
🔬 方法详解
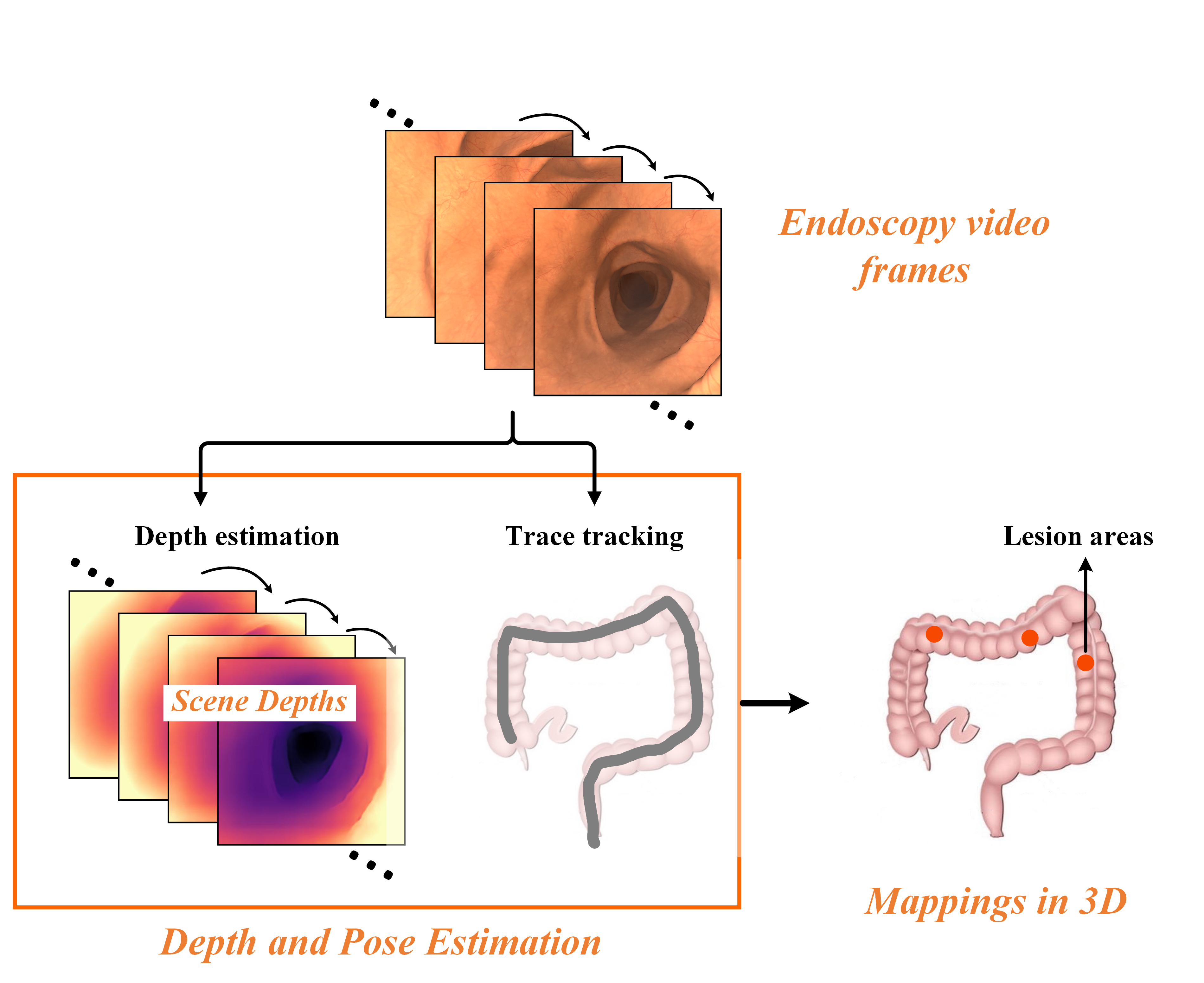
问题定义:内窥镜的单目深度和姿态估计是实现胃肠道内病灶三维重建的关键。现有自监督方法依赖合成数据或复杂模型,难以适应内窥镜图像中复杂的光照、纹理变化以及缺乏结构信息的挑战,导致泛化能力不足。
核心思路:论文的核心在于利用生成模型学习到的先验知识来约束深度和姿态估计。具体来说,利用自然图像的深度信息作为深度估计的先验,并利用VAE框架将姿态估计建模为隐变量推断问题,从而提高估计的准确性和鲁棒性。这种设计旨在克服内窥镜图像的特殊挑战,并提升模型的泛化能力。
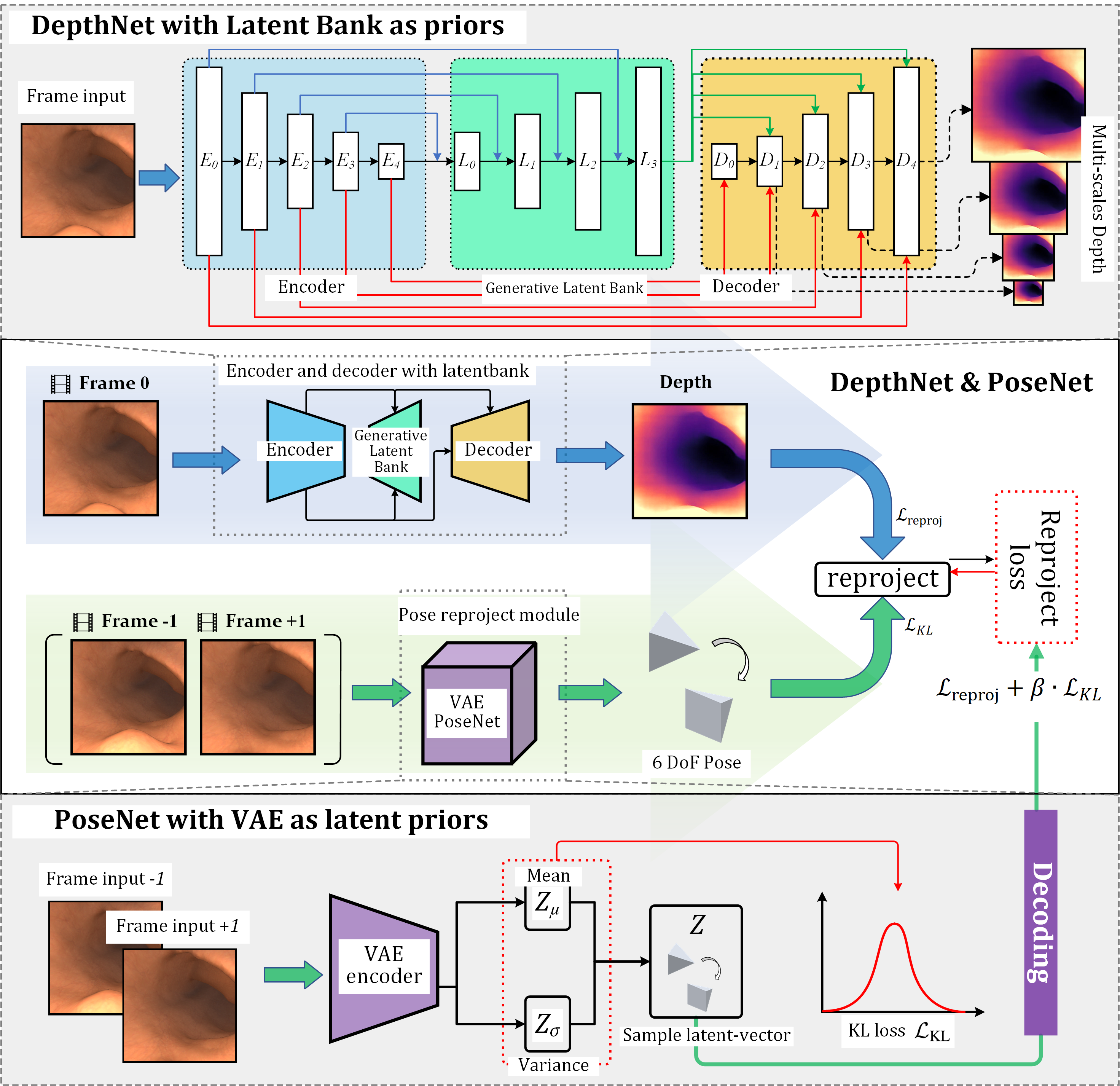
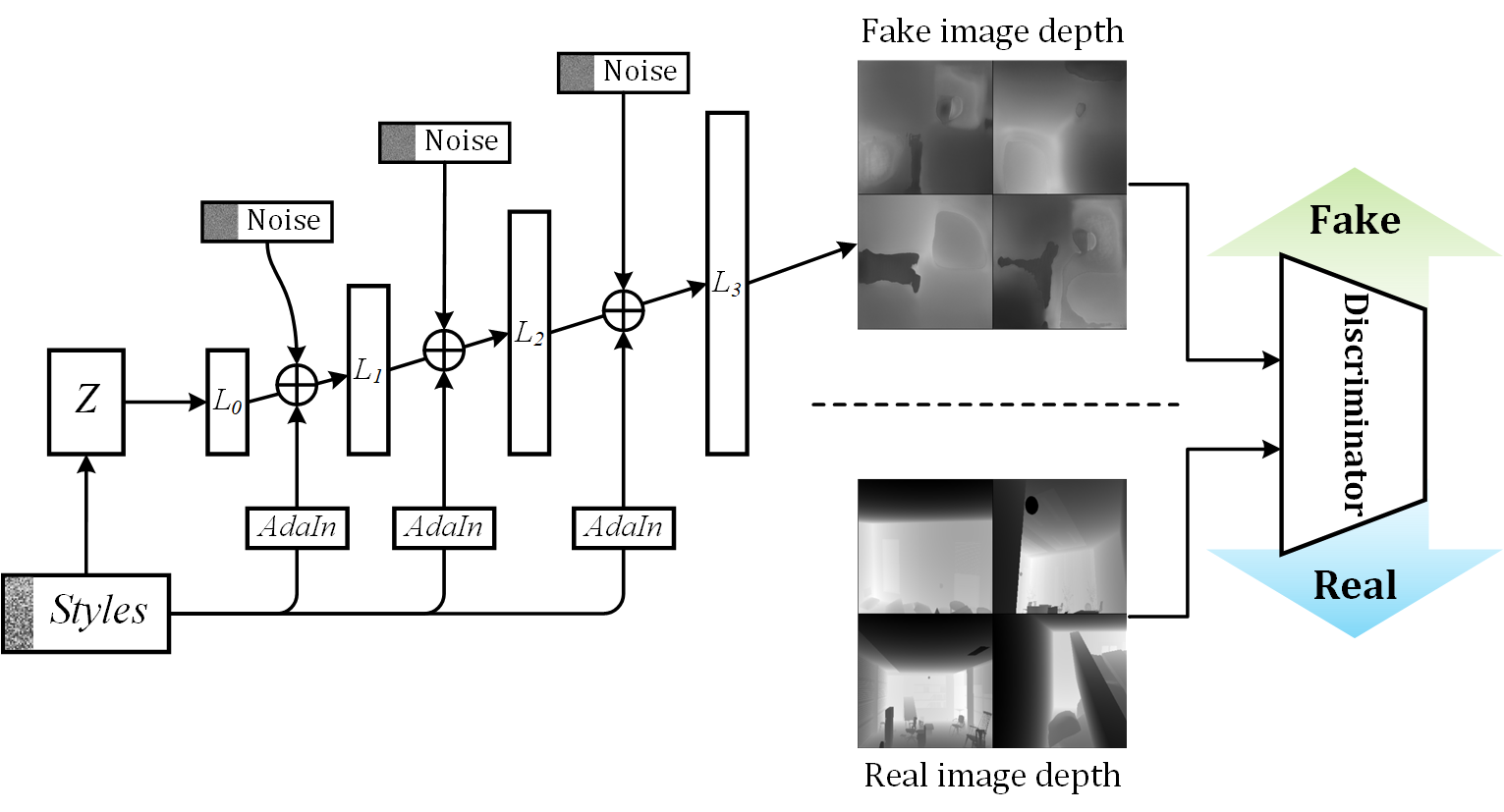
技术框架:整体框架包含两个主要模块:深度估计模块和姿态估计模块。深度估计模块利用生成隐变量库(Generative Latent Bank)来提供深度先验,姿态估计模块则基于变分自编码器(VAE)进行姿态转换的建模。这两个模块共同构成一个自监督的训练流程,通过最小化图像重建误差来学习深度和姿态。
关键创新:主要的创新点在于将生成模型与自监督深度和姿态估计相结合。生成隐变量库能够提供更真实的深度先验,而VAE框架则能够更好地建模姿态转换的不确定性,从而提高估计的准确性和鲁棒性。此外,将姿态估计问题转化为隐变量推断问题,能够有效解决尺度模糊和z轴不确定性等问题。
关键设计:深度估计模块使用生成隐变量库来调节深度网络的输出,通过最小化深度预测与真实深度之间的差异来学习深度先验。姿态估计模块则使用VAE来建模姿态转换,通过最小化图像重建误差和KL散度来学习姿态的隐变量表示。损失函数包括图像重建损失、深度一致性损失和KL散度损失等。网络结构方面,深度估计网络可以采用常见的深度估计网络结构,如ResNet等,而VAE则采用编码器-解码器结构。
🖼️ 关键图片
📊 实验亮点
论文在SimCol和EndoSLAM数据集上进行了实验,结果表明,该方法在深度和姿态估计方面均优于现有的自监督方法。具体来说,在深度估计方面,该方法能够显著降低深度误差,提高深度预测的准确性。在姿态估计方面,该方法能够更准确地估计相机的运动轨迹,提高姿态估计的鲁棒性。实验结果验证了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于内窥镜引导的机器人手术、病灶的三维重建与体积测量、以及虚拟内窥镜导航等领域。通过提供准确的深度和姿态信息,医生可以更精确地定位病灶,进行更有效的治疗,并减少手术风险。未来,该技术有望进一步推广到其他医学影像领域,如腹腔镜手术等。
📄 摘要(原文)
Accurate 3D mapping in endoscopy enables quantitative, holistic lesion characterization within the gastrointestinal (GI) tract, requiring reliable depth and pose estimation. However, endoscopy systems are monocular, and existing methods relying on synthetic datasets or complex models often lack generalizability in challenging endoscopic conditions. We propose a robust self-supervised monocular depth and pose estimation framework that incorporates a Generative Latent Bank and a Variational Autoencoder (VAE). The Generative Latent Bank leverages extensive depth scenes from natural images to condition the depth network, enhancing realism and robustness of depth predictions through latent feature priors. For pose estimation, we reformulate it within a VAE framework, treating pose transitions as latent variables to regularize scale, stabilize z-axis prominence, and improve x-y sensitivity. This dual refinement pipeline enables accurate depth and pose predictions, effectively addressing the GI tract's complex textures and lighting. Extensive evaluations on SimCol and EndoSLAM datasets confirm our framework's superior performance over published self-supervised methods in endoscopic depth and pose estimation.